Clear Sky Science · ru
Надежная система преобразования текста на естественном языке в SQL с динамическими стратегиями на основе LLM
Преобразование повседневных вопросов в ответы из базы данных
Современные организации утопают в данных, но большинство людей не владеют техническим языком, необходимым для их запроса. В этой статье представлен TriSQL — система, которая позволяет пользователям задавать вопросы простым языком и автоматически преобразует их в точные команды для базы данных. Тщательно управляя тем, как большие языковые модели справляются со сложностью, эта архитектура стремится сделать доступ к данным более точным и надежным, даже для самых сложных вопросов.
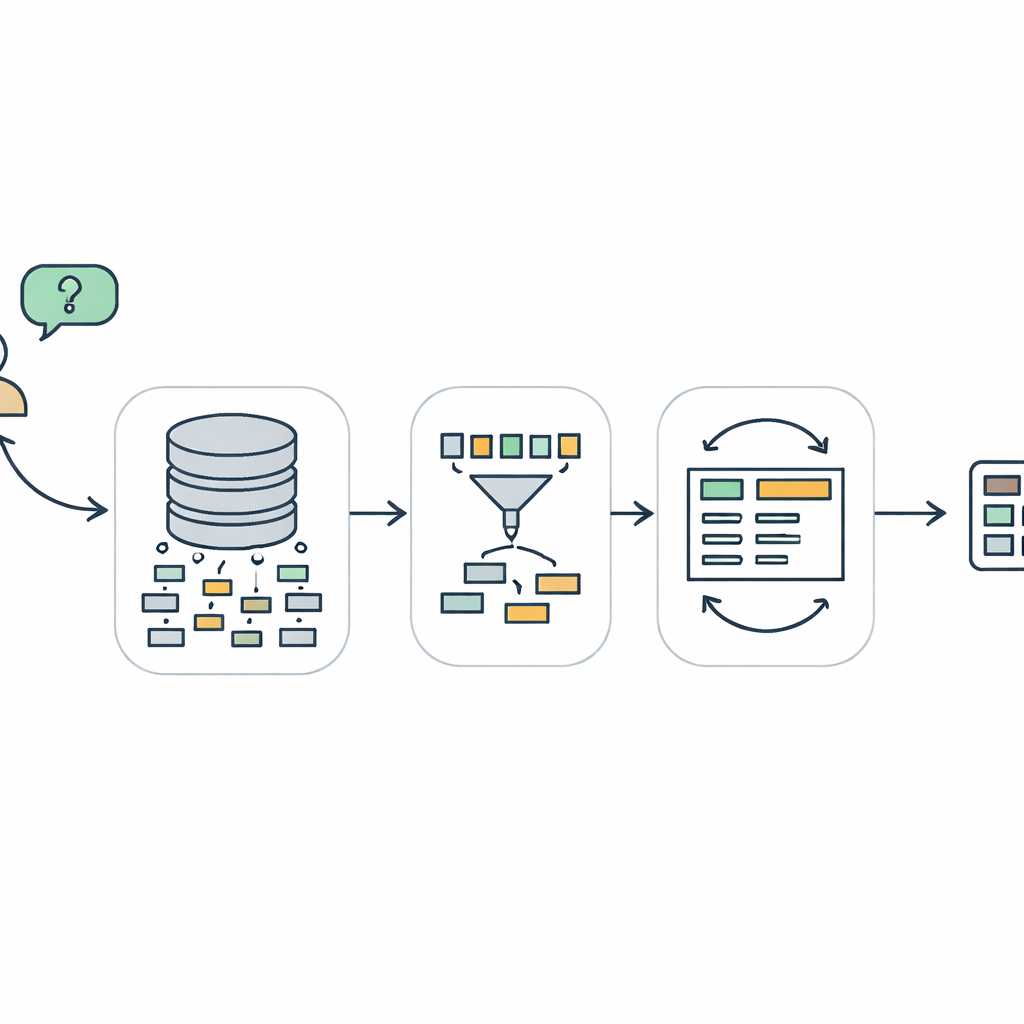
Почему общение с базами данных так сложно
Когда кто‑то вводит вопрос вроде «Какие клиенты купили более пяти товаров в прошлом месяце?», компьютер должен перевести это в SQL — специализированный язык, используемый большинством баз данных. Эта задача, называемая text-to-SQL, кажется простой, но на деле оказывается удивительно трудной. Система должна понять намерение пользователя, найти нужные таблицы и столбцы в порой огромной и неструктурированной схеме, а затем построить запрос, который будет и синтаксически корректен, и верно отражать исходный запрос. Ранее предложенные решения, в том числе на базе больших языковых моделей, часто дают сбои, когда вопросы подразумевают множество таблиц, вложенную логику или тонкие условия. Они могут сгенерировать запросы, похожие на правильные, но которые либо не выполняются, либо возвращают неверные результаты при исполнении.
