Clear Sky Science · ru
Двухпоточная система глубокого обучения для непрерывного распознавания жестового языка с целью повышения доступности коммуникации в регионе Ха’иль
Преодоление разрыва в коммуникации
Для многих людей с нарушением слуха жестовый язык является основным средством общения, однако большинство компьютеров, телефонов и государственных служб по-прежнему не понимают его. В этой статье предлагается новая система искусственного интеллекта, способная отслеживать непрерывную речь на жестах в видео и точнее преобразовывать её в письменный текст. Уделяя внимание не только движениям рук, но и положению головы и мимике, система стремится сделать технологическое общение более естественным и доступным — особенно для сурдосообщества в регионе Ха’иль в Саудовской Аравии, где цифровая поддержка всё ещё ограничена. 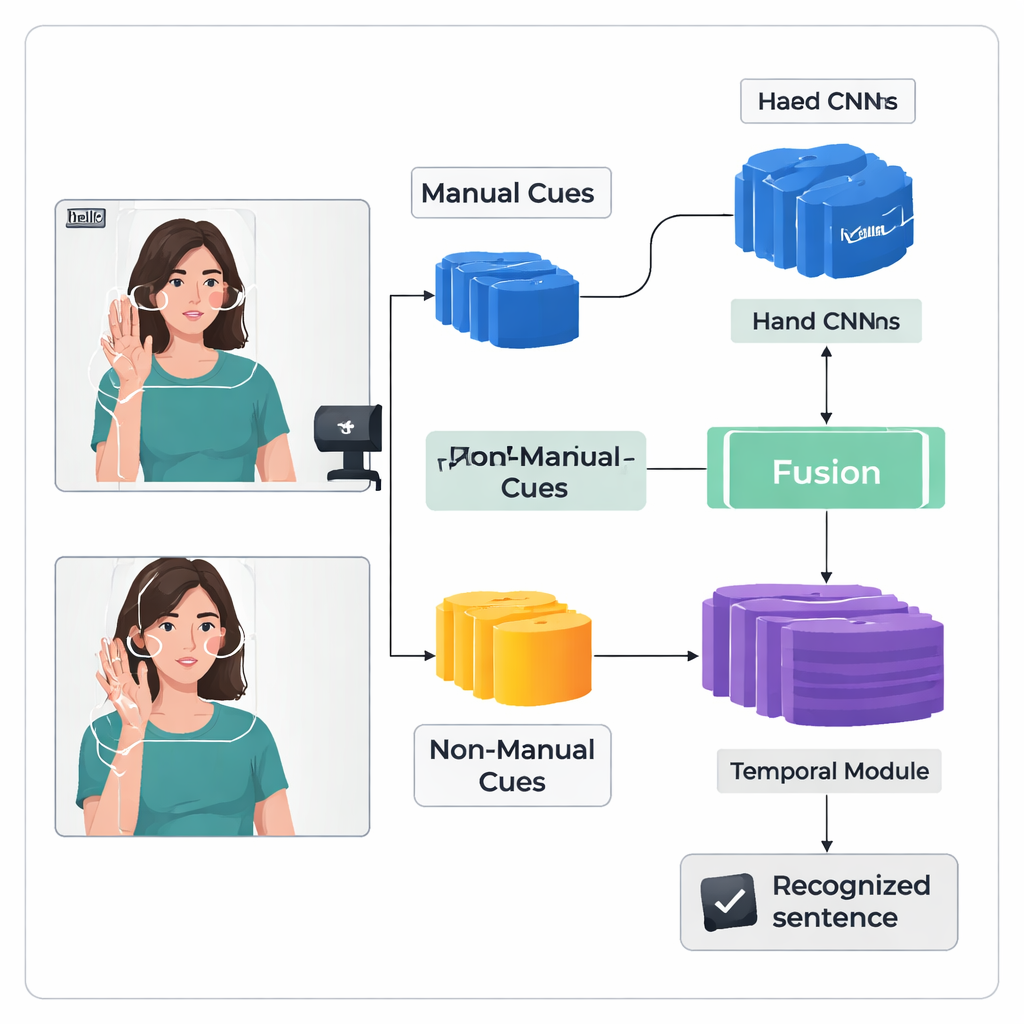
Почему одних рук недостаточно
Жестовые языки — это богатые и сложные системы, использующие верхнюю часть тела целиком. Смысл формируется не только движением рук, но и выражением лица, направлением взгляда, наклоном или кивком головы. Эти негручные сигналы могут обозначать вопрос, отрицание, акцент или эмоцию. Люди считывают всё это без усилий, но большинство систем для распознавания жестов сосредоточены почти исключительно на руках. Такое упрощение облегчает обучение, но приводит к потере важных подсказок, особенно когда знаки сливаются в быстрые непрерывные предложения, а не представляют собой отдельно взятые слова.
