Clear Sky Science · ru
SAT: трансформер со сдвигом для видеоочистки без оценки потока
Более чёткие видео из шумных сцен
Тот, кто пытался снимать внутри помещения ночью или на телефон при слабом освещении, знает результат: зернистое, мерцающее видео, где детали будто ползут, а цвета искажаются. В этой работе предложен новый способ очистки таких кадров, превращающий их в более чёткие и стабильные последовательности без опоры на тяжеловесное программное отслеживание движения, которое обычно для этого требуется. Метод, названный Shift Alignment Transformer, разработан так, чтобы сохранять тонкие детали, оставаясь при этом достаточно эффективным для практического использования.
Почему очистка видео так сложна
Удалить шум с одной фотографии уже непросто; то же самое для видео — ещё сложнее. С одной стороны, каждый кадр искажается случайными пятнами и сдвигами цвета. С другой стороны, кадры связаны во времени: объекты движутся, камера дрожит, детали появляются и исчезают. Традиционные методы видеоочистки опираются на оценку движения между кадрами, часто с помощью оптического потока, который пытается отследить, куда перемещается каждый пиксель. Хотя такой подход мощный, оценка движения легко ломается при сильном шуме или быстром сложном движении, к тому же он накладывает серьёзную вычислительную нагрузку, замедляя систему.
Новый способ выравнивания без отслеживания
Вместо того чтобы явно следовать за каждым пикселем, Shift Alignment Transformer (SAT) идёт другим путём: он позволяет сети неявно обнаруживать взаимосвязи между кадрами через аккуратные сдвиги и сравнение признаков. Модель построена вокруг современной архитектуры, известной как трансформер, который хорошо находит дальние связи в данных. В рамках этой схемы авторы вводят пространственно-временной модуль сдвига, который мягко перемешивает информацию по времени и пространству. По времени модель циклически сдвигает признаки кадров, так что слой за слоем каждый кадр «видит» всё дальше в прошлое и будущее. По пространству признаки разделяются на множество небольших групп, и каждая группа сдвигается в разных направлениях. Такое сочетание эффективно имитирует возможные перемещения объектов по видео, позволяя сети выравнивать информацию из разных кадров без явного вычисления поля движения.
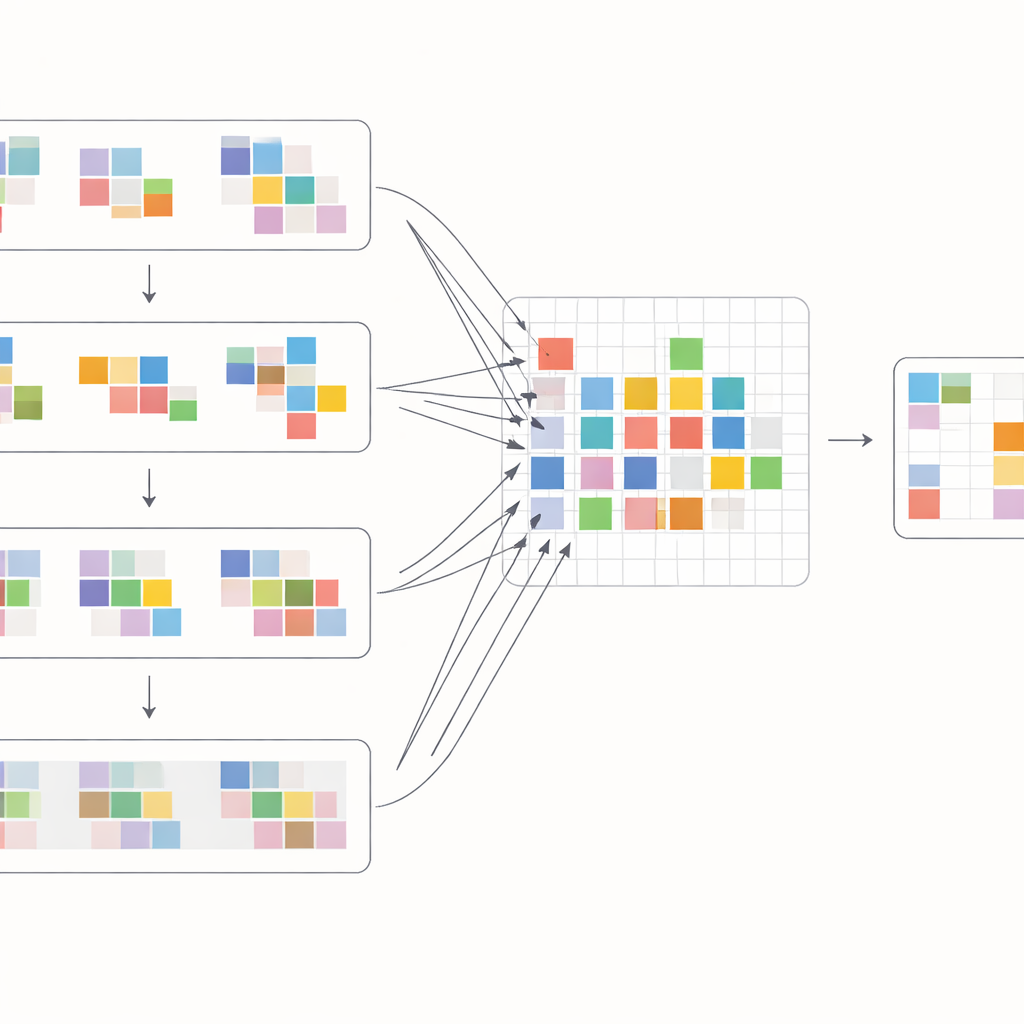
Как работают новые строительные блоки
