Clear Sky Science · ru
Оценка распространённости и обычности видов с помощью неконтролируемых методов
Почему важно считать обычные и редкие виды
Когда мы представляем природу, находящуюся под угрозой, чаще всего вспоминаются редкие животные на грани вымирания. Однако большая часть живой ткани вокруг нас состоит из вполне обычных существ, которые либо широко распространены, либо тихо исчезают, пока этого никто не замечает. Возможность оценить, насколько широко вид действительно распространён в данном месте, жизненно важна для прогнозирования реакции экосистем на загрязнение, изменение землепользования или климатические изменения. В этой статье представлен подход для одновременной оценки того, насколько обычны или редки многие виды, используя только уже имеющиеся записи наблюдений и современные методы анализа данных. Цель — предоставить более объективные входные данные для компьютерных моделей, предсказывающих, где виды могут жить сейчас и в будущем.
От простых наблюдений к крупным экологическим вопросам
Экологи регулярно используют компьютерные модели, называемые моделями экологической ниши, чтобы определить, какие среды подходят для вида. Эти модели помогают прогнозировать, где вид может появиться при изменяющемся климате или в новых регионах. Ключевой составляющей является «преваленция» — приблизительно доля обследованных участков, где вид присутствует. Она кодирует ожидание, будет ли вид обычным или редким до проведения новых учётов. Это предварительное ожидание сильно влияет на то, как модели преобразуют сырые оценки пригодности в вероятности присутствия и как они проводят границы между «присутствует» и «отсутствует» на карте. Если преваленция оценена неверно, особенно для редких видов, прогнозы могут вводить в заблуждение, и меры охраны могут быть направлены в неверные места.
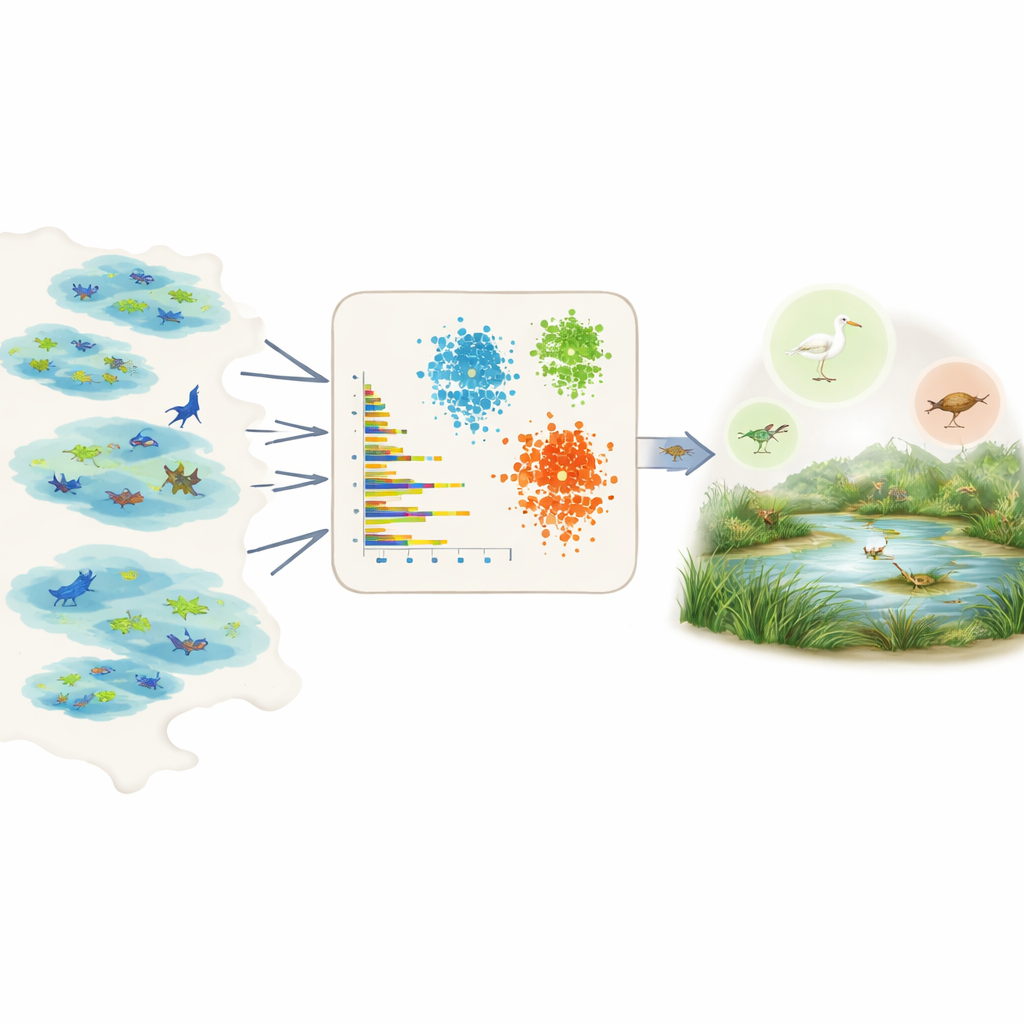
Дать данным «заговорить» за сотни видов
Непосредственно измерить преваленцию трудно, потому что полевые данные фрагментарны и смещены. Некоторые районы интенсивно обследуются, одни виды легче заметить, и многие записи поступают от проектов гражданской науки с неравномерной отдачей. Вместо того чтобы опираться на мнения экспертов или детальные знания по каждому виду, авторы