Clear Sky Science · ru
Предварительная подготовка на ImageNet и двухэтапный перенос обучения при классификации изображений хромосом
Более чёткие представления о наших хромосомах
Наши хромосомы несут инструкции по созданию и функционированию организма, и врачи изучают их форму, чтобы выявлять генетические нарушения и некоторые виды рака. Сегодня компьютеры могут помогать анализировать изображения хромосом, но обучить их этому непросто: медицинские снимки редки и сильно отличаются от обычных фотографий. В этом исследовании поставлен простой, но практически важный вопрос: могут ли компьютеры учиться лучше на близких медицинских изображениях, а не только на огромных коллекциях фото кошек, собак и машин?
Почему важны снимки хромосом
В клиниках специалисты располагают 46 хромосом человека в таблицу, называемую кариотипом, разбивая их на 24 типа (22 пронумерованных пары плюс X и Y). Тонкие тёмные и светлые полосы вдоль хромосом помогают обнаруживать отсутствующие или лишние фрагменты, связанные с такими состояниями, как синдром Дауна или некоторые лейкемии. Традиционно эксперты классифицируют эти полосы визуально — это медленно и субъективно. Глубокое обучение предлагает способ автоматизации, но такие системы обычно стартуют с моделей, предварительно обученных на ImageNet — огромном наборе бытовых снимков. Прыжок от фотографий с отпуска до микроскопических изображений хромосом огромен, и неясно, насколько такой опыт действительно переносим.
Двухэтапный учебный «костыль»
Исследователи протестировали более адаптированный путь обучения, называемый двухэтапным переносом. Вместо того чтобы сразу переходить от ImageNet к задаче классификации хромосом, они сначала дообучали модели, уже обученные на ImageNet, на изображениях хромосом, полученных одним методом окрашивания, а затем снова дообучали на втором, слегка отличающемся методе. Были использованы два открытых набора данных: изображения в Q-окраске, которые хуже по качеству и труднее для чтения, и G-окраске, которые чище и детальнее. Каждый набор поочерёдно служил «ступенькой» для другого. Идея похожа на изучение языков: если вы уже знаете испанский, учить итальянский может быть проще, чем сразу переходить с английского.
Тестирование множества «компьютерных глаз»
Чтобы понять, когда этот дополнительный шаг полезен, команда обучила 66 разных классификаторов, сочетая 11 популярных архитектур нейросетей с тремя стратегиями: обучение с нуля, дообучение только с ImageNet и использование двухэтапного переноса. Эффективность измеряли с помощью Macro-F1 — метрики, которая справедливо учитывает все типы хромосом, включая редкие. Сначала они подтвердили, что изображения Q- и G-окраски статистически ближе друг к другу, чем к фотографиям из ImageNet, что делает их перспективными промежуточными ступеньками. Затем сравнили, насколько хорошо разные модели обучаются при каждой стратегии на лёгком (G) и сложном (Q) наборах.