Два потока, работающие параллельно
Авторы представляют «двухпоточную» архитектуру глубокого обучения под названием TS-CNN, которая обрабатывает руки и голову отдельно, а затем объединяет полученные данные. Один поток фокусируется на кадрах, обрезанных по рукам исполнителя, изучая формы, движение и положение. Второй поток получает компактную карту лица и головы, полученную на основе ключевых точек и оценок позы головы. Оба потока используют стандартную визуальную сеть для преобразования каждого кадрового изображения в числовые признаки. Затем система фьюзит эти признаки покадрово, учитывая, что сигналы от рук и головы происходят одновременно при реальном исполнении жестов. Последующий временной модуль анализирует множество кадров, чтобы понять, как знаки разворачиваются во времени, а рекуррентный слой формирует последовательность предсказанных единиц жеста, или глосс.
Уточнение «памяти» системы о знаках
Распознавание непрерывных жестов сложнее из‑за ограниченности обучающих данных и размытости знаков, отсутствия точных пометок покадрово. Чтобы справиться с этим, авторы добавляют Модуль Усиления Признаков (Feature Enhancement Module), который даёт сети дополнительное руководство во время обучения. Широко используемая техника выравнивает предсказанную последовательность глоссов с видео, давая вероятные временные позиции для каждого глосса. Новый модуль использует эти предложения по выравниванию как прямое обучение, чтобы уточнить внутреннее представление признаков глоссов. Проще говоря, система учится не только выдавать правильную последовательность, но и формировать более чёткие и согласованные внутренние «памяти» о том, как выглядит каждый знак в разных видео.
Проверка подхода
