Clear Sky Science · ru
Использование обработки естественного языка и машинного обучения для выявления хронических заболеваний по электронным медицинским записям в первичной помощи
Почему записи вашего врача важнее, чем кажется
Когда вы приходите к семейному врачу, каждый кашель, жалоба и беспокойство фиксируются в вашей электронной медицинской карте. Большая часть этой информации хранится в свободноформатных заметках, а не в аккуратно отмеченных чек‑боксах. В этом исследовании показано, что такие нарративные записи в сочетании с современными компьютерными методами помогают врачам точнее выявлять хронические болезни — например, артрит, заболевания почек, диабет, повышенное кровяное давление и респираторные проблемы — особенно когда эти проблемы не прописаны явно в других разделах карты.
Скрытые подсказки в повседневных клинических записях
Электронные медицинские записи в первичной помощи содержат два принципиально разных типа информации. Есть структурированные элементы, такие как коды платежей, списки лекарств и результаты лабораторий, а есть неструктурированные заметки, где клиницисты описывают симптомы, анамнез и ход рассуждений обычным языком. В Канаде коды для оплаты часто неполны и используются в основном для выставления счетов, а не для точной диагностики, поэтому многие проблемы здоровья проявляются яснее именно в заметках, а не в чек‑боксах. Исследователи решили проверить, позволит ли объединение обоих типов данных лучше выявлять пять распространённых хронических состояний у пациентов в возрасте 60 лет и старше, посещавших одну клинику семейной медицины в Альберте.

Обучение компьютеров «читать» язык врачей
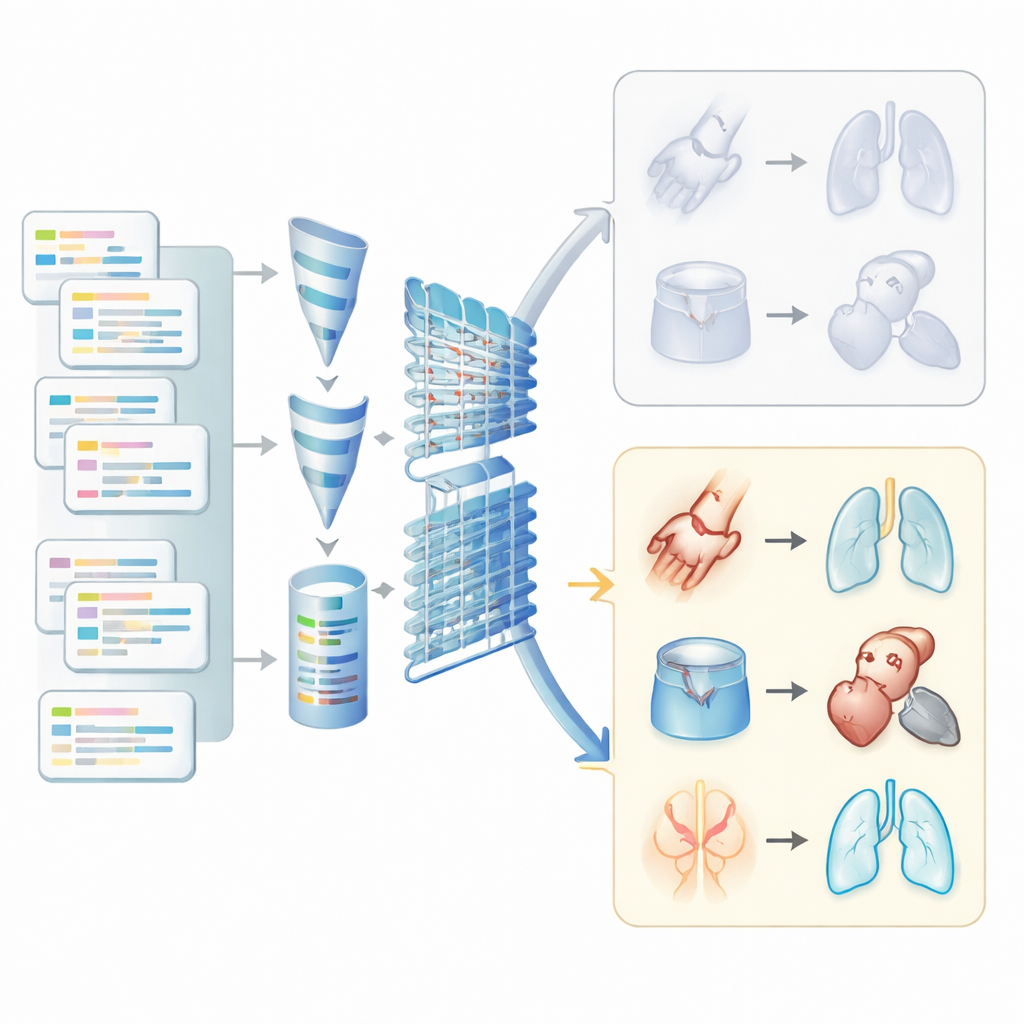
Чтобы извлечь полезную, но шумную информацию из текста клинических заметок, команда применила обработку естественного языка — набор инструментов, позволяющих компьютерам работать с человеческой речью. Они очищали заметки, удаляя посторонние символы, стандартизируя слова, разворачивая аббревиатуры и приводя родственные формы к общим корням. Также были разработаны простые правила, чтобы распознавать, когда в записи говорится, что у пациента нет состояния — например, фразы вроде «нет данных свидетельствующих» или «исключено» — чтобы компьютер не принимал такие случаи за положительные. Клиницисты в команде составили списки значимых терминов и выражений для каждого состояния, помогая алгоритмам фокусироваться на релевантных медицинских понятиях, а не на каждом случайном слове.
