Clear Sky Science · ru
Метод защиты конфиденциальности данных для моделей прогнозирования инфекционных заболеваний с балансом скорости обучения и точности
Почему защита медицинских данных по‑прежнему важна
Больницы и органы здравоохранения теперь полагаются на искусственный интеллект для прогнозирования вспышек гриппа, COVID‑19 и других инфекций за дни или недели вперед. Эти прогнозы помогают планировать кампании по вакцинации, кадровую обеспеченность и чрезвычайные мероприятия. В то же время детальные медицинские записи, делающие прогнозы точными, являются крайне чувствительной информацией. Законодательные ограничения и общественная озабоченность часто препятствуют объединению данных между учреждениями, что снижает эффективность моделей. В этой работе предложен способ обучать качественные системы прогнозирования инфекционных заболеваний, при котором данные каждой больницы остаются надежно локально.
Учиться у многих больниц, не передавая карточки пациентов
Авторы исходят из метода, называемого федеративным обучением, при котором несколько больниц совместно обучают общую модель прогнозирования. Вместо копирования сырых медицинских записей на центральный сервер каждое учреждение обучает модель локально и отсылает только числовые обновления параметров модели. Центральный сервер агрегирует эти обновления и рассылает обновленную модель обратно. Этот цикл повторяется многократно. В теории федеративное обучение защищает конфиденциальность, поскольку персональные данные не покидают учреждение. На практике, однако, хитроумные злоумышленники иногда могут вывести сведения об исходных данных по передаваемым обновлениям, поэтому требуются дополнительные меры защиты. 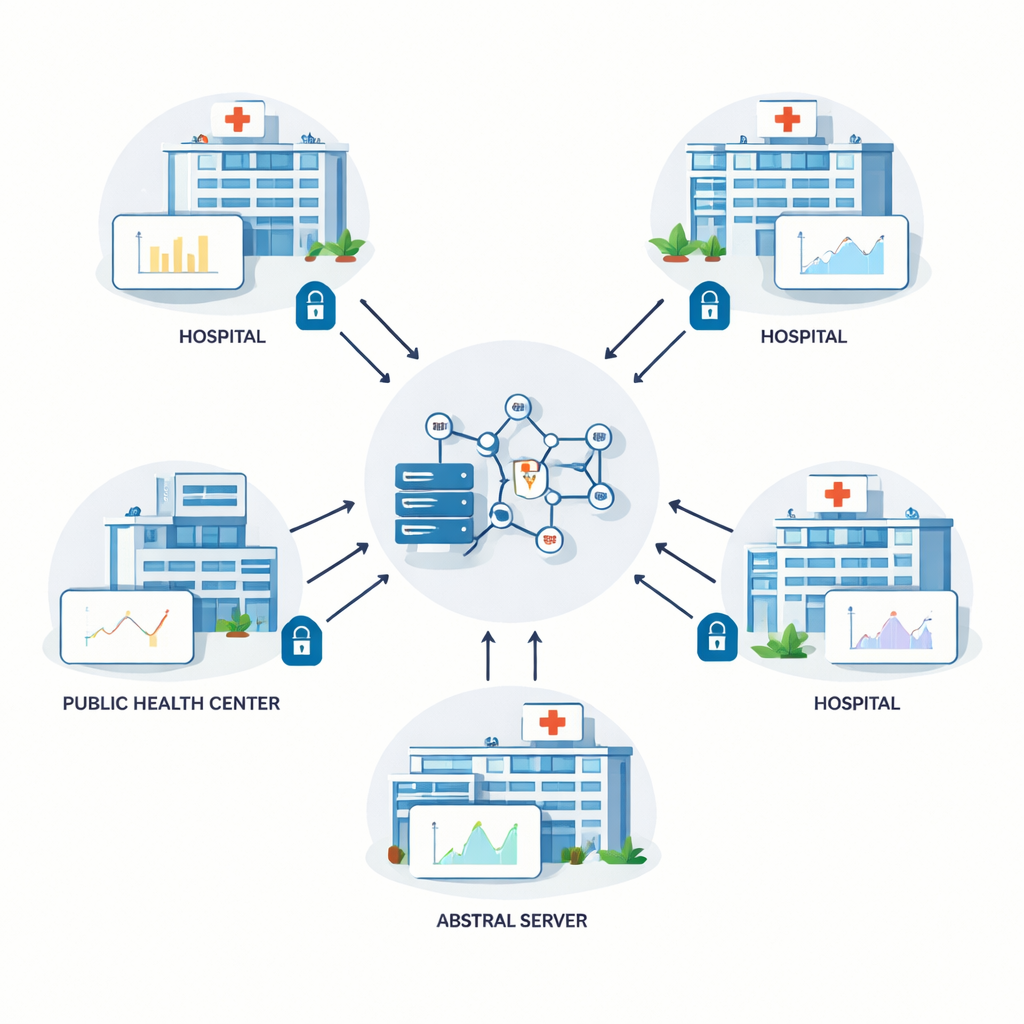
Шифруем числа умно