Трехэтапный путь от вопроса к запросу
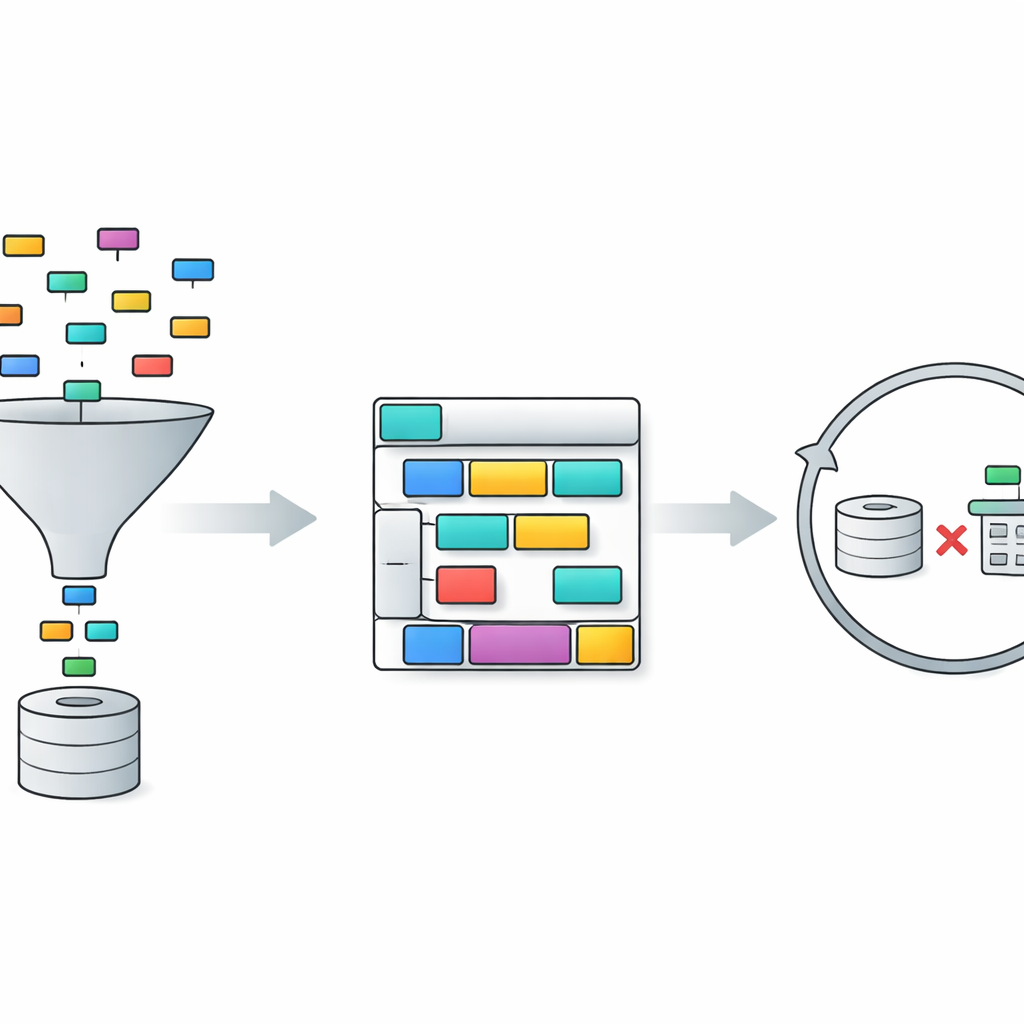
TriSQL решает эти проблемы с помощью конвейера из трех этапов. Сначала селектор, ориентированный на вопрос, анализирует слова пользователя и полную структуру базы данных и определяет, какие таблицы и столбцы действительно релевантны. Вместо того чтобы слепо показывать языковой модели всю схему, он сужает видимую область до нужных фрагментов. Затем генератор, учитывающий структуру, планирует форму SQL-запроса прежде чем заполнять детали. Он сначала набрасывает высокоуровневый каркас — какие клаузулы нужны и как они взаимосвязаны — а затем вставляет конкретные таблицы, соединения и условия. Такой подход «сначала структура, потом содержимое» помогает сохранить жесткую грамматику SQL, особенно для длинных и запутанных запросов. Наконец, усовершенствователь, учитывающий сложность, проверяет и улучшает первоначальный запрос, применяя разные стратегии в зависимости от того, насколько сложным кажется вопрос.
