Clear Sky Science · ru
Сеть многоуровневого слияния признаков с управлением энтропией для высокоточного поиска изображений по содержанию
Быстро находить нужную картинку
Ежедневно мы создаём и сохраняем невероятное количество фотографий — от медицинских снимков и спутниковых изображений до записи с камер наблюдения и личных фото. Ручная разметка и поиск по таким коллекциям медленны и ненадёжны. В этой статье предложен более умный способ, позволяющий компьютерам «рассматривать» изображения напрямую и с высокой точностью находить нужные кадры даже в очень больших и разнородных хранилищах.
Почему одних пикселей недостаточно
Традиционный поиск по изображениям часто опирается на имена файлов или простые метки вроде «кошка» или «здание». Люди не всегда тщательно помечают снимки, а компьютеры видят лишь сырые пиксели, а не тот богатый смысл, который выводит человек. Ранние системы, ориентированные на содержимое, пытались сократить разрыв, используя простые визуальные признаки, такие как цвет, текстура и форма. Эти признаки помогали, но обычно их объединяли с фиксированными весами. Это означало, что системе приходилось считать какие‑то признаки всегда более важными, даже если для конкретного запроса оптимальна была бы другая комбинация. В результате точность падала при смене типов изображений, освещения или сцен.
Слияние множества способов «видеть»
Авторы предлагают новую схему поиска, которая объединяет два основных типа визуальных свидетельств. Во‑первых, используются модели глубокого обучения — известные сети вроде ResNet50 и VGG16, научившиеся распознавать сложные паттерны на изображениях. Во‑вторых, добавляются классические «ручные» дескрипторы, фиксирующие распределения цвета, контуры и текстуры в более контролируемой форме. Вместо того, чтобы заранее угадывать, насколько важен каждый тип признаков, система позволяет данным решать это. Она измеряет, насколько информативен каждый признак для данного запроса, и динамически корректирует их влияние. Такое многоуровневое сочетание высокоуровневых и низкоуровневых сигналов даёт компьютеру более богатое и гибкое представление о содержимом изображения.
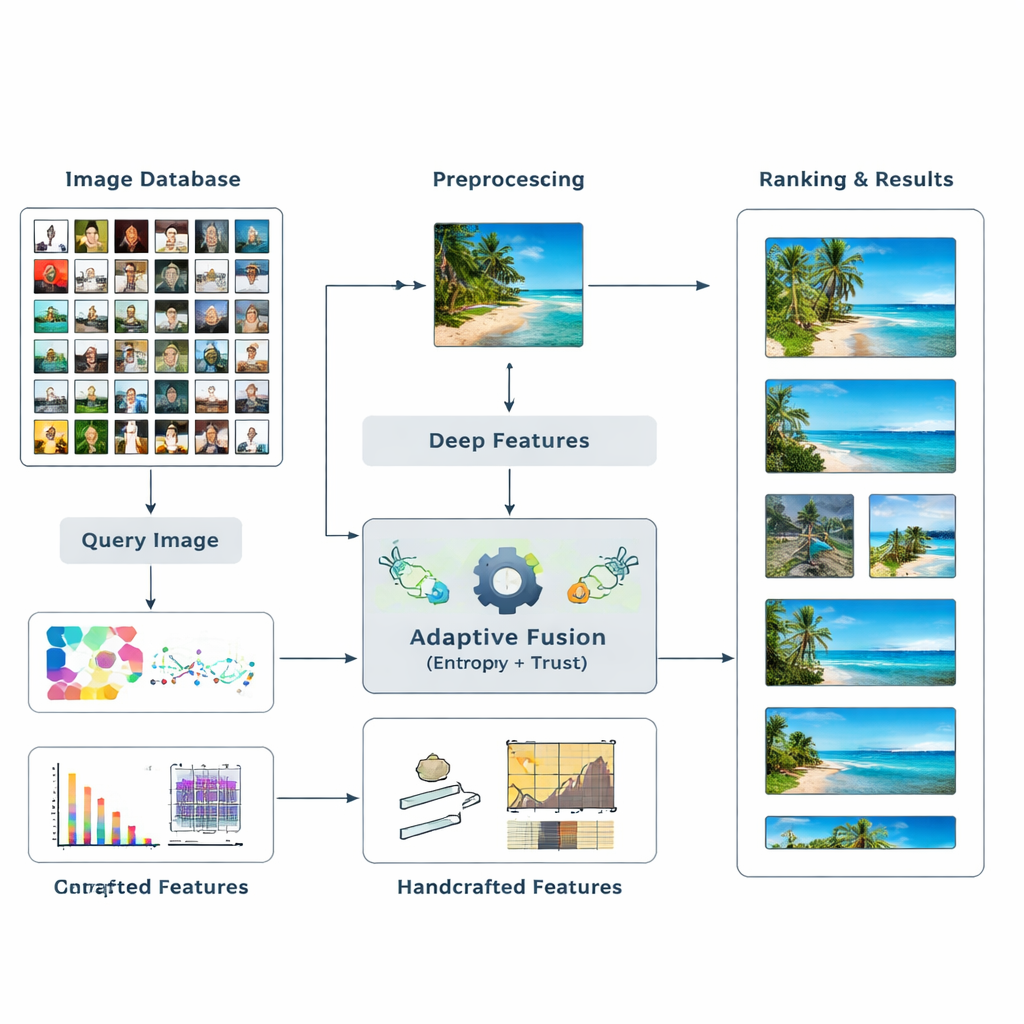
Пусть информация и доверие задают веса
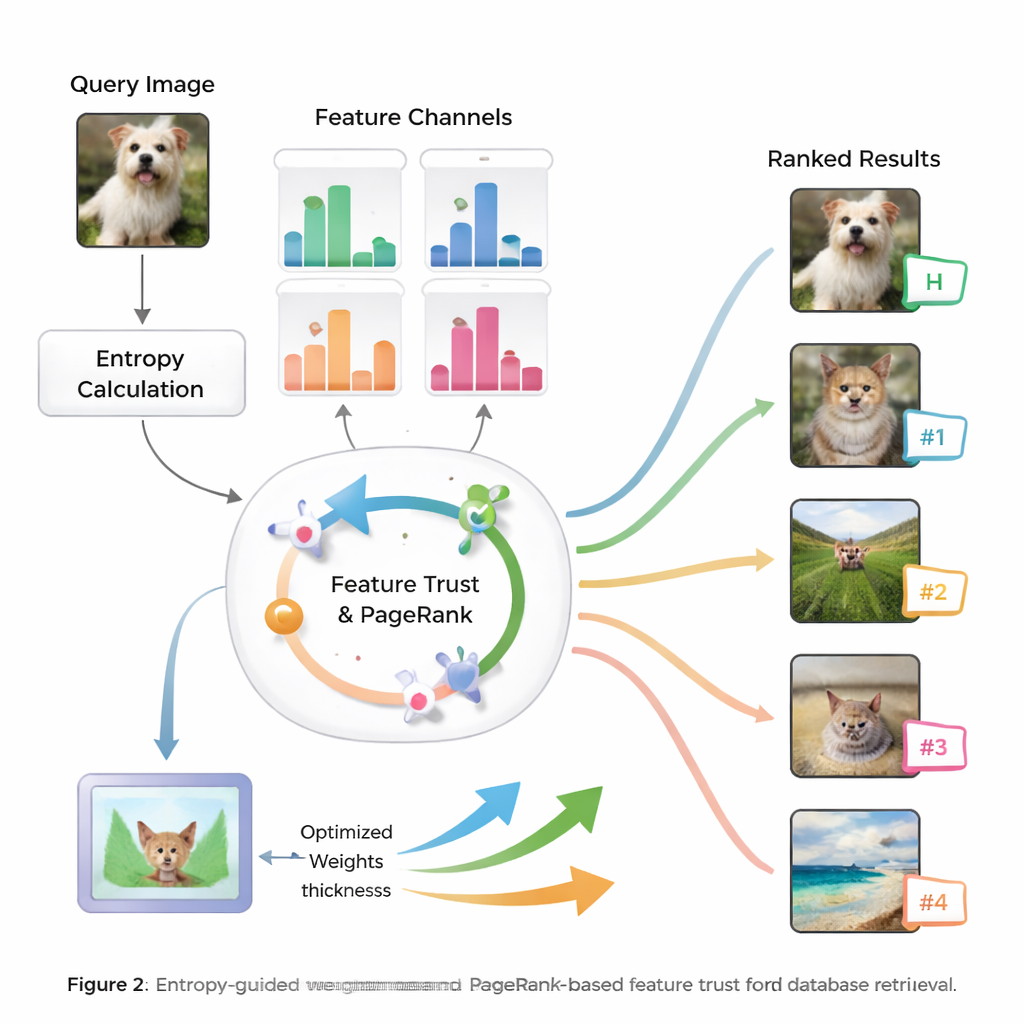
