Clear Sky Science · ru
Оценка эффективности больших языковых моделей на персидских экзаменах по ревматологии: точность и клиническое рассуждение GPT-4o против GPT-5.1
Почему это важно для врачей и пациентов
Искусственный интеллект быстро проникает в медицинские аудитории и клиники, однако большинство тестов этих инструментов проводится на английском языке. Это исследование задаёт вопрос, важный для миллионов персоязычных людей: как хорошо продвинутые чат‑боты на базе ИИ, в частности GPT‑4o и GPT‑5.1, справляются со сложными вопросами по ревматологии, написанными на персидском? Ответ помогает преподавателям, обучающимся и пациентам понять, где эти инструменты могут безопасно помогать в обучении, а где по‑прежнему необходим человеческий профессионализм.
Испытание ИИ
Исследователи собрали 204 вопроса с несколькими вариантами ответов из официальных экзаменов Иранского Совета по ревматологии за 2023 и 2024 годы — те же экзамены, которые специалисты должны сдать для сертификации. После исключения семи дефектных вопросов в анализ попали 197 заданий. Каждый вопрос, включая сопутствующие изображения или графики, вводили на персидском в GPT‑4o и GPT‑5.1 в отдельных свежих чатах. Модели просили выбрать наилучший вариант ответа и объяснить ход рассуждений, имитируя то, как обучающийся мог бы обращаться к ИИ при подготовке.
Оценка ответов и рассуждений
Результаты оценивали двумя способами. Во-первых, выбранные моделями варианты сравнивали с официальным ключом ответов, что давало простую меру точности — «правильно/неправильно». Во‑вторых, шесть сертифицированных ревматологов независимо оценивали качество каждого объяснения по пятибалльной шкале — от явно неверного рассуждения до полного и клинически обоснованного объяснения. Ответы каждой модели оценивались двумя разными ревматологами, которые не знали оценок друг друга и официального ключа. Это позволило исследователям увидеть не только то, «угадал» ли ИИ ответ, но и насколько его логика соответствует мышлению специалистов.
Как показала себя более новая модель
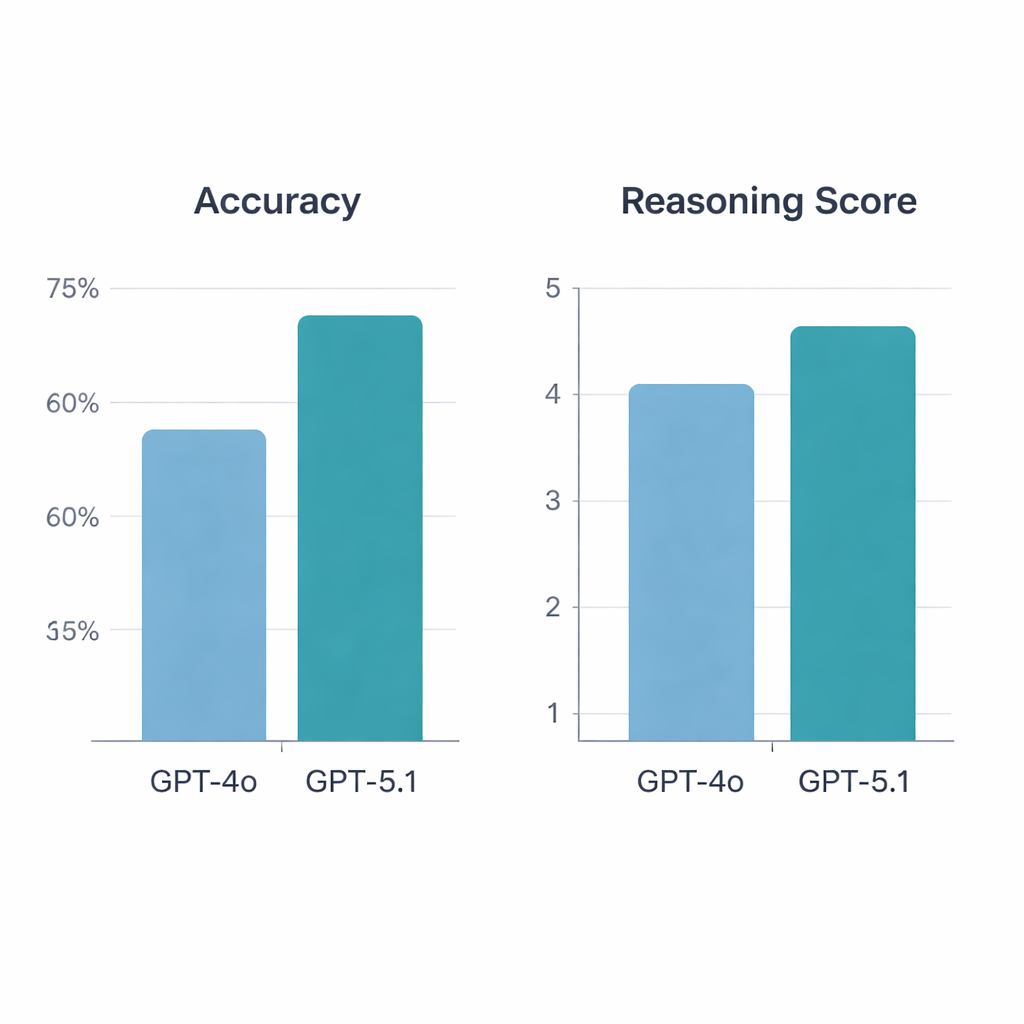
GPT‑5.1 явно превзошёл GPT‑4o. По 197 валидным вопросам GPT‑4o дал 64,5% правильных ответов, тогда как GPT‑5.1 достиг 76% — статистически значимый рост. Обе модели правильно ответили на 113 вопросов и ошиблись в 34, но только GPT‑5.1 решила дополнительно 36 вопросов, которые пропустила GPT‑4o; GPT‑4o оказалась уникально правильной лишь в 13 случаях. Когда ревматологи оценивали объяснения, GPT‑5.1 снова опередил конкурента: средний балл рассуждений составил 4,47 из 5 против 4,13 у GPT‑4o, и GPT‑5.1 получил больше высших оценок. В отличие от GPT‑4o, качество рассуждений которого варьировало в зависимости от того, касался ли вопрос базовой науки, клинического случая, диагностики или лечения, GPT‑5.1 демонстрировал более равномерные результаты по всем категориям.
