Clear Sky Science · ru
Подход к работе с несбалансированными наборами данных с помощью сдвига границы
Почему редкие случаи важны в повседневных данных
От банковского мошенничества и медицинской диагностики до прогнозирования оттока клиентов — многие задачи, которые мы просим компьютеры решать, зависят от выявления редких, но критичных событий. В большинстве реальных наборов данных такие важные случаи значительно уступают по численности обычным. Модель, которая в основном видит «обычную ситуацию», может потерять способность распознавать именно те ситуации, которые нас чаще всего интересуют. В этой статье предлагается новый способ уравновешивания сильно скошенных данных, чтобы алгоритмы обучения уделяли должное внимание редким, но значимым случаям.
Скрытая ловушка перекошенных данных
Когда один тип примеров значительно превосходит другой по числу, стандартные методы машинного обучения склонны ориентироваться на большинство и незаметно пренебрегать меньшинством. Система прогнозирования оттока, например, может помечать почти всех как лояльных клиентов и при этом показывать высокую точность просто потому, что фактических уходящих очень мало. Похожие проблемы возникают при обнаружении аварий, мониторинге мошенничества и скрининге в медицине, где положительные случаи редки, но их пропуск дорого обходится. Традиционные способы исправления этой ситуации делятся на два подхода: изменить алгоритм обучения так, чтобы он «больше заботился» о меньшинстве, или трансформировать сами данные — либо удаляя часть примеров большинства (undersampling), либо создавая дополнительные примеры меньшинства (oversampling). Популярные инструменты повышения выборки, такие как SMOTE, генерируют синтетические примеры меньшинства, но они могут непреднамеренно загромождать деликатную пограничную область, где классы пересекаются.
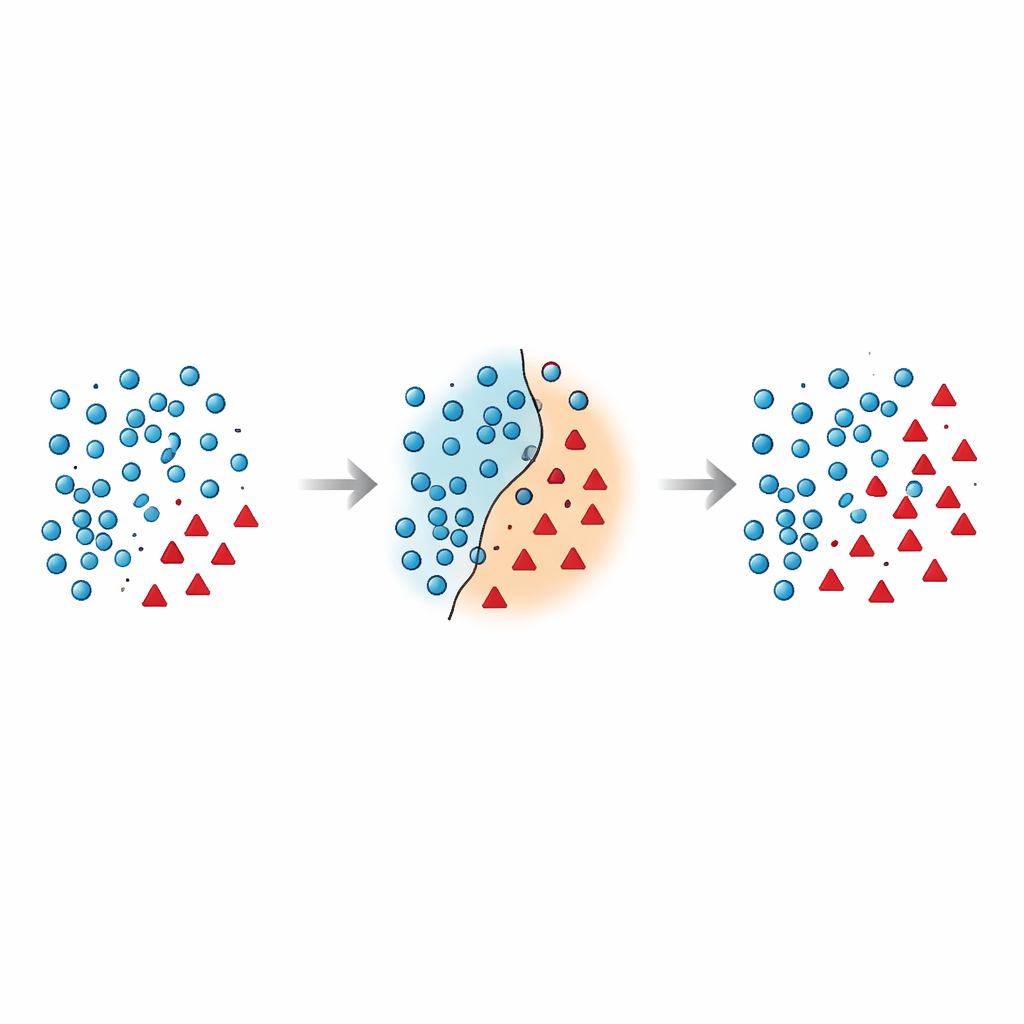
Почему граница между группами так уязвима
