Clear Sky Science · ru
Сиамская архитектура CNN-RNN с многоуровневой агрегацией для восстановления личности по видео
Почему важно отслеживать людей между камерами
Современные города покрыты камерами, но эти камеры редко «общаются» друг с другом. Когда человек переходит от одного уголка улицы к станции, разные камеры видят его под разными углами, при разном освещении и часто сквозь толпу. Автоматическое сопоставление того, что это один и тот же человек в разных видеоклипах — задача, называемая восстановлением личности по видео — может помочь следователям проследить перемещения после инцидента, поддержать поиски пропавших или обеспечить аналитические функции в оживленных общественных местах. Но выполнять эту задачу точно и эффективно, особенно на скромном оборудовании, — серьёзный технический вызов.
Проще мозг для сопоставления людей в движении
В работе представлена компактная система искусственного интеллекта, предназначенная для определения того, показывают ли два коротких видеоклипа одного и того же человека. Вместо современных тенденций к очень глубоким или трансформерным сетям авторы опираются на более экономичную схему, сочетающую два классических компонента: сверточную сеть для анализа каждого кадра и блочный рекуррентный элемент — GRU — для отслеживания изменений внешности во времени. Эти два блока организованы в сиамскую конфигурацию — по сути, две копии одной и той же сети с общими настройками. Каждая копия обрабатывает одну последовательность кадров, и система учится выдавать похожие внутренние представления для клипов одного человека и различающиеся представления для разных людей.
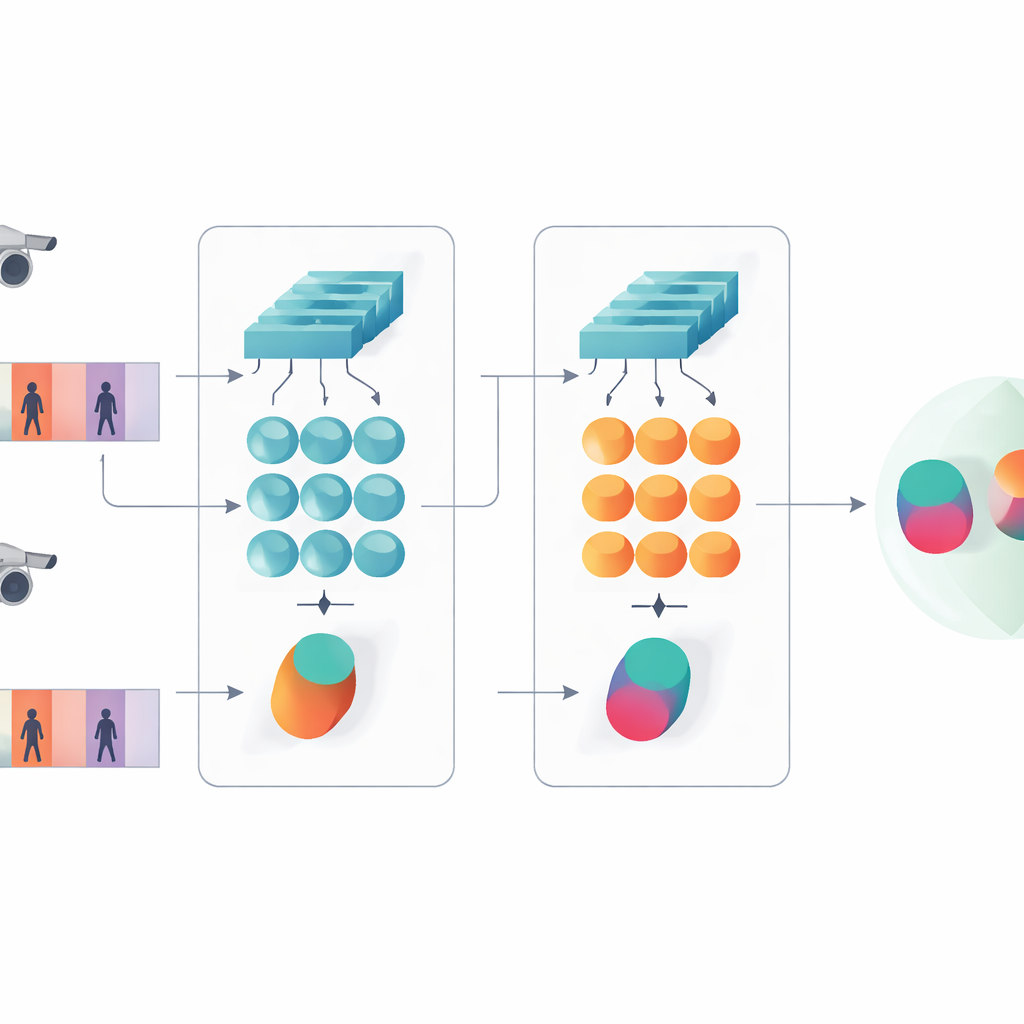
Видеть и детали, и временные закономерности
