Clear Sky Science · ru
Интеллектуальная инкрементальная классификация с использованием динамической улучшенной саранчой нейронной сети для потоковых данных
Почему важны постоянно меняющиеся данные
От энергетических сетей и заводов до онлайн-платежей — современные системы генерируют данные каждую секунду. В этих непрерывных потоках данных скрыты ранние предупреждения о сбоях оборудования, кибератаках или надвигающихся скачках цен. Проблема в том, что этот поток информации не останавливается, и его поведение со временем меняется. В статье, кратко изложенной здесь, предложен новый способ обучения нейронных сетей, который позволяет им продолжать обучаться на таких «живых» данных без замедления или потери точности, делая их более полезными для мониторинга и принятия решений в реальном времени.
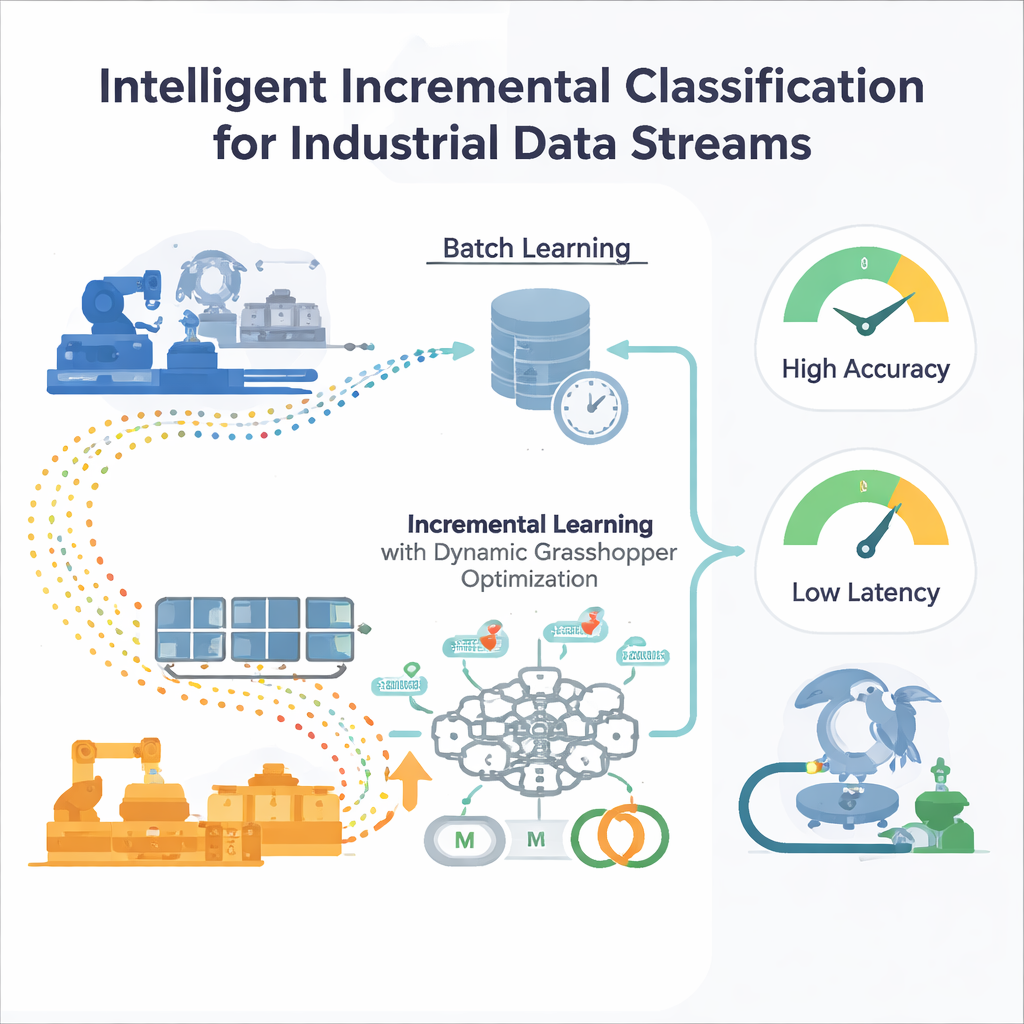
Ограничения одноразового обучения
Большинство традиционных моделей машинного обучения обучаются «пакетно»: инженеры собирают большой исторический набор данных, настраивают модель и затем разворачивают её. Это работает, если мир остаётся примерно неизменным. Но в промышленных условиях условия дрейфуют — меняются образцы спроса, датчики стареют, рынки флуктуируют. Модель, замороженная во времени, постепенно перестаёт улавливать новые закономерности, а повторное обучение «с нуля» на постоянно растущих данных дорого и медленно. Стандартные методы автоматической настройки, такие как перебор по сетке или эволюционные алгоритмы, также предполагают фиксированные данные и требуют перезапуска при смещении распределения, что непрактично для систем, работающих непрерывно.