Поиск тем и обучение на шаблонах
Затем исследователи количественно представили текст, чтобы его можно было подать в модели машинного обучения. Они считали, как часто каждое слово или пара слов встречается в заметках каждого пациента, при этом понижая вес очень распространённых слов и выделяя те, которые особенно характерны для конкретного состояния. С помощью метода тематического моделирования они проверяли, совпадают ли самые частые группы слов в заметках с интересующими состояниями — например, термины, связанные с диабетом или гипертонией. Этот шаг служил контрольной проверкой, подтверждая, что выявленные компьютером темы соответствуют клиническим знаниям до построения предсказательных моделей.
Позволяя алгоритмам отмечать вероятно больных
Сердцем исследования стало обучение трёх типов моделей машинного обучения решению, имел ли каждый пациент вероятно одно из пяти хронических состояний. Одна модель работала как усовершенствованный калькулятор риска, другая проводила границу между здоровыми и больными случаями, а третья напоминала простую сеть, вдохновлённую работой мозга. Сначала исследователи обучали эти модели, используя только структурированные части записей, а затем вновь обучали их уже на данных, где были и структурированные поля, и обработанные текстовые признаки из заметок. Они также корректировали дисбаланс, связанный с тем, что некоторые болезни встречались реже, аккуратно перебалансируя данные, чтобы редкие состояния не терялись для алгоритмов.
Явная польза от использования полной картины
Когда к моделям добавили неструктурированные заметки, их способность отличать больных от здоровых заметно улучшилась, особенно для проблем, которые часто плохо кодируются в платежных данных. Для артрита и респираторных заболеваний показатели разделения больных и здоровых, а также надёжность выявления истинных случаев значительно возросли. Например, качество обнаружения респираторных проблем и артрита перешло с удовлетворительного на высокий уровень после включения заметок. Прирост для диабета и гипертонии был меньше, поскольку эти состояния уже неплохо отражались в структурированных полях. Интересно, что простые модели часто показывали результаты не хуже, а иногда и лучше, чем более сложная нейронная сеть, что указывает на то, что продвинутое глубокое обучение не всегда необходимо для подобных задач на уровне клиник.
Что это значит для вашего будущего лечения
В целом исследование демонстрирует, что внимание к нарративной части медицинских записей — не только к кодам и лабораторным показателям — может существенно повысить нашу способность находить пациентов с хроническими заболеваниями. Преобразуя свободный текст в машиночитаемые сигналы и объединяя их с уже имеющимися структурированными данными, системы здравоохранения смогут раньше выявлять пациентов с риском, направлять последующее наблюдение туда, где оно наиболее необходимо, и расширять этот подход на другие состояния, которые преимущественно проявляются в письменном описании визита, а не в выпадающих меню.
Цитирование: Zhang, N., Abbasi, M., Khera, S. et al. Leveraging natural language processing and machine learning to identify chronic conditions from primary care electronic medical records. Sci Rep 16, 8441 (2026). https://doi.org/10.1038/s41598-026-38594-5
Ключевые слова: электронные медицинские записи, выявление хронических заболеваний, обработка естественного языка, машинное обучение в здравоохранении, данные первичной медицинской помощи