Clear Sky Science · ru
MDI-YOLO: легковесная модель на базе трансформера и свёрточной сети для многомерного объединения признаков при обнаружении мелких объектов
Более чёткое зрение в небе
От мониторинга дорожного движения до реагирования на катастрофы — дроны и спутники всё чаще наблюдают за нашим миром. Тем не менее те объекты, которые нас больше всего интересуют на таких изображениях — крошечные автомобили, люди, лодки и самолёты — часто занимают всего несколько пикселей. В статье про MDI‑YOLO рассматривается простой, но важный вопрос: как компьютеры могут надёжно обнаруживать такие мелкие объекты в реальном времени, даже на маломощных устройствах, установленных непосредственно на дронах?
Почему мелкие объекты трудно заметить
В аэрофотосъёмке и спутниковых кадрах интересующие объекты обычно очень малы, часто расположены плотно и частично скрыты зданиями, деревьями или тенями. Стандартные системы обнаружения сталкиваются с компромиссом: лёгкие модели работают быстро на периферийных устройствах, таких как бортовые компьютеры дронов, но пропускают многие мелкие цели; более тяжёлые и точные модели слишком медленные и требовательные к ресурсам, чтобы быть практичными в полевых условиях. Мелкие объекты также склонны сливаться со сложным фоном — представьте серые машины на серых дорогах — поэтому их отличительные признаки легко теряются при сжатии изображения и обработке глубокими сетями.
Новое сочетание глобального и локального зрения
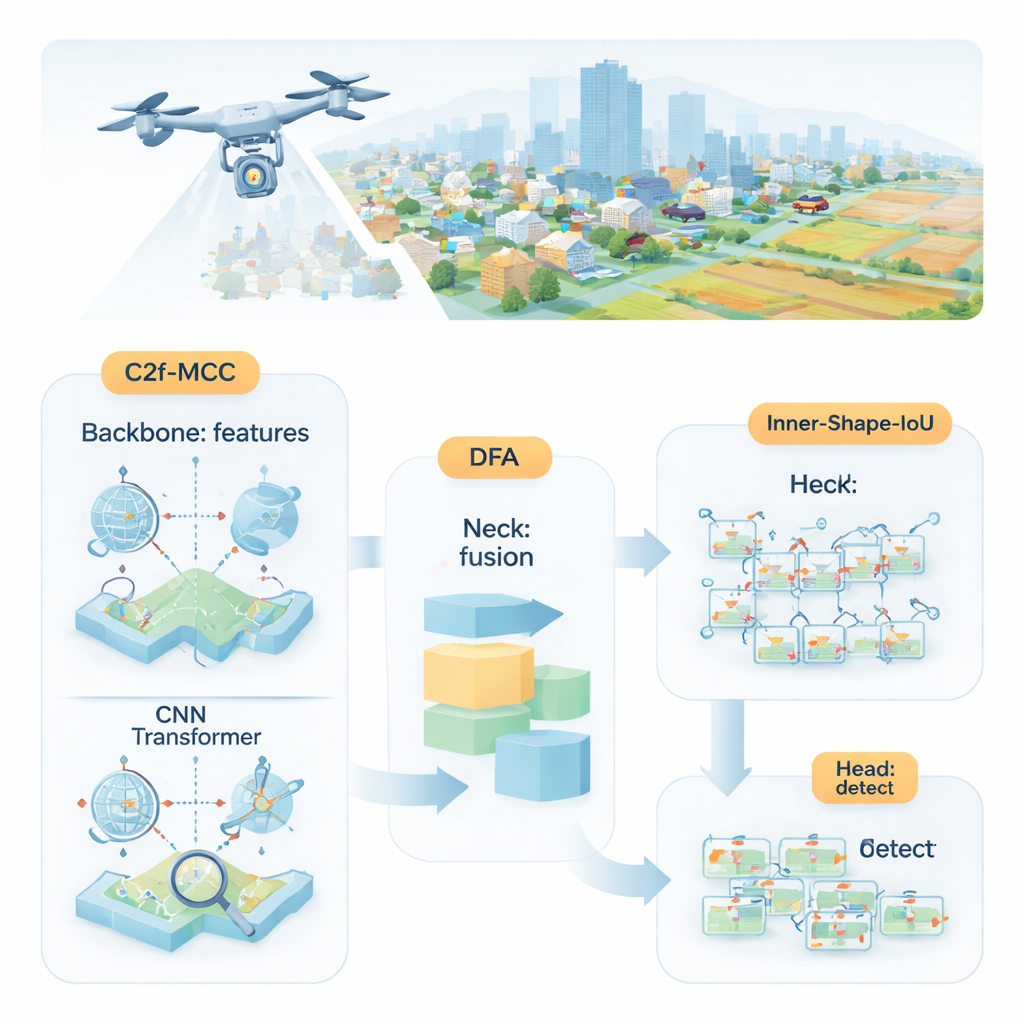
Авторы предлагают MDI‑YOLO, переработанную версию популярного детектора YOLOv8, которая сохраняет компактность модели и одновременно повышает её способность находить крошечные цели. В основе — новый строительный блок под названием C2f‑MCC, который разделяет визуальную информацию, проходящую через сеть, на два пути. Один путь использует обработку в стиле трансформера, хорошо улавливающую дальнодействующие