Clear Sky Science · ru
Стратегия управления гуманоидным типом на основе глубокого подкрепления для повышения комфорта в роботах реабилитации нижних конечностей
Роботы, которые помогают людям снова ходить
Когда у человека возникают трудности с ходьбой после инсульта или повреждения спинного мозга, терапия может быть медленной, утомительной и неприятной. Роботы для реабилитации нижних конечностей созданы, чтобы поддерживать и направлять ноги пациента во время тренировок, но современные устройства часто ощущаются жесткими и «роботизированными». В этом исследовании изучается, как придание таким роботам более похожей на человеческую «мастерицы» — с помощью современных алгоритмов обучения — может сделать тренировки мягче, естественнее и, в конечном счёте, эффективнее для пациентов.
Почему практика ходьбы должна ощущаться естественно
Старение населения увеличивает число людей с серьёзными нарушениями походки, и многие обращаются к роботизированной реабилитации. Традиционные роботы следуют заранее запрограммированным траекториям для ног и используют простые управляющие правила для приведения суставов в движение. Хотя такие методы надежны, они плохо справляются с хаотичным характером человеческого движения: походка у каждого человека немного отличается, и жёсткий робот может тянуть или толкать так, что это ощущается неловко или даже болезненно. Авторы утверждают, что для эффективной реабилитации робот должен не только удерживать пациента в вертикальном положении и поддерживать движение, но и адаптироваться к естественным шаблонам ходьбы и минимизировать силы, которые он передаёт телу.
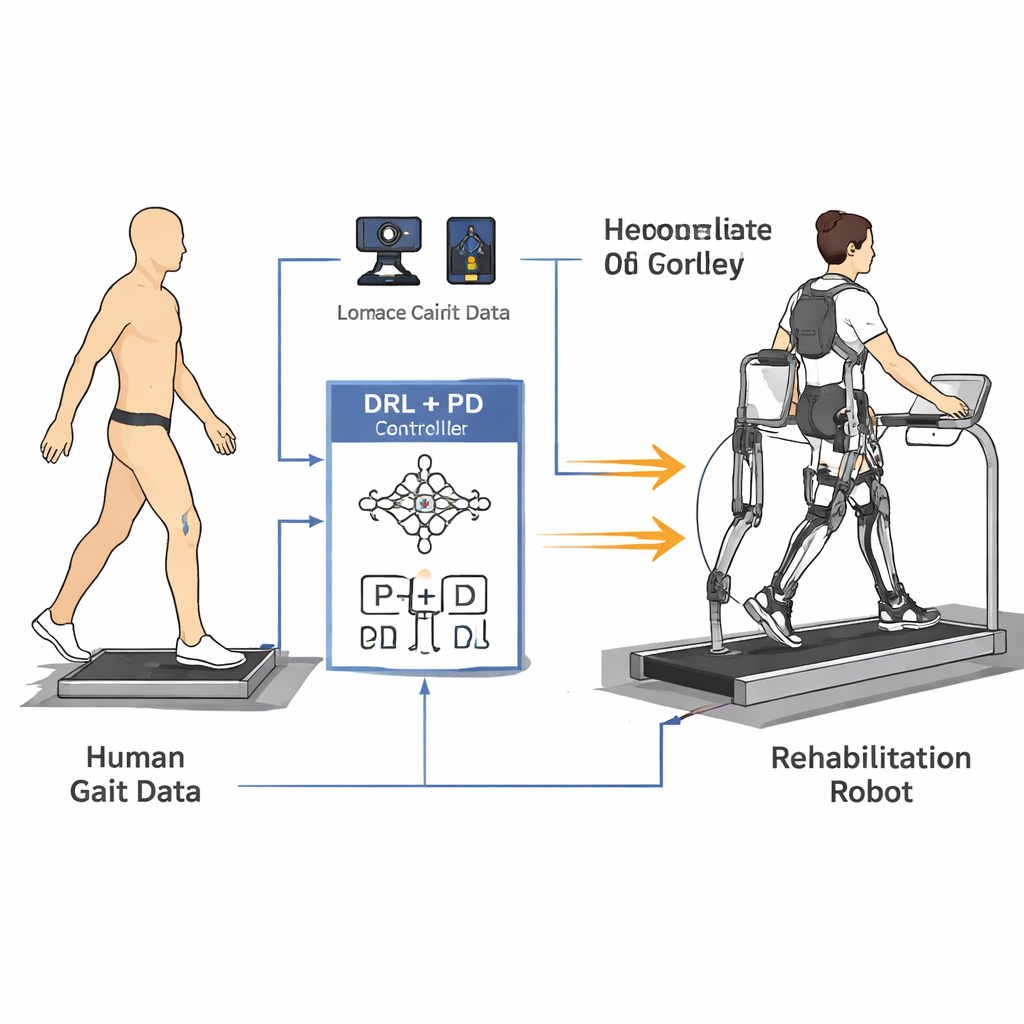
Обучение на реальных шагах человека