Чтобы усилить безопасность, команда использует гомоморфное шифрование — форму цифрового замка, которая позволяет выполнять вычисления непосредственно над зашифрованными числами, не расшифровывая их. Традиционные схемы такого вида очень надежны, но известны своей медлительностью и большими требованиями к объему данных, что затрудняет их использование с большими сложными моделями, например на базе сетей Long Short‑Term Memory (LSTM). Исследователи разработали гибридную схему, в которой разные части модели защищаются по‑разному. Наиболее «разоблачающие» компоненты экранируются сильным, но тяжелым шифрованием, тогда как менее чувствительные части используют более легкий и быстрый замок. Сверху по этому подходу действует заранее заданный случайный график, определяющий, в каких раундах обучения участники действительно отправляют зашифрованные обновления, что позволяет им пропускать избыточную коммуникацию. Тесты показывают, что такое сочетание ускоряет обучение примерно на 25% по сравнению с применением тяжелого шифрования везде, при этом сохраняя защиту данных в рамках сильных криптографических допущений.
Отправлять только действительно важные обновления
Даже при умном шифровании пересылка каждой мелкой поправки модели между учреждениями тратит время и сетевые ресурсы. Поэтому авторы предлагают новое правило обучения — Data Selection–Distributed Selection Stochastic Gradient Descent (DS‑DSSGD). В процессе обучения алгоритм измеряет, насколько сильно меняется каждая часть модели от шага к шагу. На передачу отправляются лишь те обновления, которые превышают заранее заданный порог; небольшие малоэффективные изменения просто игнорируются. Одновременно алгоритм отслеживает, какие записи данных вызывают наибольшие и наиболее информативные изменения. Эти влиятельные записи собираются в уточнённый набор данных, используемый для финального раунда обучения. Эксперименты на трех годах реальных отчетов о заболеваемости из города Ичан, в сочетании с локальными тенденциями поисковых запросов, показывают, что DS‑DSSGD сокращает время обучения примерно на 10% по сравнению с несколькими стандартными методами при отсутствии значимой потери прогнозной точности.