Сильные стороны, пробелы и расхождения между экспертами
Исследование выявило значимые нюансы. Даже если итоговый ответ модели был неверным, специалисты порой оценивали её рассуждения как достаточно связные, что подчёркивает разрыв между экзаменационной оценкой и клиническим мышлением в реальной практике. В то же время согласие между оценщиками‑ревматологами оказалось лишь умеренным, что показывает: сами клиницисты расходятся во мнениях о том, что считать «хорошим рассуждением». Язык тоже, по‑видимому, имеет значение: предыдущие работы на английском и испанском отмечали более высокие результаты у похожих моделей, что указывает на то, что ИИ по‑прежнему лучше работает с крупными мировыми языками, чем с персидским. Авторы подчёркивают, что эти чат‑боты способны генерировать правдоподобные объяснения, которые могут скрывать фактические ошибки, и что их производительность может меняться по мере обновления систем.
Что это значит в будущем
Для непрофессионального читателя вывод таков: новое поколение чат‑ботов на базе ИИ становится лучше в решении специализированных медицинских экзаменов на персидском, но оно ещё не готово заменить серьёзную подготовку и экспертную оценку. GPT‑5.1 может быть полезным партнёром при подготовке для обучающихся ревматологов — суммировать темы, проходить клинические случаи и предлагать структурированные объяснения — но ему не следует доверять как окончательному источнику для решений с высоким риском, касающихся диагностики или лечения. Авторы призывают к более масштабным многоязычным исследованиям, повторному тестированию во времени и реалистичным клиническим симуляциям, чтобы определить, как эти инструменты можно безопасно интегрировать в медицинское образование и в повседневную помощь пациентам.
Цитирование: Rafiei, F., Sadeghipour, S., Sheikhalishahi, S. et al. Evaluation of large Language model performance on Persian rheumatology board exams: accuracy and clinical reasoning of GPT-4o vs. GPT-5.1. Sci Rep 16, 7274 (2026). https://doi.org/10.1038/s41598-026-38716-z
Ключевые слова: ревматология, персидское медицинское образование, большие языковые модели, клиническое рассуждение, сертификационные экзамены