связи по всему изображению — например, как кластер пикселей вписывается в более широкую дорогу или взлётно‑посадочную полосу. Другой путь опирается на классические свёрточные фильтры, превосходные в выделении локальных деталей, таких как края и текстуры. Группируя каналы и пропуская только часть данных по более тяжёлому трансформерному пути, модель получает глобальный контекст без значительного увеличения размера и замедления.
Помощь сети в фокусировке на важном
Даже с улучшенными строительными блоками сеть всё ещё должна решить, где обращать внимание. Чтобы направлять этот процесс, авторы вводят механизм, который называют Directional Fusion Attention (DFA). Этот модуль анализирует шаблоны вдоль ширины и высоты изображения, а также общую сводку сцены, и учится взвешивать разные области и каналы признаков. На практике DFA побуждает модель концентрироваться на вероятных областях с объектами — например, на формах, похожих на транспортные средства на дорогах — и принижать повторяющиеся или сбивающие с толку текстуры фона. Такое сочетание пространственной и канальной фокусировки облегчает отделение крошечных целей от загромождённого окружения или фоновых областей с похожим видом.
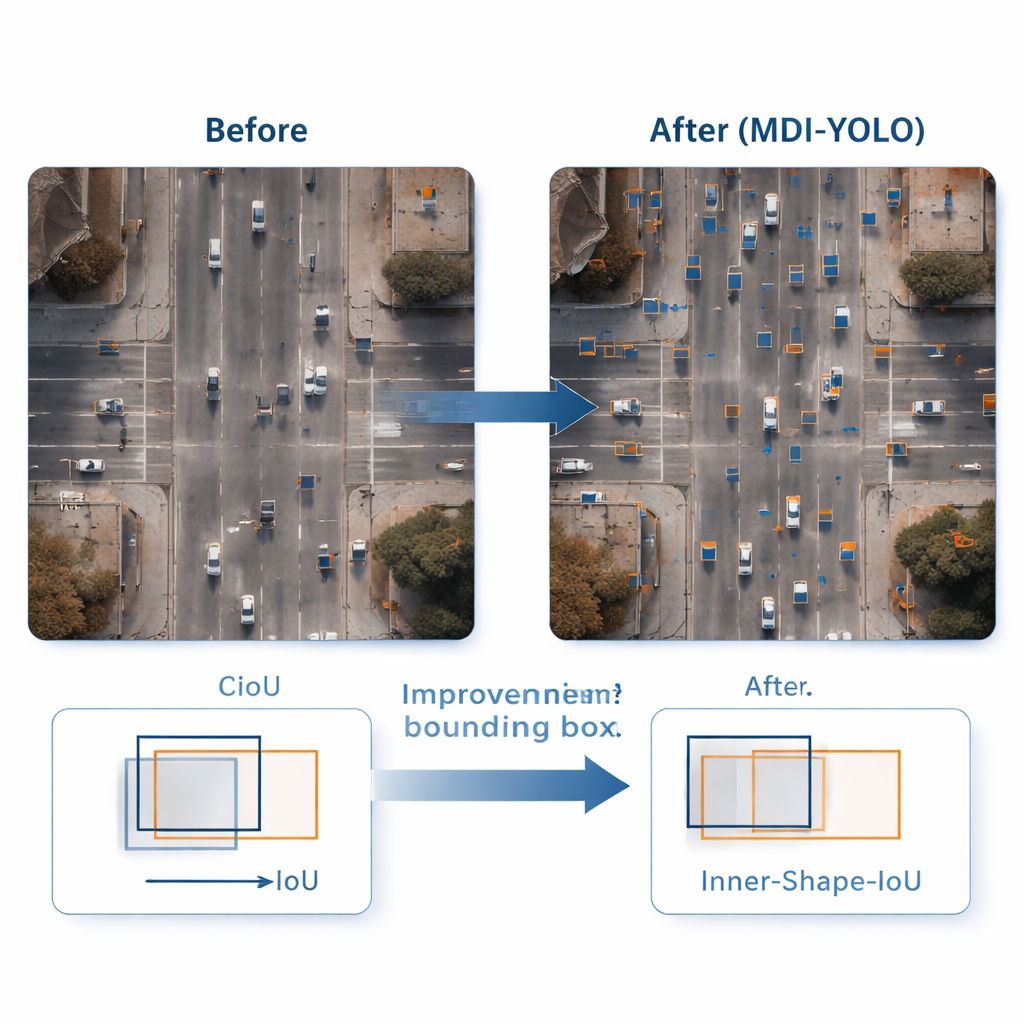
Более точные рамки вокруг крошечных целей
Обнаружить объект — это лишь половина дела; детектор также должен точно его очертить. Стандартные методы обучения сопоставляют предсказанные прямоугольники с истинными по метрике «перекрытие», но она может быть нечувствительна для мелких или необычно вытянутых объектов. Авторы предложили новую функцию потерь Inner‑Shape‑IoU, которая оценивает боксы не только по степени перекрытия, но и по тому, насколько хорошо их форма, размер и центральная область совпадают с реальным объектом. Комбинируя две дополняющие метрики, она наказывает боксы, которые совпадают лишь по краям, но промахиваются мимо ядра цели, что приводит к более точным очертаниям — особенно для мелких, плотно расположенных или вытянутых объектов.
