Clear Sky Science · ru
Объяснимая гибридная модель CNN–трансформер для распознавания жестового языка на периферийных устройствах с адаптивным слиянием и переносом знаний
Почему важны компактные инструменты для жестового языка
Ежедневные коммуникации миллиардов людей во многом опираются на движения рук, мимику и язык тела, а не на устную речь. Тем не менее большинство телефонов, планшетов и общественных устройств по‑прежнему не способны распознавать жестовые языки, особенно вне англоязычных стран. В этой статье представлена TinyMSLR — компактная и объяснимая система распознавания жестового языка, рассчитанная на работу в реальном времени на небольших энергоэффективных устройствах. Она призвана превратить обычное оборудование в доступные и надёжные средства общения для глухих и слабослышащих людей по всему миру.
Расширение числа языков в диалоге
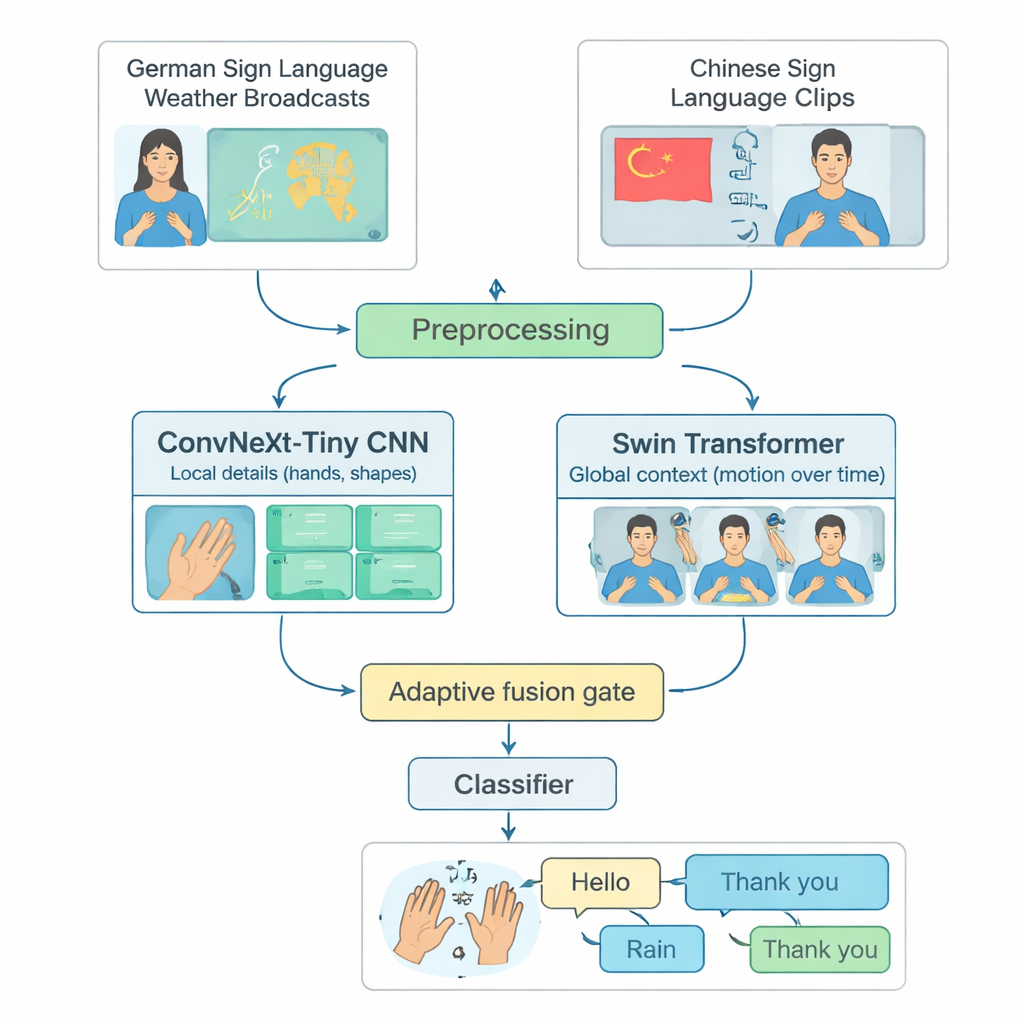
Многие продвинутые системы распознавания жестового языка ориентированы на один язык, чаще всего американский жестовый язык, и работают только на мощных компьютерах. Это исключает людей, использующих другие жестовые языки или живущих в регионах с ограниченными вычислительными ресурсами. Авторы закрывают этот пробел, построив общий тестовый набор на базе двух разных языков: передачи погоды на немецком жестовом языке и крупной коллекции китайского жестового языка. Они тщательно отобрали 20 распространённых повседневных знаков — таких как «Привет», «Погода», «Дождь», «Счастлив», «Да» и «Спасибо» — которые существуют в обоих языках. Обрезая длинные видео до коротких клипов с одним знаком и уравновешивая число примеров по классам и исполнителям, они создают честный, воспроизводимый способ оценить, насколько хорошо модель распознаёт изолированные жесты в разных языках.
