Clear Sky Science · ru
Тонко настроенные большие языковые модели со структурированными подсказками позволяют эффективно создавать онкологические графы знаний по раку лёгкого
Почему важно превращать медицинский текст в «карты»
Рак лёгкого — одно из самых смертельных заболеваний в мире, а сведения о его диагностике и лечении разрознены: научные статьи, выписки из больниц, онлайн-консультации и записи из практик традиционной медицины. Врачам и исследователям трудно уследить за этим потоком текста. В работе предлагается новый способ автоматически преобразовать разрозненные знания в единое, удобное для навигации «поле знаний» — граф знаний по раку лёгкого — с помощью тонко настроенной большой языковой модели и тщательно структурированных подсказок. Результат призван упростить поиск сложной медицинской информации для компьютеров и сделать её более пригодной для использования экспертами в системах поддержки принятия решений.
От разрозненных рассказов к связанным фактам
Авторы опираются на простую идею: если надёжно выделять в медицинском тексте «кто — делает — что» можно составить связный граф фактов. На практике это значит преобразовывать свободные предложения в небольшие строительные блоки — тройки: пары сущностей, связанные отношением, например «рак лёгкого – лечится – химиотерапией». Традиционные подходы к построению таких графов требуют многочисленных аннотаторов или хрупких правил, которые не учитывают нюансы и новые открытия. Чтобы обойти эти ограничения, команда тонко настраивает существующую китайскую большую языковую модель ChatGLM-6B, чтобы она специализировалась на выявлении медицински значимых троек о раке лёгкого в самых разных источниках — от онлайн-чатов пациент–врач до структурированных баз данных и записей традиционной китайской медицины. 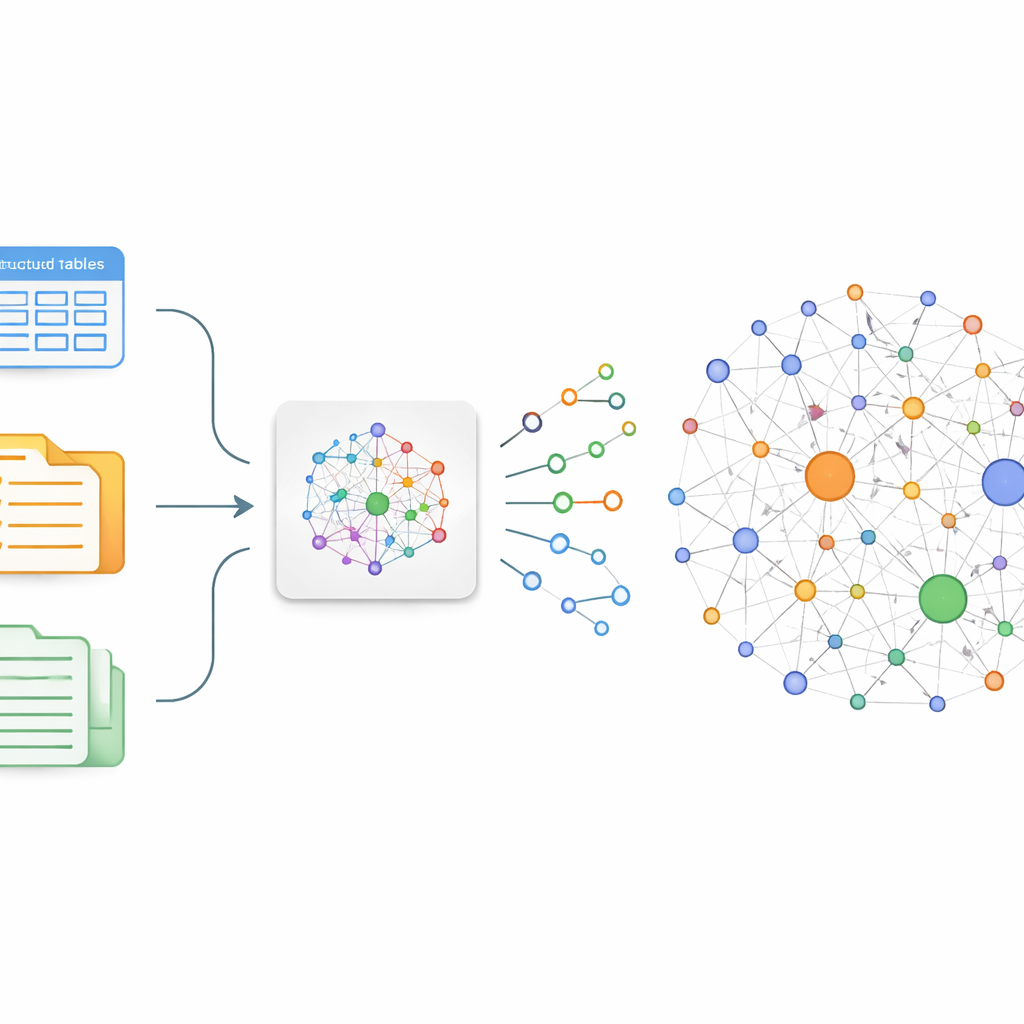
Обучение ИИ мыслить компактными единицами
