Clear Sky Science · ru
Крупные языковые модели демонстрируют эффекты, похожие на эффект Даннинга—Крюгера, при многоязычной проверке фактов
Почему умная проверка фактов важна для всех
Дезинформация распространяется сейчас быстрее, чем когда-либо, формируя взгляды людей на здоровье, политику, науку и повседневную жизнь. Многие платформы и редакции начинают опираться на искусственный интеллект — в частности на крупные языковые модели (LLM) — чтобы помогать проверять, правда ли те или иные вирусные утверждения. В этом исследовании задают обманчиво простой, но ключевой вопрос: когда мы позволяем этим системам судить о фактах, как часто они оказываются правы, насколько уверенно они это делают и меняется ли это в разных языках и регионах мира?
Как исследователи проверяли ИИ на реальных слухах
Вместо выдумывания искусственных примеров авторы построили свои тесты на основе 5000 подлинных утверждений, которые уже расследовали профессиональные организации по проверке фактов по всему миру. Эти утверждения охватывают 47 языков и поступают как из стран Глобального Севера, так и Глобального Юга, отражая беспорядочную, мультикультурную реальность онлайн-слухов. Включались только утверждения с однозначными вердиктами «правда» или «ложь», подтверждёнными несколькими фактчекерами, что создало надёжную эталонную базу для сравнения.
Затем авторы пропустили через девять широко используемых языковых моделей — от небольших открытых систем до продвинутых коммерческих — каждое утверждение. Чтобы имитировать то, как люди обычно общаются с чатботами, большинство подсказок были простыми вопросами вроде «Это правда?» или «Это ложь?», написанными на том же языке, что и утверждение. Четвёртая, более профессиональная схема использовала подробную инструкцию на английском, превращавшую модель в виртуального фактчекера и запрашивавшую структурированный ответ. Человеческие аннотаторы внимательно читали ответы моделей и помечали их как утверждающие, что утверждение истинно, ложно или отказывающиеся дать ясный вердикт.
Измеряя не только правильно или неправильно, но и когда сказать «не знаю»
Команда сделала больше, чем просто подсчитывала попадания и промахи. Они использовали три ключевые меры, чтобы зафиксировать поведение моделей. Во-первых, «селективная точность» показывала, как часто модель была права, когда она действительно занимала позицию и заявляла, что утверждение истинно или ложно. Во-вторых, «точность с допущением воздержания» считала приемлемым и даже желательным, чтобы модель признавалась в неопределённости вместо угадывания — это важно в чувствительных областях, например в медицине или на выборах. В-третьих, «частота определённых ответов» отслеживала, как часто модель давала однозначный ответ вообще, выступая приблизительной мерой её поведения уверенности.
Профессиональная подсказка со структурированными этапами последовательно повышала точность во всех моделях. Но она также выявила компромисс: небольшие модели часто становились более решительными, не становясь при этом надёжнее, тогда как большие модели использовали структуру, чтобы давать реже, но более качественные ответы. Обычные, разговорные подсказки вызывали более осторожное поведение, особенно у слабых моделей, но при этом несколько снижали их точность.
