Clear Sky Science · ru
Выделение ресурсов с поддержкой цифрового двойника через генеративное состязательное имитационное обучение в сложных сценариях «облако‑edge‑конечные устройства»
Более умные «магистрали» данных для Интернета вещей
По мере того как города, фабрики и дома наполняются подключенными датчиками и устройствами, они генерируют потоки данных, которые нужно обрабатывать быстро и надежно. Отправлять всё на удалённые облачные серверы часто слишком медленно, а крошечные устройства на «краю» сети нередко лишены достаточной вычислительной мощности. В этой статье рассматривается новый способ автоматически направлять и распределять вычислительные, хранилищные и сетевые ресурсы между устройствами, ближайшими edge‑серверами и облаком — так, чтобы интеллектуальные приложения оставались быстрыми и устойчивыми даже в условиях реального мира, где многое непредсказуемо и шумно.
Почему современные методы испытывают трудности
Современные системы часто опираются на глубокое обучение с подкреплением, когда алгоритм обучается методом проб и ошибок с помощью сигналов вознаграждения из среды. В сложных, шумных сетях эти сигналы трудно правильно задать и измерить. Если функция вознаграждения неверна или искажена помехами, система может выработать небезопасное или неэффективное поведение. Многие существующие подходы также предполагают богатые априорные знания о трафике и поведении устройств, которые в реальных промышленных сетях редко доступны. Кроме того, большинство решений оптимизирует лишь один тип ресурса за раз — например, вычислительную мощность — игнорируя хранение или пропускную способность сети, хотя все три вместе определяют реальную производительность.
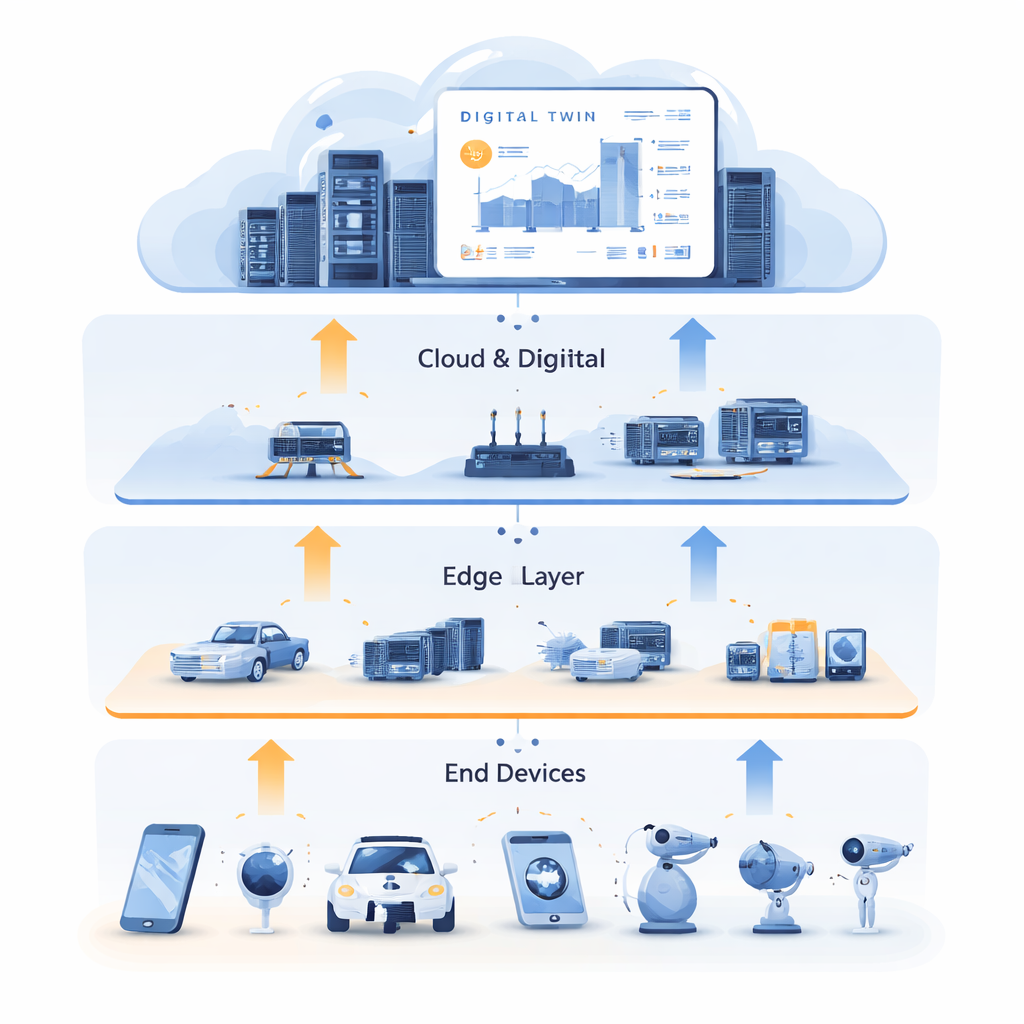
Обучение на цифровом двойнике
Чтобы разрядить этот тупик, авторы объединяют задачу распределения ресурсов с технологией цифрового двойника. Цифровой двойник — это подробная виртуальная копия физической сети, поддерживаемая в облаке. Он зеркалит состояние edge‑серверов, каналов и задач во времени, используя богатые исторические данные от датчиков и журналов. В этой работе цифровой двойник — не просто панель мониторинга; он становится