Адаптация усилий к сложности вопроса
Стадия уточнения — это то место, где TriSQL особенно новаторски использует большие языковые модели. Система оценивает сложность каждого вопроса и чернового запроса, учитывая такие факторы, как количество объединяемых таблиц, глубина вложенности и типы используемых ограничений. Для простых случаев она применяет лишь легкие исправления, например исправляет небольшие синтаксические ошибки. Для средних случаев реорганизует клаузулы и убеждается, что запрос соответствует выбранной схеме. Для самых требовательных задач она привлекает языковую модель для более глубокого рассуждения, иногда разлагая проблему на подзадачи и выполняя альтернативные запросы. Существенно, что TriSQL затем исполняет как исходный, так и уточненный запросы в базе данных и использует их поведение — выполняются ли они, сколько времени занимают и что возвращают — чтобы решить, какую версию оставить или стоит ли попытаться провести ещё один раунд уточнений.
Испытание системы
Чтобы оценить эффективность TriSQL, авторы тестируют систему на широко используемом бенчмарке Spider, а также на нескольких более сложных вариантах, которые вводят предметные знания, необычные синтаксические конструкции и более реалистичную структуру запросов. Они измеряют два показателя: точное совпадение (exact match), которое проверяет, совпадает ли сгенерированная строка SQL с эталонной, написанной человеком, и точность выполнения (execution accuracy), которая проверяет, даёт ли запрос правильный ответ при запуске. По этим наборам данных TriSQL достигает самой высокой на данный момент точности выполнения, сохраняя при этом конкурентный показатель точного совпадения по сравнению с лучшими предыдущими системами. Он также более устойчив: по мере усложнения вопросов производительность TriSQL падает гораздо более плавно, чем у конкурирующих методов. Дополнительные эксперименты на реальной базе данных управления энергосетью показывают, что та же архитектура справляется не только с выборкой данных, но и с операциями insert, update, delete и созданием таблиц. Пилотные адаптации к графовым базам (Cypher) и пайплайнам MongoDB указывают, что трехэтапный дизайн может выходить за рамки классического SQL.
Что это означает для повседневного использования данных
Проще говоря, эта работа приближает нас к миру, где люди смогут общаться со сложными базами данных так же легко, как сейчас общаются с поисковыми системами. За счет тщательного выбора релевантных частей схемы, планирования структуры запроса перед заполнением деталей и адаптации использования больших языковых моделей к сложности каждого вопроса, TriSQL порождает запросы, которые с большей вероятностью корректно выполнятся и вернут ожидаемые результаты. Хотя остаются задачи — например, работа с неоднозначными вопросами и незнакомыми базами данных — исследование показывает, что продуманная, поэтапная архитектура может сделать интерфейсы на естественном языке к данным и более мощными, и более предсказуемыми для повседневных пользователей.
Цитирование: Su, X., Gu, Y., Wang, P. et al. A robust natural language text-to-SQL generation framework with dynamic strategies based on LLMs. Sci Rep 16, 7892 (2026). https://doi.org/10.1038/s41598-026-39128-9
Ключевые слова: text-to-SQL, интерфейсы на естественном языке, запросы к базам данных, большие языковые модели, устойчивость запросов