используют данные Global Biodiversity Information Facility — огромной открытой базы наблюдений видов. Для каждого вида в выбранном регионе они сводят сырые записи к нескольким простым сопоставимым показателям: сколько особей обычно указывают в одном наблюдении, в скольких разных наборах данных или насколько различных водно-болотных угодьях встречается вид, насколько широко он распространён внутри этих водно-болотных участков и как часто его наблюдают во времени, включая случаи всплесков большого числа записей.
Обучение машин различать обычные и редкие виды
Имея эти сводные признаки, команда применяет три метода неконтролируемого обучения — два метода кластеризации и глубокую модель, известную как вариационный автоэнкодер — которые ищут закономерности, не зная заранее, какие виды являются обычными или редкими. Методы кластеризации группируют виды с похожей численностью, распространением и частотой наблюдений. Автоэнкодер учится, как выглядит «типичная» запись вида, и отмечает необычные шаблоны как аномалии, что часто соответствует редким или плохо задокументированным видам. Затем модели присваивают каждому виду три интуитивных класса — очень обычный, довольно обычный или редкий — и преобразуют эти классы в числовые значения преваленции, которые можно напрямую подставлять в модели экологической ниши в качестве априорных вероятностей.
Проверка подхода в уязвимом водоёме
Чтобы оценить, насколько хорошо работает эта схема на практике, авторы сосредоточились на бассейне озера Массаччукколи в Тоскане, Италия — низменном водно-болотном ландшафте, богатом птицами, рыбами, насекомыми и другими животными. Этот участок одновременно является очагом биоразнообразия и туристическим магнитом, но он уязвим к климатическим изменениям, дефициту воды и загрязнению. Для 161 вида животных, связанных с озером, модели обучали на записях из других итальянских болот, а затем просили оценить, насколько обычен каждый вид в Массаччукколи. Два местных эксперта с глубоким полевым опытом независимо оценивали те же виды. Сравнение показало, что глубокая модель согласовывалась с объединённым мнением экспертов примерно для 81–90 процентов видов, а методы кластеризации и ансамбль всех трёх подходов также показали хорошие результаты.