Нейронная сеть, которая учится на ходу
Авторы предлагают фреймворк инкрементального обучения, основанный на многослойном перцептроне (MLP) — распространённом типе нейронной сети. Вместо того чтобы кормить сеть всеми прошлыми данными сразу, входной поток разбивается на управляемые окна. Каждое новое окно становится небольшим шагом обучения, который обновляет внутренние веса сети и затем отбрасывается — стратегия «обучайся и забывай», сохраняющая память на низком уровне. Ключевое — система не опирается на фиксированные параметры обучения. Два важных регулятора поведения обучения — скорость обучения (насколько большой каждый шаг обновления) и моментум (насколько плавно движутся обновления) — непрерывно корректируются по мере эволюции потока, чтобы модель оставалась отзывчивой, не становясь при этом нестабильной.
Саранча как умные настраиватели параметров
Для управления этой непрерывной подстройкой статья использует натуралистичный оптимизатор под названием Dynamic Grasshopper Optimization Algorithm (DGOA). Представьте рой виртуальной саранчи, исследующей возможные комбинации скорости обучения и моментума. Вначале они широко бродят в поисках хороших областей; позже их движения сужаются, чтобы уточнить перспективные варианты. В этой динамической вариации размер шага и притяжение к лучшему решению меняются со временем в зависимости от того, насколько хорошо работает нейронная сеть. Система также отслеживает «дрейф концепции» — внезапные изменения ошибок предсказания или в самих данных. При обнаружении дрейфа некоторые саранчи сбрасываются, и их шаги временно увеличиваются, что позволяет оптимизатору быстро исследовать новые области и выйти из устаревших настроек.
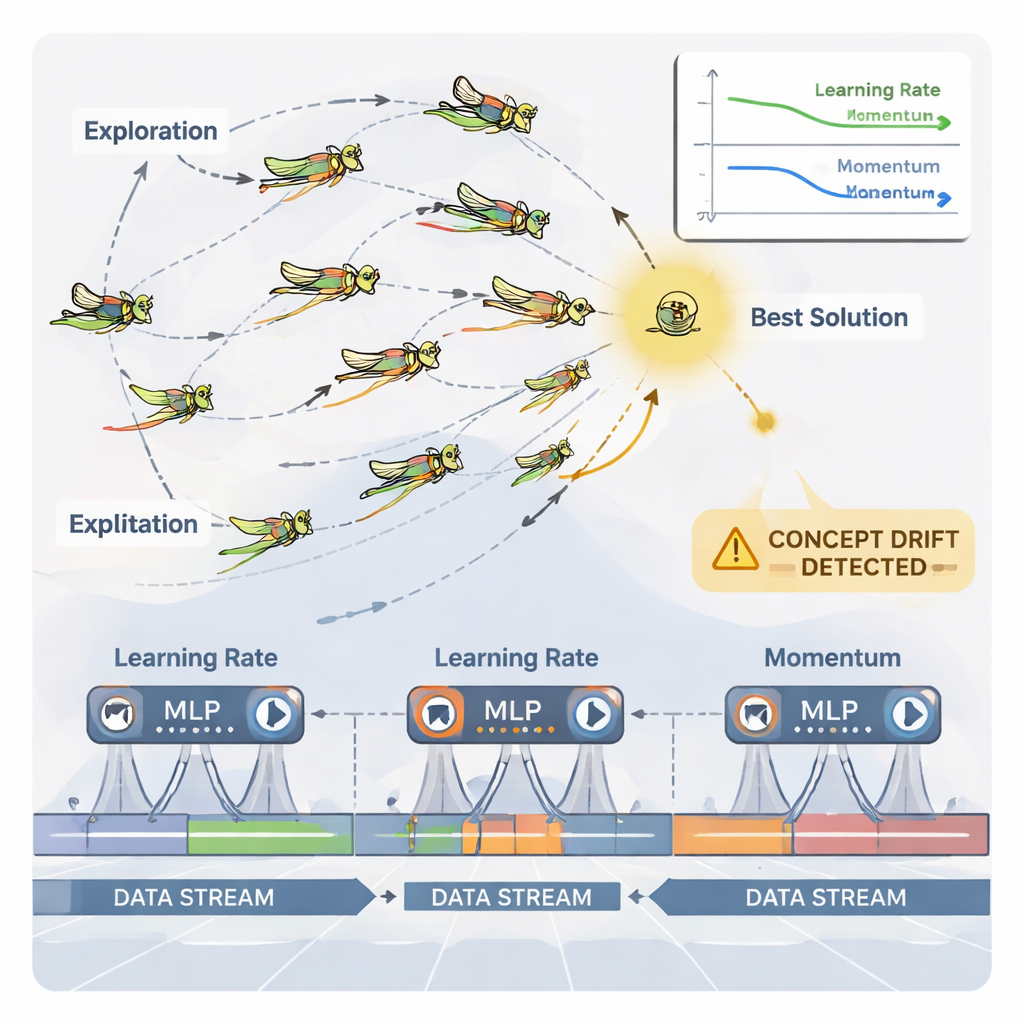
Испытание метода