Простая просьба к универсальной языковой модели «извлечь информацию» часто даёт неаккуратные, разговорные ответы. Исследователи поэтому разработали строгую схему подсказок и затем дообучили модель почти на 50 000 примеров желаемого поведения. Каждый пример содержит инструкцию и точный ожидаемый вывод в формате тройки. Подсказка заставляет модель действовать как профессионал в области анализа текстов, выдавать только структурированные тройки в машинно-читаемом формате и «думать пошагово», когда в предложениях есть вложенные детали — например, вид лечения, используемый препарат и его доза. Сочетание задания роли, правил формата и пошагового рассуждения превращает модель — теперь называемую KGLM — из разговорного ассистента в дисциплинированный извлекатель фактов, готовых к машинной обработке.
Объединение разных источников в единый ясный граф
Сырые тройки из текста — лишь часть работы. Одна и та же болезнь или препарат часто встречаются под разными именами — например, «хроническая обструктивная болезнь лёгких» и «ХОБЛ». Чтобы избежать шума и путаницы, авторы разработали этап слияния, который объединяет эквивалентные сущности из трёх потоков данных: неструктурированного веб‑текста, полуструктурированных клинических случаев и уже существующих медицинских графов знаний. Сначала быстрый проверочный шаг на основе строк выявляет очевидные совпадения. Когда этого недостаточно, более глубокая модель семантического сходства (Sentence-BERT) сравнивает значения в контексте. Сущности, признанные дубликатами, сворачиваются в единый канонический узел: выбирается короткое название, а другие формы сохраняются как псевдонимы. Эксперты затем просматривают спорные случаи и удаляют вводящие в заблуждение или низкокачественные утверждения, что даёт более чистый и согласованный граф знаний по раку лёгкого, хранящийся в базе данных Neo4j. 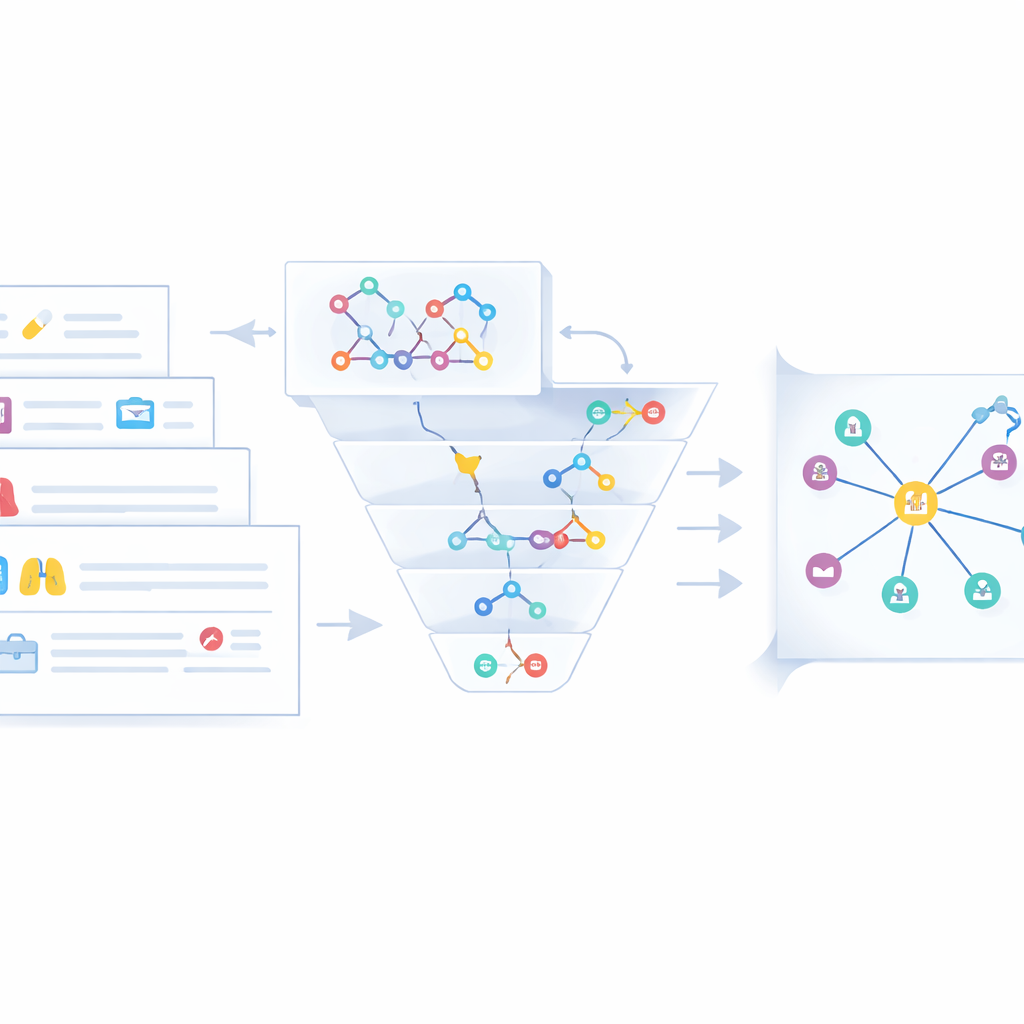
Насколько хорошо работает эта «карта знаний»?