Ключевая идея исследования в том, что распознавание не должно опираться только на самые глубокие, абстрактные признаки сети. Более ранние слои сохраняют чёткие визуальные детали — структуру ткани куртки, полосы на брюках или силуэт рюкзака — подсказки, которые часто сохраняются при изменении угла съёмки. Предложенная модель поэтому сохраняет два уровня описания. Одна ветвь усредняет признаки ранних слоёв по всем кадрам, суммируя мелкие текстуры и локальные паттерны. Другая ветвь передаёт признаки высших слоёв в GRU, который проходит по последовательности кадр за кадром и затем усредняет свои внутренние состояния по времени. Этот шаг усреднения предотвращает избыточный акцент на последних кадрах и формирует консенсусное представление о внешности и движениях человека в течение всего клипа.
Обучение «близнецов» согласовываться и классифицировать
Чтобы научить систему тому, что имеет значение, авторы комбинируют две учебные цели. Во-первых, задача верификации побуждает сиамские ветви выдавать близкие представления для видео одного человека и удалённые — для разных людей. Во-вторых, задача классификации заставляет сеть назначать каждый тренировочный клип конкретной идентичности. Оптимизируя обе цели одновременно и на низком, и на высоком уровнях признаков, модель учится внутренним описаниям, которые не только различают людей, но и устойчивы к шуму, частичным закрытиям и иногда некачественным кадрам. Архитектура остаётся неглубокой по числу слоёв и параметров, что помогает избежать переобучения на относительно небольших видеонаборах данных.
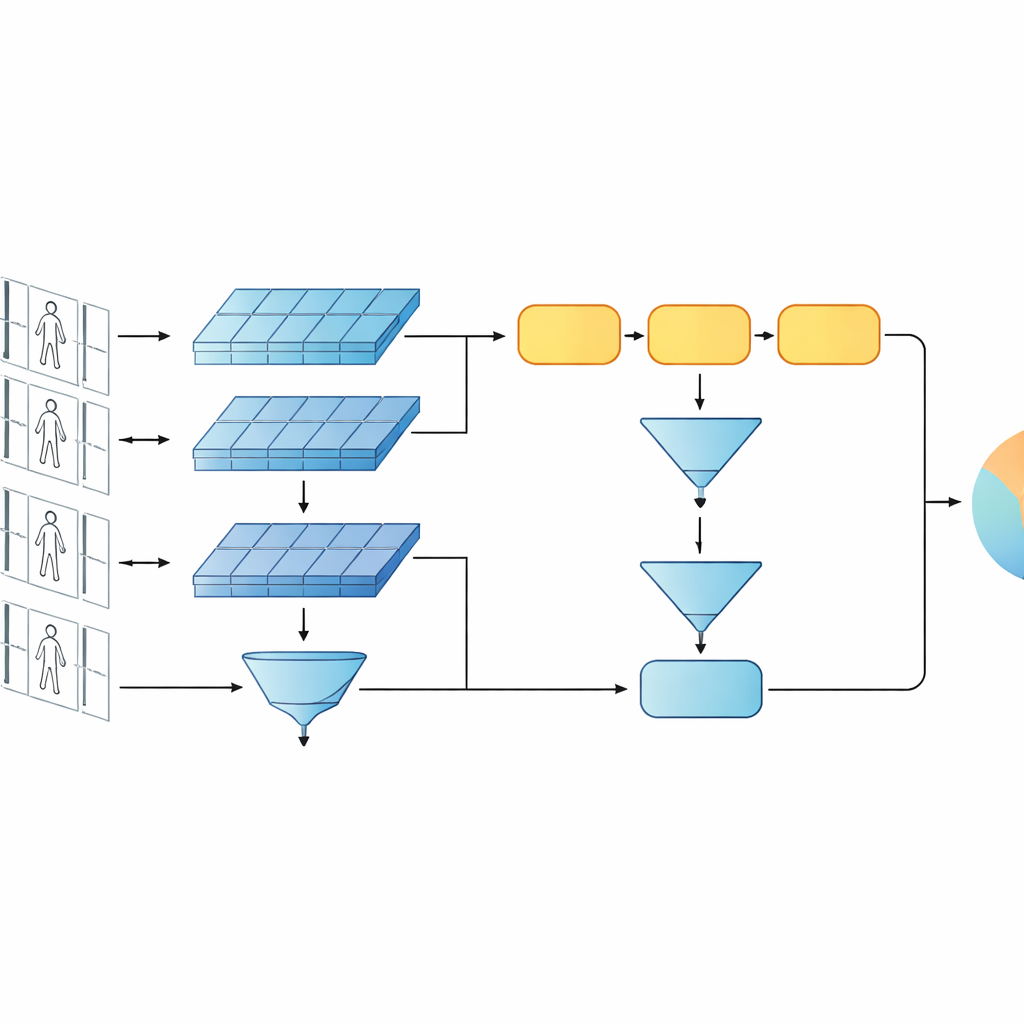
Тестирование на видео в стиле наблюдения
Фреймворк оценивали на двух широко используемых видеобенчмарках — PRID-2011 и iLIDS-VID — которые содержат короткие сцены ходьбы сотен людей, снятых парами разъединённых камер. Исследование внимательно проверяет разные проектные решения: замену GRU другими рекуррентными блоками, изменение числа рекуррентных слоёв, способы агрегации признаков по времени и включение или отключение низко- и высокоуровневых ветвей. Во всех этих тестах однослойный GRU с усреднением и полная многоуровневая схема стабильно дают лучшую точность. Модель сопоставима или превосходит многие более сложные рекуррентные и сиамские системы и конкурирует с некоторыми архитектурами с механизмами внимания, при этом требуя значительно меньше параметров и вычислений.