Когда дополнительный шаг окупается
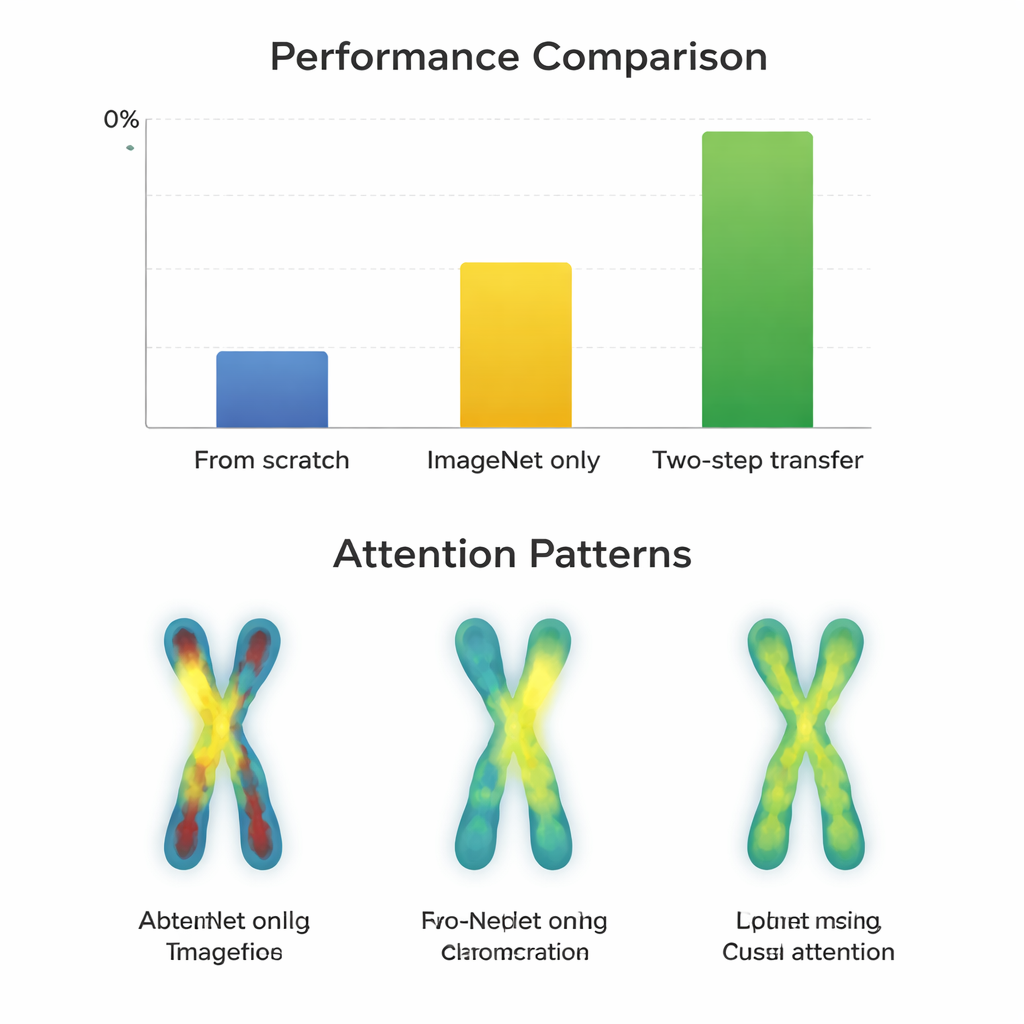
На более качественных G-изображениях почти все модели уже демонстрировали отличные результаты после простого дообучения с ImageNet, с показателями около 97–98 процентов. Здесь двухэтапное обучение приносило лишь незначительные улучшения — часто менее одного процентного пункта — а иногда даже ухудшало результат для старых архитектур. В отличие от этого, на более сложных Q-изображениях картина изменилась. Современные компактные архитектуры, такие как ConvNeXt, Swin Transformer, Vision Transformer и MobileNetV3, явно выигрывали от двухэтапного подхода, улучшаясь примерно на 0,8–3,3 процентных пункта по сравнению только с ImageNet. Визуализации внимания показали причину: при двухэтапном переносе сети распределяли фокус более равномерно вдоль полос на обеих плечах хромосомы, а не только по контуру или одной области. Однако очень большие старые сети вроде VGG не получали выгоды и иногда работали хуже, что указывает на то, что умная архитектура может превзойти простую громоздкость.
Ограничения, заданные самими данными
Исследователи также проанализировали ошибки на G-изображениях. Некоторые промахи были связаны не со стратегией обучения, а с дефектами входных данных, например с плохой обрезкой хромосом при разделении перекрывающихся фигур. В таких случаях все методы обучения испытывали трудности, а карты внимания были разбросаны или зацикливались на вводящих в заблуждение краях. Это подчёркивает практическое послание для клиник и разработчиков: даже лучшая схема обучения не способна полностью компенсировать плохое качество изображений или ошибки предобработки, особенно при работе с относительно малыми наборами данных, доступными для снимков хромосом.
Что это значит для реальной диагностики
Для неспециалистов главный вывод таков: разумное повторное использование родственных медицинских изображений может повысить точность автоматического чтения хромосом — особенно когда целевые данные шумные или редки и когда используются современные, продуманные нейросети. Для изображений высокого качества стандартного дообучения с ImageNet может быть достаточно. Но когда патологи работают с более сложными наборами данных, дополнительный шаг обучения на близком по типу изображении может «уточнить» компьютерный взгляд, повысив показатели до диапазона 93–98 процентов. Этот подход может быть применим и за пределами хромосом — ко многим областям медицинской визуализации с ограниченным количеством разметки, помогая приблизить надёжные инструменты ИИ к повседневной клинической практике.
Цитирование: Chen, T., Xie, C., Zhang, W. et al. ImageNet pre-training and two-step transfer learning in chromosome image classification. Sci Rep 16, 7572 (2026). https://doi.org/10.1038/s41598-026-38662-w
Ключевые слова: классификация хромосом, ИИ в медицинской визуализации, перенос обучения, модели глубокого обучения, кариотипирование