Чтобы оценить производительность, команда сравнивает KGLM со стандартными подходами глубокого обучения на основе BERT и сверточных сетей, а также с оригинальной, не дообученной моделью ChatGLM. В задаче извлечения отношений — определении, какие сущности связаны и как — тонко настроенный KGLM с подсказками достигает F1 приблизительно 0,82, превосходя все протестированные базовые модели и показывая примерно 25‑процентное улучшение по сравнению с исходной моделью. Тесты абляции демонстрируют, что каждый компонент подсказки важен: удаление роли эксперта, строгого формата троек или указания «думать пошагово» снижает точность, особенно для сложных предложений с вложенными атрибутами или терминологией традиционной китайской медицины. Панель клинических и информационных экспертов также оценила итоговый граф как более точный, пригодный и клинически релевантный по сравнению с графами, построенными без дообучения или структурированных подсказок.
Что это означает для будущих медицинских инструментов
Проще говоря, исследование показывает: при правильной подготовке и инструкциях большая языковая модель может эффективно превращать беспорядочный, реальный медицинский текст о раке лёгкого в структурированную, доступную для поиска сеть фактов. Этот граф знаний по раку лёгкого, хотя пока остаётся исследовательским прототипом и ограничен китайскоязычными источниками и одной областью заболевания, указывает на будущее, где постоянно обновляемые «карты знаний» могли бы поддерживать системы принятия решений, учебные инструменты и научные исследования. Авторы подчёркивают, что такие графы требуют тщательной валидации и регулярного обновления и не готовы самостоятельно направлять медицинскую помощь без экспертного контроля. Тем не менее их результаты указывают, что тонко настроенные языковые модели в сочетании с продуманными подсказками могут сделать задачу организации медицинских знаний более масштабируемой и своевременной.
Цитирование: Zhou, C., Gong, Q., Luan, H. et al. Fine-tuned large language models with structured prompts enable efficient construction of lung cancer knowledge graphs. Sci Rep 16, 9505 (2026). https://doi.org/10.1038/s41598-026-38959-w
Ключевые слова: рак лёгкого, граф знаний, большая языковая модель, извлечение отношений, медицинский ИИ