Команда оценивает TS-CNN на двух известных наборах данных жестового языка: RWTH-PHOENIX-Weather 2014 для немецкого жестового языка и CSL Split II для китайского жестового языка. Производительность измеряется с помощью показателя ошибок по словам (word error rate), стандартной метрики, похожей на используемую в распознавании речи. По сравнению с базовой моделью, учитывающей лишь движения рук, добавление информации о позе головы сокращает ошибки примерно на 4 процентных пункта на немецком наборе и на 3–4 пункта на китайском. Включение модуля усиления признаков даёт ещё больший прирост, снижая ошибки примерно на 10–14 процентов в целом на обоих наборах. Система также работает эффективно, достигая реального времени на современном графическом процессоре, что важно для использования в живой интерпретации или мобильных приложениях. 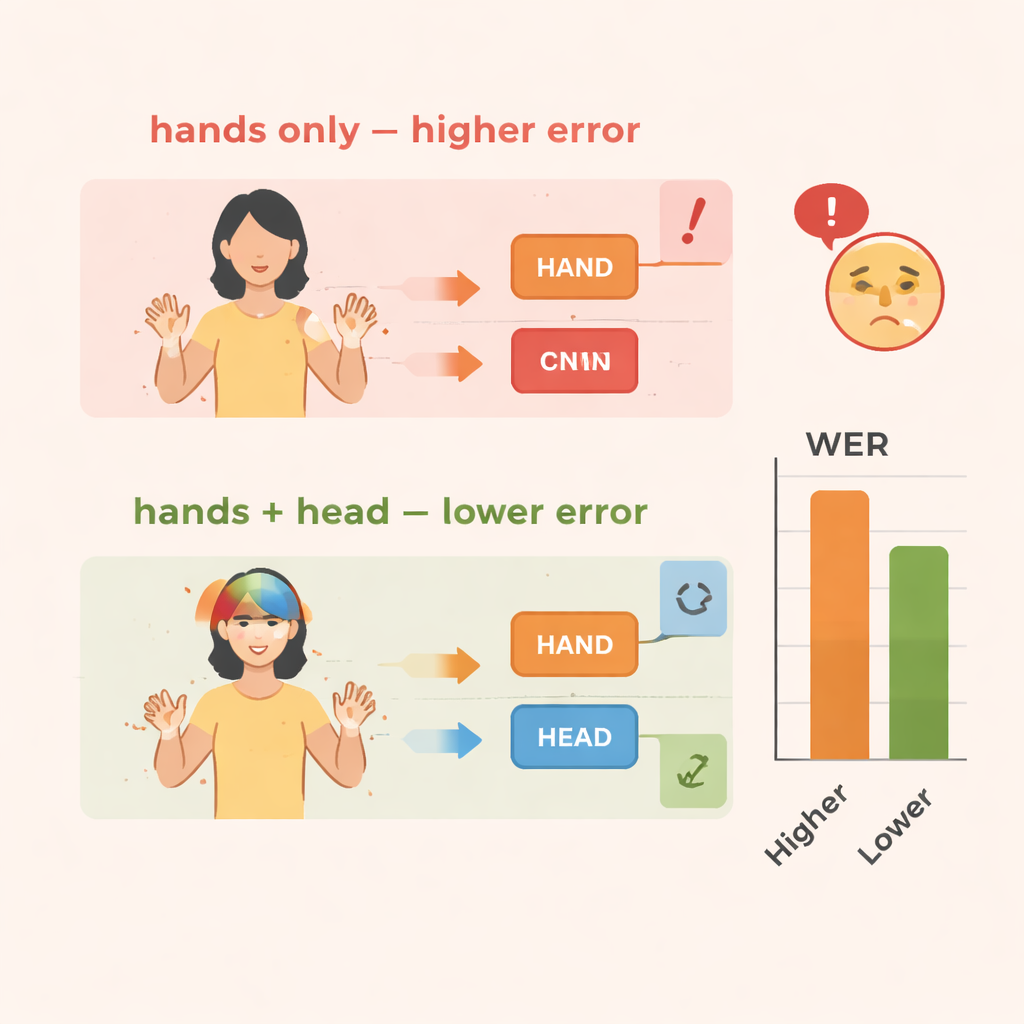
Что это значит для повседневной жизни
Проще говоря, исследование показывает, что компьютеры могут надёжнее понимать жестовый язык, когда «смотрят» на исполнителя целиком, а не только на руки. Моделируя движения головы и мимические сигналы вместе с движениями рук и тщательно уточняя процесс обучения при ограниченных данных, архитектура TS-CNN приближает практические системы, которые могли бы помогать людям с нарушением слуха в школах, больницах и государственных учреждениях. Для регионов вроде Ха’иль, где переводчики в дефиците, а технологические проекты только развиваются, такая система в перспективе может поддержать более инклюзивную коммуникацию — помогая преодолеть разрыв между людьми, использующими жестовый язык, и слышащим миром, не заменяя при этом богатый человеческий опыт самого жестового общения.
Цитирование: Harrouch, H., Guesmi, H., Alalfy, H. et al. A dual-stream deep learning framework for continuous sign language recognition to enhance communication accessibility in the Ha’il region. Sci Rep 16, 7070 (2026). https://doi.org/10.1038/s41598-026-38912-x
Ключевые слова: распознавание жестового языка, глубокое обучение, доступность, компьютерное зрение, взаимодействие человек–компьютер