Доказанные выигрыши без лишнего объёма
Чтобы проверить MDI‑YOLO, команда провела эксперименты на двух сложных публичных бенчмарках: VisDrone2019, содержащем кадры дронов городов и дорожного движения, и DOTAv1.0, большой коллекции аэрофотоснимков с множеством мелких, плотно расположенных объектов. Не полагаясь на предварительно обученные модели, MDI‑YOLO повысила стандартные показатели точности на несколько процентных пунктов по сравнению с базовой YOLOv8, при этом число параметров осталось почти неизменным, а время вывода — быстрым. По сравнению с рядом популярных детекторов — от лёгких вариантов YOLO до более тяжёлых систем на базе трансформеров — модель предложила редкое сочетание высокой точности, низких вычислительных затрат и устойчивости в разных сценах.
Что это значит для практического применения
Для неспециалистов вывод простой: MDI‑YOLO даёт дронам и системам дистанционного зондирования более чёткое и надёжное «зрение» без требований к большим и энергоёмким компьютерам. За счёт разумного смешения глобального контекста, локальных деталей, целенаправленного внимания и более взыскательного подхода к обучению ограничивающих рамок метод облегчает обнаружение мелких объектов, важных для безопасности, мониторинга и картографии. Такой эффективный, высокоточный компьютерный зрительный модуль — важный шаг в сторону более умных воздушных платформ, способных работать автономно, быстро реагировать и широко применяться в реальной практике.
Цитирование: Shi, H., Wu, Y., Xu, Y. et al. MDI-YOLO a lightweight transformer-CNN-based multidimensional feature fusion model for small object detection. Sci Rep 16, 7233 (2026). https://doi.org/10.1038/s41598-026-38378-x
Ключевые слова: съёмка с дронов, обнаружение мелких объектов, дистанционное зондирование, YOLO, компьютерное зрение