тренировочной площадкой. Система использует прошлые данные для генерации «экспертных» примеров хороших решений, фиксируя, как задачи следует распределять между вычислением и кэшированием и где их обрабатывать для минимизации задержки. Это обучение проходит офлайн, не нарушая работу живых сервисов, и использует обильные облачные вычисления для исследования множества возможных ситуаций.
Имитация вместо проб и ошибок
Вместо того чтобы учиться напрямую по вознаграждениям, предлагаемая модель E‑GAIL применяет имитационное обучение: агент старается вести себя как эксперт. Сначала авторы строят несколько экспертных политик с использованием фреймворка Actor–Critic, дополненного слоем NoisyNet. Введение контролируемого шума в сеть принятия решений позволяет этим экспертам переживать широкий спектр условий — включая возмущения, имитирующие реальные беспроводные помехи и флуктуации нагрузки — так что их траектории становятся более реалистичными. Далее система объединяет несколько одно‑экспертных траекторий в один «мульти‑экспертный» эталон с помощью инструментов теории игр. Ища равновесие Нэша между экспертами, она избегает конфликтов и вырабатывает консенсусную стратегию с более широким покрытием возможных сценариев.
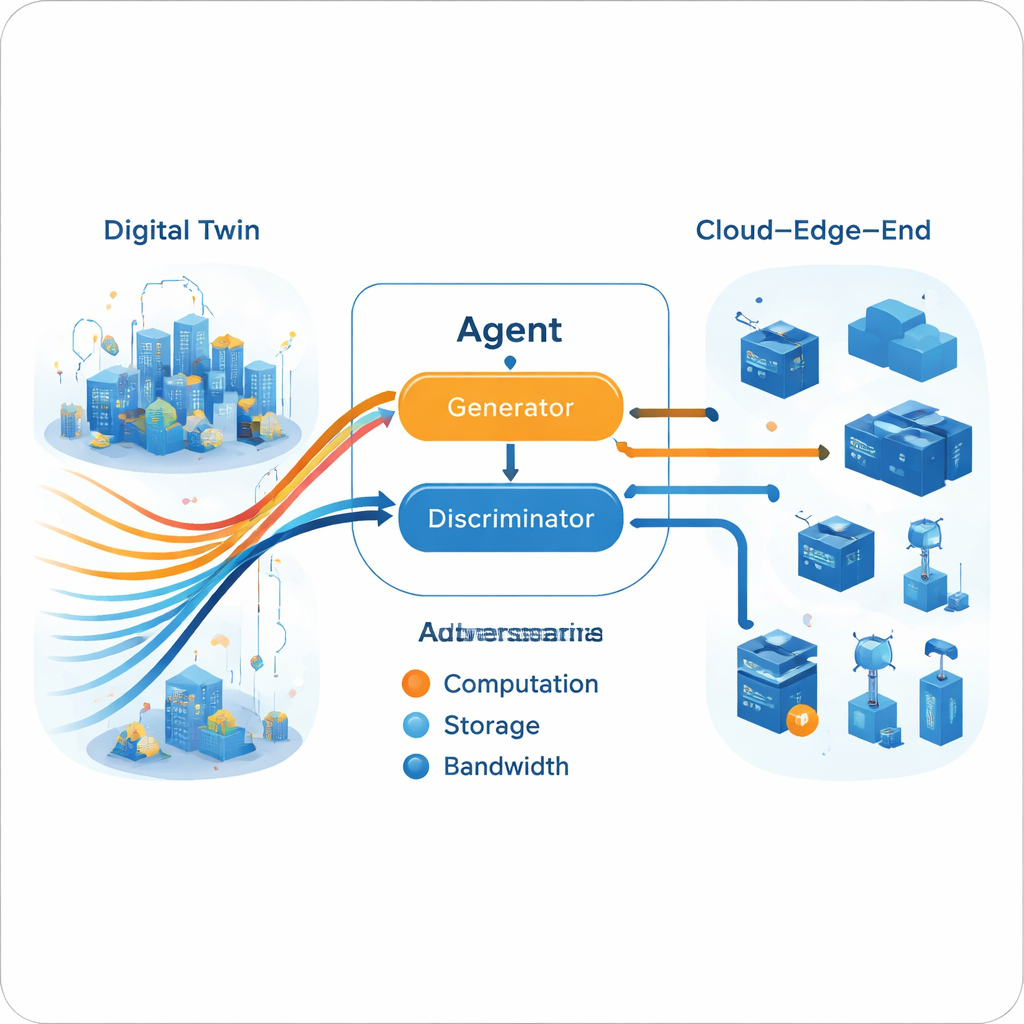
Генеративно‑состязательный механизм принятия решений
Когда мульти‑экспертная траектория построена в цифровом двойнике, реальный агент учится её имитировать с использованием генеративно‑состязательной схемы, сходной по духу с нейросетями, генерирующими изображения. Генератор предлагает действия по распределению ресурсов в текущем состоянии сети, а дискриминатор пытается определить, принадлежит ли последовательность действий агенту или экспертным траекториям. Со временем эта состязательность побуждает генератор выдавать решения, которые дискриминатор не способен отличить от экспертных. Важно, что этому процессу не требуется явная функция вознаграждения из реальной среды. Обучение разделено: тяжёлая офлайн‑обучающая фаза (в облаке) уточняет экспертов и генератор, тогда как более лёгкие онлайн‑обновления (на краю) поддерживают модель в соответствии с текущими условиями, учитывая практические ограничения edge‑оборудования.