Авторы утверждают, что наиболее опасные ошибки происходят вблизи границы решений — в зоне, где случаи большинства и меньшинства перекрываются в пространстве признаков. Многие существующие методы либо добавляют синтетические точки в эту рискованную область, не убирая мусор, либо агрессивно удаляют данные и случайно избавляются от информативных примеров. Недавние исследования пытались смягчить проблему с помощью геометрических ограничений, оценок локальной плотности или фильтров шума, однако большинство методов по‑прежнему рассматривают точки меньшинства на месте и редко переосмысливают, как следует обрабатывать точки большинства у границы. В результате остаётся стойкая проблема: перекрывающиеся и зашумлённые образцы сбивают классификатор с толку и приводят к нестабильным предсказаниям, особенно на новых данных.
Двухэтапный способ упорядочить границу
В статье представлен метод Borderline Shifting Oversampling (BSO) — двухфазный подход к преобразованию данных, который целенаправленно нацелен на проблемную пограничную область. Сначала он сканирует окружение каждого примера большинства, чтобы решить, находится ли он в безопасной зоне, на границе или явно в неправильном месте (шум). Точки большинства, окружённые соседями из меньшинства, либо реклассифицируются в сторону меньшинства, либо помечаются как шум и удаляются, что эффективно очищает и сдвигает границу, делая её более соответствующей скрытой структуре. На втором этапе метод генерирует новые синтетические точки меньшинства с помощью интерполяции, похожей на SMOTE, но только вокруг образцов меньшинства, расположенных рядом с уточнённой границей. Сосредоточивая новую выборку там, где она наиболее информативна, и избегая явно зашумлённых участков, BSO формирует обучающий набор, который одновременно более сбалансирован по размеру и чище по структуре.
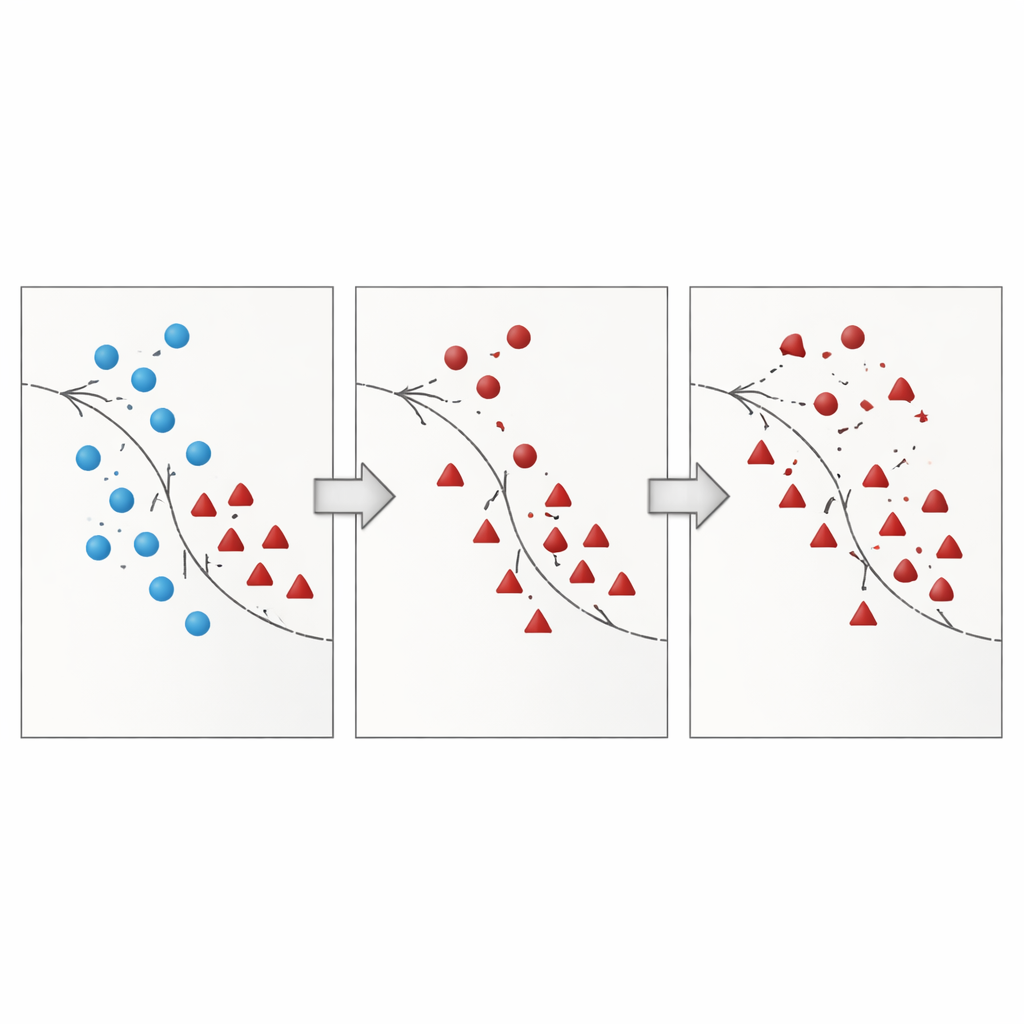
Проверка метода на практике