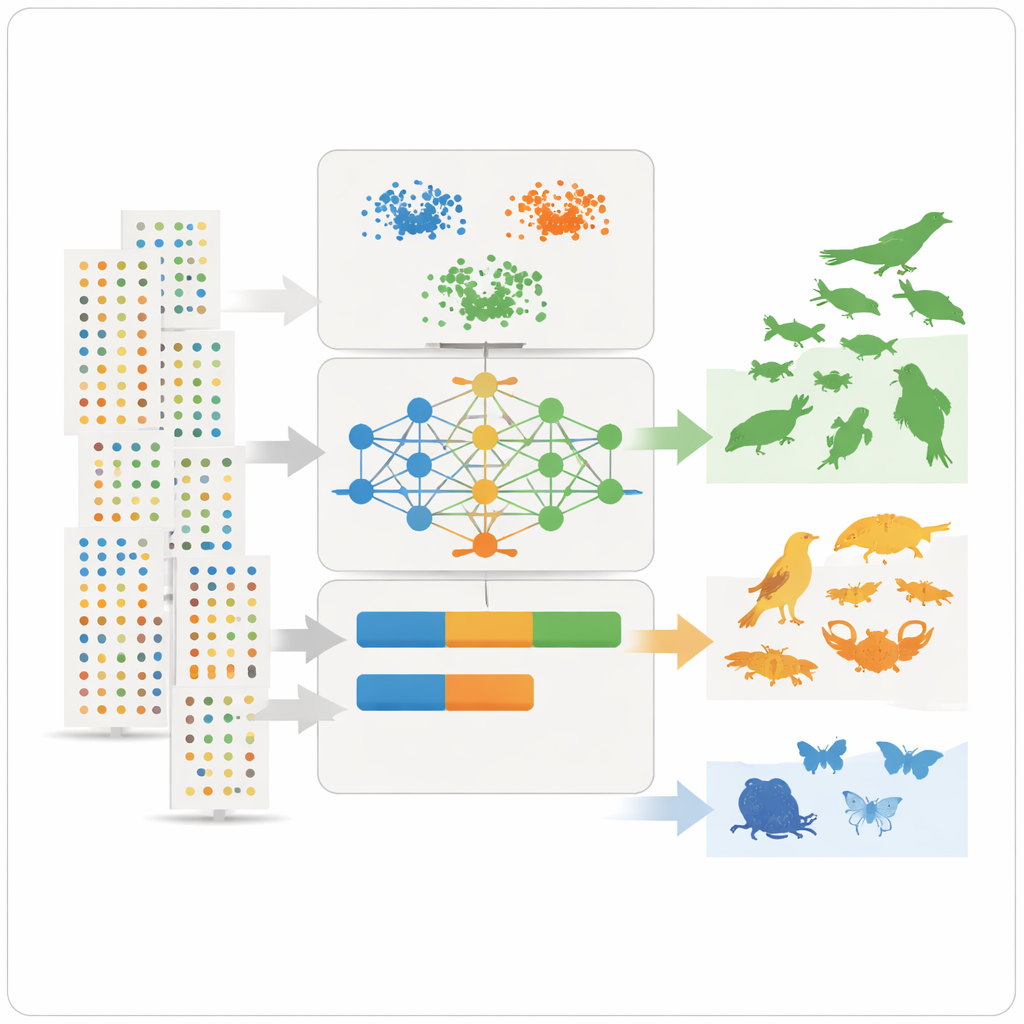
Чему учат разногласия и скрытые смещения
Не в каждом случае мнения совпадали идеально. Некоторые виды, хорошо известные экспертам как многочисленные вокруг озера, выглядели редкими в данных — часто потому, что они скрытны, недопредставлены в записях или за ними тщательнее наблюдают в отдельных водно-болотных угодьях. Это подчеркнуло ключевое ограничение: большие базы данных отражают, где и как люди ищут природу, а не только фактическое распространение видов. Анализ чувствительности показал, какие признаки наиболее важны для классификации: среднее число записей на набор данных, численность по каждому наблюдению и последовательность наблюдений по годам оказались особенно информативными. Несмотря на сохраняющиеся смещения, метод дал чёткие, воспроизводимые оценки преваленции и может быть настроен на использование более тонких или более грубых классов в зависимости от потребностей моделирования.
Что это значит для будущих прогнозов природы
Для неспециалистов главный вывод в том, что теперь мы можем умнее использовать имеющиеся данные о биоразнообразии, чтобы оценить, какие виды, вероятно, будут обычными, средними или редкими в данном месте, не подгоняя вручную каждый случай. Преобразуя шумные записи наблюдений в прозрачные, основанные на данных оценки преваленции, эта схема помогает экологическим моделям давать более реалистичные прогнозы пригодности местообитаний и будущих тенденций биоразнообразия. Это, в свою очередь, может поддержать лучшее планирование для болот вроде Массаччукколи и многих других экосистем по всему миру, даже когда полевые данные неполны, а время экспертов ограничено.
Цитирование: Bove, P., Bertini, A. & Coro, G. Estimating species commonness and prevalence through unsupervised methods. Sci Rep 16, 8331 (2026). https://doi.org/10.1038/s41598-026-38900-1
Ключевые слова: распространённость видов, моделирование биоразнообразия, экосистемы влажных территорий, машинное обучение в экологии, обычность видов