В основе метода лежит идея энтропии — меры неопределённости или разброса информации. Признаки, которые последовательно отделяют релевантные изображения от нерелевантных, имеют более низкую энтропию и рассматриваются как более «дискриминативные». Для нового запроса система оценивает поведение каждого признака по всей базе данных и присваивает ему начальный балл важности. Затем она анализирует надёжность результатов, которые даёт каждый признак — действительно ли верхние совпадения похожи на запрос — формируя понятие «доверия» к каждому типу признака. Эти оценки доверия подаются в процесс, подобный PageRank, аналогичный тому, как ранние веб‑поисковики определяли важность страниц, чтобы уточнить веса признаков через сеть вероятностных переходов.
От умных весов к лучшей сортировке
Когда система узнала, насколько можно доверять каждому признаку для текущего запроса, она объединяет их показатели сходства в единый итоговый скор для каждого изображения в базе. Изображения затем ранжируются по этому комплексному показателю, и те, которые соответствуют запросу наиболее содержательно, оказываются вверху списка. Авторы протестировали подход на общепринятых наборах данных для поиска изображений и сравнили его с несколькими существующими методами. Они сообщают о приросте до 8,6% в mean average precision и заметных улучшениях качества первых десяти результатов, как в точности, так и в релевантности порядка. Статистические тесты показывают, что эти улучшения вряд ли случайны, что говорит о том, что система точна и стабильна для разных типов изображений.
Что это значит для повседневного поиска изображений
Проще говоря, исследование показывает, как сделать поисковые системы изображений, которые адаптируются к каждому запросу, а не полагаются на жёсткие правила. Позволяя информационному содержанию и заслуженному доверию решать, какие визуальные подсказки важнее, система чаще находит правильные изображения — будь то отпечаток пальца в огромной базе криминалистических данных, конкретное здание на спутниковом снимке или нужный медицинский скан. Авторы признают, что метод вычислительно более тяжёлый, чем простые системы, но утверждают, что его повышенная надёжность и точность делают его пригодным для больших критически важных хранилищ изображений, где действительно важно получить правильную картинку.
Цитирование: Lavanya, M., Vennira Selvi, G., Gopi, R. et al. Entropy guided multi level feature fusion network for high precision content based image retrieval. Sci Rep 16, 7449 (2026). https://doi.org/10.1038/s41598-026-38699-x
Ключевые слова: поиска изображений по содержанию, глубокое обучение, слияние признаков, поиск изображений, взвешивание по энтропии