Чтобы максимально использовать эти сдвиги, авторы разработали специальный блок внимания, который смешивает информацию внутри и между кадрами. Сначала сдвинутые признаки соседних кадров собираются вместе и сравниваются через операцию кросс-внимания: модель учится определять, какие области в других кадрах лучше всего поддерживают текущий кадр в каждой точке. Одновременно отдельная операция внимания фокусируется на связях внутри каждого отдельного кадра, укрепляя локальную структуру и текстуру. Эти два потока затем объединяются и проходят через простые слои обработки в многоуровневой U-образной сети, которая идёт от грубой к тонкой разрешающей способности и обратно. Такое расположение позволяет системе справляться как с крупными движениями камеры, так и с мельчайшими деталями — тонкими краями или мелкими узорами, постепенно восстанавливая очищенную версию каждого кадра.
Насколько хорошо это работает на практике
Исследователи протестировали свой подход на двух требовательных наборах данных. Первый включает чистые видео, искусственно испорченные разными уровнями случайного шума, что позволяет точно измерить, насколько восстановленные кадры совпадают с оригиналами. Здесь новый метод стабильно соответствует или превосходит качество ранних сверточных и рекуррентных сетей и близок к лучшим существующим моделям на базе трансформеров при меньших вычислительных затратах. Второй набор использует реальные съёмки с сенсоров при слабом освещении, где шум неравномерный, цветной и гораздо менее предсказуемый. В этом более реалистичном тесте Shift Alignment Transformer уверенно обходит прежнее состояние искусства, давая видео, которые выглядят чище, чётче и более стабильными во времени, с меньшим числом сдвигов цвета и артефактов.
Что это значит для будущих инструментов работы с видео
Проще говоря, авторы показали, что можно эффективно очищать видео без явного отслеживания движения, сочетая продуманные сдвиги по времени и пространству с вниманием для сопоставления признаков. Их Shift Alignment Transformer предлагает хорошее сочетание точности и эффективности, особенно для реального слабого освещения, где традиционная оценка движения хрупка. По мере того как модели на базе внимания становятся более эффективными, подобные методы могут появиться в повседневных камерах и стриминговых сервисах, помогая превращать шумные, тяжёлые для просмотра ролики в плавные, чёткие видео с минимальными усилиями со стороны пользователя.
Цитирование: Zhang, X., Fan, S., Zhang, H. et al. SAT: shift alignment transformer for video denoising without flow estimation. Sci Rep 16, 8207 (2026). https://doi.org/10.1038/s41598-026-38431-9
Ключевые слова: очистка видео от шума, трансформер, шум изображения, видео при слабом освещении, компьютерное зрение