Насколько хорошо это работает?
Авторы сравнивают E‑GAIL с несколькими популярными базовыми методами, включая глубокое Q‑обучение, теоретико‑игровые схемы оффлоадинга, жадные эвристики, обработку только в облаке и случайное распределение. Во множестве экспериментов — с варьированием числа конечных устройств, каналов, типов задач, нагрузок, размеров данных, расстояний и моделей шумов — E‑GAIL последовательно достигает сквозных задержек, очень близких к задержкам экспертной политики, и заметно превосходит другие автоматизированные методы. Модель хорошо адаптируется, когда задачи переключаются между вычислительно‑тяжёлыми и ориентированными на хранение, когда сеть расширяется или когда помехи усиливаются. Цифровой двойник ускоряет генерацию экспертных траекторий и повышает их качество, а объединение мульти‑экспертов расширяет набор сценариев, с которыми агент может справляться без обучения с нуля.
Что это значит для повседневных систем
Для неспециалиста ключевая мысль в том, что такой подход позволяет сетям более интеллектуально управлять собой в условиях неопределённости. Вместо ручного создания правил или опоры на хрупкое обучение методом проб и ошибок, E‑GAIL учится на богатом смоделированном опыте, поставляемом цифровым двойником, и на советах нескольких опытных «экспертов», согласованных математическими методами. В результате получается распределитель ресурсов, который быстро принимает решения о том, где запускать задачи и где хранить данные, сохраняя низкие времена отклика даже при меняющихся условиях. В будущих промышленных и умных городских системах такие самостоятельно обучающиеся координаторы смогут незаметно балансировать вычисления, хранение и пропускную способность, делая наш связанный мир быстрее, более надёжным и энергоэффективным.
Цитирование: Zhang, X., Xin, M., Li, Y. et al. DT-aided resource allocation via generative adversarial imitation learning in complex cloud-edge-end scenarios. Sci Rep 16, 7657 (2026). https://doi.org/10.1038/s41598-026-38367-0
Ключевые слова: цифровой двойник, edge‑вычисления, имитационное обучение, распределение ресурсов, Промышленный интернет вещей