Когда менее способные системы ведут себя более уверенно
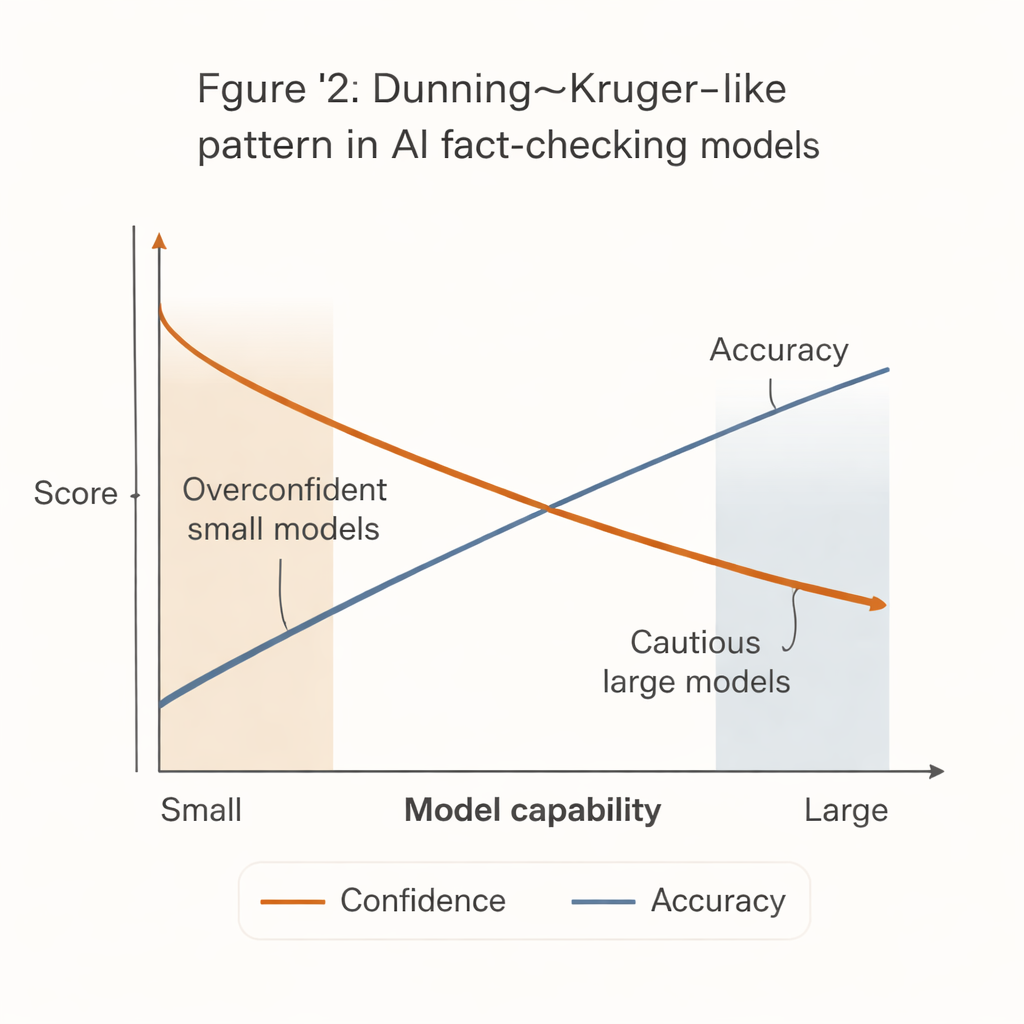
Проявилась заметная закономерность, напоминающая известный эффект Даннинга—Крюгера в психологии человека: наименее способные системы вели себя наиболее уверенно. Небольшие, дешёвые модели склонны давать твёрдые вердикты по подавляющему большинству утверждений, но с заметно более низкой точностью. Напротив, сильнейшие модели — такие как продвинутые версии GPT — были значительно точнее, когда они всё же высказывались, но гораздо чаще воздерживались, особенно в случае сложных или неоднозначных утверждений.
Этот «разрыв между уверенностью и компетентностью» имеет реальные последствия. Многие слаборассчитанные редакции, организации гражданского общества и местные службы проверки фактов не могут позволить себе самые мощные системы ИИ. Они с большей вероятностью примут более мелкие, дешёвые модели, которые кажутся решительными, но чаще ошибаются. Если эти инструменты интегрировать в рабочие процессы или системы модерации сообщества без тщательных предохранителей, они могут фактически усиливать дезинформацию, производя уверенные, но неверные проверки фактов.
Неравномерная эффективность по языкам и регионам
Исследование также показывает, что эти системы работают не одинаково для всех. По нескольким крупным языкам модели в целом показывали лучшие результаты на английских утверждениях и немного хуже — на португальских и хинди. Крупные модели, как правило, отвечали более осторожно на неанглоязычных запросах, но всё же опережали малые по точности. При сравнении утверждений, связанных с Глобальным Севером и Глобальным Югом, большинство моделей справлялось хуже с последними. Небольшие системы часто оставались уверенными, снижая точность, тогда как большие модели демонстрировали больший спад в частоте определённых ответов, но меньший — в правильности, что указывает на то, что они ощущали собственную неопределённость и воздерживались.
Что это значит для будущего надёжных инструментов ИИ
Для неспециалиста основной вывод ясен: современные ИИ-фактчекеры далеки от равенства, и самые доступные из них могут вводить в заблуждение сильнее всех. Мощные модели могут быть осторожными и точными, но они дороги и порой чрезмерно нерешительны. Более слабые модели смелы, но с большей вероятностью ошибаются, особенно вне английского языка и в материалах из Глобального Юга. Авторы утверждают, что ИИ должен поддерживать, а не заменять человеческих проверяющих факты, и что политические и дизайнерские решения должны способствовать лучшей калибровке — обучению систем тому, когда молчать — и более справедливому доступу к качественным инструментам. В противном случае та же технология, созданная для борьбы с дезинформацией, может углубить те информационные неравенства, которые она призвана решать.
Цитирование: Qazi, I.A., Khan, Z., Ghani, A. et al. Large language models show Dunning-Kruger-like effects in multilingual fact-checking. Sci Rep 16, 7594 (2026). https://doi.org/10.1038/s41598-026-39046-w
Ключевые слова: дезинформация, проверка фактов, крупные языковые модели, уверенность ИИ, многоязычное смещение