Исследователи оценили свой подход на реальном наборе данных рынка электроэнергии Австралии, где задача заключалась в прогнозировании движения цен вверх или вниз. По сравнению с распространёнными методами настройки, такими как перебор по сетке, случайный поиск, оптимизация роя частиц, генетические алгоритмы, оптимизация муравьиных колоний и стандартный алгоритм саранчи, динамическая версия в сочетании с инкрементальным обучением показала наивысшую точность (примерно 89,5%), затрачивая при этом меньше вычислительных ресурсов и итераций. Дополнительные эксперименты показали, что метод лучше адаптируется как к устойчивым, так и к меняющимся потокам данных, масштабируется от тысяч до миллиардов образцов при контроле использования памяти и демонстрирует конкурентоспособные результаты в задачах предиктивного обслуживания, обнаружения аномалий и выявления мошенничества, а также на стандартных бенчмарках математической оптимизации.
Что это значит на практике
Для неспециалистов вывод прост: эта работа предлагает способ поддерживать нейронные сети «в живом» и хорошо настроенными в условиях, где данные никогда не прекращаются и условия постоянно меняются. Вместо того чтобы неоднократно останавливать систему для пересборки моделей с нуля, предложённый фреймворк позволяет лёгкой сети обновляться окно за окном, в то время как ройный оптимизатор непрерывно подстраивает, как быстро и как плавно она учится. В результате — более быстрая адаптация к новым закономерностям, лучшая долгосрочная точность и более эффективное использование вычислительных ресурсов — ключевые преимущества для надёжного принятия решений в реальном времени в секторах энергетики, производства и финансов.
Цитирование: Darwish, S.M., El-Shoafy, N.A. Intelligent incremental classification using a dynamic grasshopper-enhanced neural network for data streams. Sci Rep 16, 7730 (2026). https://doi.org/10.1038/s41598-026-38571-y
Ключевые слова: потоки данных, инкрементальное обучение, нейронные сети, оптимизация гиперпараметров, роевой интеллект