Чтобы научить робота тому, как люди действительно ходят, исследователи сначала построили упрощённую математическую модель ног и туловища. Затем они записали данные походки пятерых здоровых добровольцев с помощью высокоточной системы трёхмерной видеозаписи движений и силовых платформ в полу. Отражающие метки на бёдрах, коленях, щиколотках и туловище позволили вычислить, как каждый сустав двигался в течение полного шага, а датчики под стопами измеряли силу, с которой каждая нога давила на опору. На основе этих измерений были сформированы гладкие эталонные кривые для углов бёдер и коленей и прослежено изменение суставных сил во времени, что позволило зафиксировать как форму, так и ритм нормальной ходьбы.
Более умный контроллер, который при этом остаётся безопасным
В основе статьи лежит новая «гуманоидная» стратегия управления, которая сочетает глубокое обучение с подкреплением (DRL) и классический пропорционально-дифференциальный (PD) контроллер. DRL — это тип искусственного интеллекта, в котором виртуальный агент пробует действия, наблюдает результаты и постепенно выясняет, что работает лучше, максимизируя сигнал вознаграждения. В данном случае агент располагается над PD-слоем: он видит углы и скорости суставов робота и принимает решение о прикладываемых крутящих моментах, в то время как PD-слой следит за тем, чтобы суставы не отклонялись сильно от безопасных, похожих на человеческие целевых углов. Функция вознаграждения тщательно сконструирована так, чтобы поощрять устойчивое движение вперёд и одновременно штрафовать всё, что могло бы доставлять пациенту дискомфорт — например рывки, большие силы в суставах или небезопасные позы, такие как чрезмерный наклон или малая клиренс стопы.
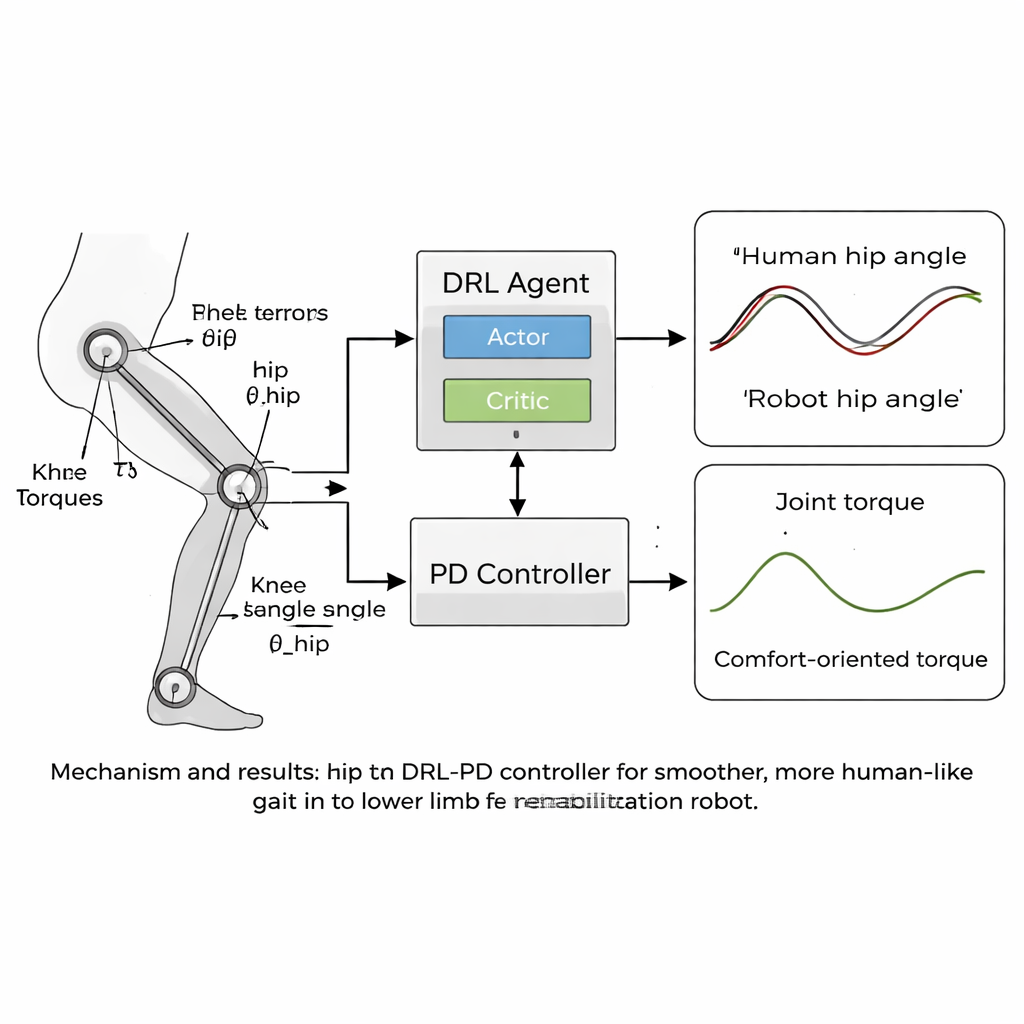
Более плавное движение, близкое к человеческой походке
Команда протестировала подход в компьютерных симуляциях, используя модель реабилитационного робота для нижних конечностей с тазобедренными и коленными суставами, соответствующими их данным по походке. В ходе тысяч тренировочных эпизодов контроллер DRL-PD научился порождать повторяющийся цикл ходьбы, в котором углы суставов тесно следовали эталонным человеческим паттернам. Бёдра и колени робота