Как гибридная модель видит руки и движение
TinyMSLR сочетает два взаимодополняющих подхода к анализу видео. Одна ветвь использует современную сверточную сеть (ConvNeXt‑Tiny), хорошо распознающую мелкие детали, такие как форма пальцев и тонкие текстуры. Вторая ветвь опирается на Swin Transformer — более новую семью моделей, эффективно отслеживающую паттерны в пространстве и времени, то есть как руки, лицо и верхняя часть тела движутся в нескольких кадрах. Каждый короткий видеоклип стандартизируют до 32 кадров размером 224×224 пикселя, применяют мягкие аугментации (например, небольшие повороты или изменения яркости), а затем одновременно подают в обе ветви. Каждая ветвь выдает сводку из 768 чисел; вместе эти сводки фиксируют как чёткие локальные детали, так и более широкий контекст движения.
Позволяя модели выбирать, что важнее
Поскольку одни жесты различаются в основном по форме руки, а другие зависят от широких движений рук или мимики, TinyMSLR не задаёт единого рецепта для комбинирования двух представлений. Вместо этого используется небольшой «шлюз слияния», который обучается подбирать для каждого входного клипа, насколько доверять ветви, ориентированной на детали, по сравнению с ветвью, ориентированной на контекст. Шлюз смотрит на обе сводки признаков и выдает два веса, сумма которых равна единице; итоговое представление — это взвешенная смесь двух ветвей. Во время обучения каждая ветвь также получает собственный небольшой классификатор, чтобы научиться быть полезной самостоятельно, а пара более крупных «учителей» (один CNN, один трансформер) мягко направляет компактную модель, показывая не только правильную метку, но и какие альтернативные метки выглядят схожими. Этот приём, называемый переносом знаний (knowledge distillation), помогает компактной системе приблизиться по точности к тяжёлым моделям, сохраняя при этом малые размер и скорость, подходящие для периферийных устройств.
Понимание, почему система принимает то или иное решение
Помимо чистой точности, авторы подчёркивают, что пользователи и разработчики должны иметь возможность проверять, на что модель обращает внимание. Они применяют SHAP — набор инструментов, присваивающий значимость каждой части входа. На практике объяснения вычисляются по промежуточным признакам и проецируются обратно на кадры в виде тепловых карт и временных графиков. Это выясняет, например, какие кадры и области влияют на решение при различении визуально похожих знаков, таких как «Дождь» и «Снег» или «Холодно» и «Плохо». Агрегирование множества объяснений выявляет более общие закономерности: немануальные признаки, такие как мимика и движения головы, а также ориентация запястья и форма руки, оказываются особенно влиятельными. Эти наблюдения помогают убедиться, что система опирается на содержательные аспекты исполнения жеста, а не на артефакты фона.

Скорость, экономность и пространство для развития
На двуязычном бенчмарке из 20 знаков TinyMSLR достигает примерно 99% точности на обучении и валидации и F1‑метрики около 99%, при этом использует менее 2.7 миллиона параметров и около 1.9 миллиарда операций на клип. На современной GPU распознавание одного знака занимает примерно 13.5 миллисекунды и требует менее 30 миллиджоулей энергии; сохранённая модель весит всего около 7.2 мегабайта. Эти показатели говорят о том, что распознавание жестов в реальном времени на устройстве возможно на недорогих платах и встроенных системах. Авторы отмечают, что их работа охватывает только короткие изолированные знаки и два языка, и что мимика рассматривается неявно, а не как отдельный сигнал. Расширение подхода до более богатых словарей, непрерывных предложений, большего числа языков и явного моделирования мимики и движений головы оставлено для будущих исследований. Тем не менее TinyMSLR демонстрирует убедительный концепт: точные, эффективные и объяснимые инструменты для понимания жестовых языков не обязательно должны находиться в облаке — они могут работать прямо на повседневных устройствах.
Цитирование: Lamaakal, I., Yahyati, C., Maleh, Y. et al. An explainable hybrid CNN–transformer model for sign language recognition on edge devices using adaptive fusion and knowledge distillation. Sci Rep 16, 7143 (2026). https://doi.org/10.1038/s41598-026-38478-8
Ключевые слова: распознавание жестового языка, tiny machine learning, edge AI, объяснимая ИИ, многоязычные модели