Эффективность для реального развертывания
Помимо точности, работа подчёркивает практическую применимость. Вся сеть содержит примерно от одного до двух миллионов обучаемых параметров — на порядки меньше популярных глубоких residual- или трансформерных бэкендов — и требует лишь доли их вычислительных ресурсов на кадр. Это делает её более подходящей для развертывания на устройствах с ограниченной памятью и вычислительной мощностью, таких как edge-серверы рядом с камерами. Эксперименты также показывают, что более длинные галерейные последовательности, когда система видит больше кадров каждого сохранённого человека, значительно улучшают распознавание, хотя и увеличивают затраты на обработку линейно. Авторы утверждают, что такие компактные, продуманно спроектированные архитектуры способны обеспечить надёжное восстановление личности по видео без высокой «цены» лучших современных моделей.
Что это значит для повседневных систем наблюдения
Проще говоря, в статье показано, что умный дизайн может превзойти простое увеличение размеров: сочетая неглубокий анализ изображения, лёгкое моделирование последовательностей и двухуровневый взгляд на визуальное сходство, можно с высокой надёжностью отслеживать, кто есть кто, между камерами, сохраняя модель маленькой и быстрой. Для будущих систем, которые должны работать на множестве камер при жёстких аппаратных и энергетических ограничениях, такой эффективный многоуровневый подход может помочь внедрить более мощную и ответственную видеоаналитику в реальном мире.
Цитирование: Wang, YK., Pan, TM. & Sun, CP. A CNN-RNN Siamese framework with multi-level aggregation for video-based person re-identification. Sci Rep 16, 8224 (2026). https://doi.org/10.1038/s41598-026-39277-x
Ключевые слова: восстановление личности, видеонаблюдение, сиамские нейронные сети, временное моделирование, эффективное глубокое обучение