двигались в регулярных, устойчивых циклах — признак надёжной, воспроизводимой походки. Важный результат: крутящие моменты, необходимые для приведения суставов в движение, стали более гладкими и меньшими по величине по сравнению со стандартным PD-контроллером. Количественные показатели показали, что ошибки слежения снизились до нескольких сотых радиана, а скорость изменения суставных моментов — прообраз того, насколько «рывковыми» были бы ощущения пациента — сократилась более чем вдвое. Контроллер также оставался устойчивым даже при изменении масс ног модели на несколько процентов, что указывает на его способность переносить реальные различия между пользователями.
Что это значит для будущих реабилитационных роботов
Для неспециалистов главный вывод прост: позволив роботу научиться ритмам и ограничениям человеческой ходьбы на основе реальных данных и поощряя его за плавность и деликатность, мы можем создать устройства, которые помогают практиковать ходьбу так, что это даёт более естественные и менее стрессовые ощущения. Пациенты могут быть более готовы к длительным и частым занятиям, если робот движется вместе с ними, а не против них. Хотя текущие результаты получены в симуляции и требуют мощных компьютеров для обучения, после завершения обучения контроллер может эффективно работать на реальных устройствах. Авторы рассматривают эту работу как шаг к персонализированным адаптивным реабилитационным роботам, которые подстраиваются под уникальную походку и потребности в комфорте каждого пациента, что потенциально улучшит как восстановление, так и качество жизни.
Цитирование: Jin, Y., Zhang, J., Li, W. et al. A humanoid control strategy based on deep reinforcement learning for enhanced comfort in lower limb rehabilitation robots. Sci Rep 16, 7370 (2026). https://doi.org/10.1038/s41598-026-39011-7
Ключевые слова: реабилитационные роботы, тренировка походки, глубокое обучение с подкреплением, экзоскелет, комфорт пациента