Чтобы оценить практическую эффективность, исследователи протестировали BSO на 30 эталонных наборах данных с разной степенью несбалансированности и перекрытия. Они сравнили его с семью широко используемыми альтернативами, включая случайное пере- и недовыборки (Random Over‑ and Under‑Sampling), SMOTE, Borderline‑SMOTE, NearMiss и два гибридных метода, сочетающих oversampling с очисткой от шума (SMOTE‑Tomek и SMOTE‑ENN). Три распространённых классификатора — опорные векторы (SVM), наивный Байес и случайный лес — обучались на каждом перерасчитанном наборе. Вместо полагания на простую точность исследование использовало метрики, более информативные при несбалансированности, такие как F1‑score, G‑mean, полнота (recall), точность (precision) и площадь под ROC‑кривой (AUC). На большинстве наборов и при разных классификаторах BSO показал более высокие или сопоставимые показатели при меньшей вариативности, что означает: его преимущества были стабильными и не зависели от конкретной модели или настройки.
Что это значит для реальных решений
Проще говоря, подход Borderline Shifting действует как аккуратный редактор для «грязных» данных: он очищает сбивающие с толку примеры вблизи разделительной линии между классами и затем добавляет ровно столько реалистичных примеров меньшинства в нужных местах. В результате алгоритмы обучения лучше распознают редкие, но важные события, не будучи введёнными в заблуждение зашумлёнными перекрытиями. Для приложений вроде обнаружения мошенничества, прогнозирования аварий или медицинской сортировки — где пропуск случая из меньшинства может дорого обойтись — этот метод предлагает практичный способ сделать модели справедливее, чувствительнее и надёжнее, при этом добавляя лишь умеренные вычислительные затраты.
Цитирование: Malhat, M.G., Elsobky, A.M., Keshk, A.E. et al. An approach for handling imbalanced datasets using borderline shifting. Sci Rep 16, 8264 (2026). https://doi.org/10.1038/s41598-026-39118-x
Ключевые слова: несбалансированность классов, повышение выборки (oversampling), граница решений, обнаружение аномалий, робастность машинного обучения