Практичная платформа для безопасного сотрудничества
Технические достижения имеют значение только если больницы и лаборатории действительно могут ими пользоваться. Чтобы преодолеть этот разрыв, команда интегрировала свои методы в реальную вычислительную среду под названием Yi Shu Fang XDP Privacy Security Computing Platform. XDP управляет полным циклом работы с медицинскими данными — от сбора и очистки до зашифрованного анализа и обмена результатами. Платформа поддерживает привычные инструменты, используемые статистиками, биоинформатиками и клиницистами, и позволяет исследователям из разных учреждений сотрудничать внутри контролируемого рабочего пространства, не загружая сырые данные. В рамках этой платформы гибридная схема шифрования и алгоритм DS‑DSSGD выполняются как подключаемые компоненты, превращая теоретическую схему в рабочую систему. 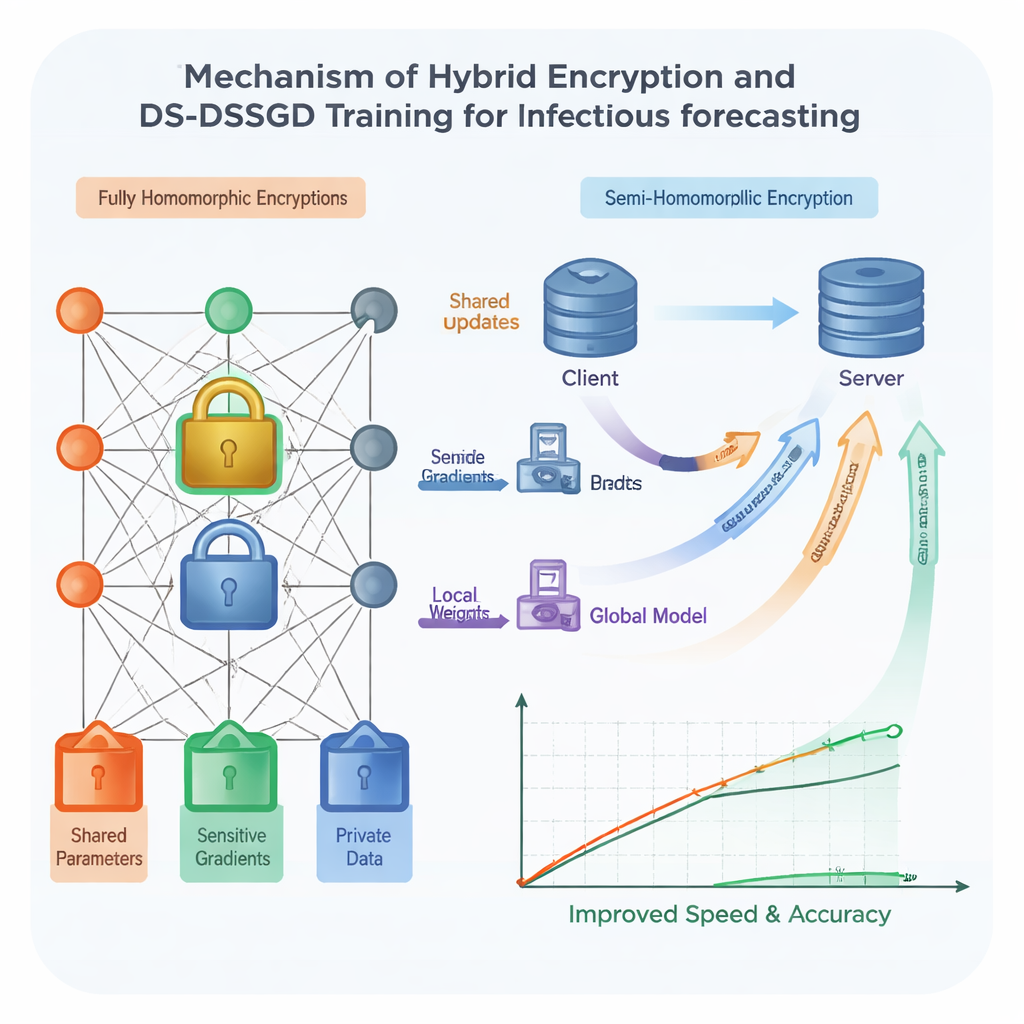
Что это значит для будущего прогнозирования вспышек
Проще говоря, исследование демонстрирует, что для прогнозирования инфекционных заболеваний можно «совместить два блага»: защищать конфиденциальность пациентов и при этом обучать быстрые и точные модели на данных из множества учреждений. Шифруя разные части модели с оптимальным уровнем защиты, отправляя обновления только при необходимости и размещая всю систему в безопасной платформе для совместной работы, авторы снижают стоимость приватности с неподъемного бремени до управляемых накладных расходов. При широком внедрении такие подходы могли бы позволить больницам и агентствам общественного здравоохранения объединить усилия против следующей эпидемии, не раскрывая при этом отдельные медицинские записи.
Цитирование: Wang, X., Jiang, Y., Pan, G. et al. A data privacy protection method for infectious disease prediction models with balanced training speed and accuracy. Sci Rep 16, 7415 (2026). https://doi.org/10.1038/s41598-026-38906-9
Ключевые слова: прогнозирование инфекционных заболеваний, конфиденциальность медицинских данных, федеративное обучение, гомоморфное шифрование, глубокое обучение