Clear Sky Science · ru
Обрезка леса деревьев и повторная выборка для задачи несбалансированных классов
Почему редкие случаи важны в умных прогнозах
Многие решения, основанные на искусственном интеллекте, зависят от обнаружения редкого события: мошеннической операции по карте, раннего признака болезни или опасного отказа в машине. В таких ситуациях важные случаи сильно уступают по численности обычным, и большинство алгоритмов обучения склонны их игнорировать. В этой статье представлен способ сделать один популярный метод, случайные леса, гораздо внимательнее к этим редким, но критически важным случаям — при этом сделав модель компактнее и быстрее.
Проблема неравномерных примеров
Стандартные методы машинного обучения работают лучше всего, когда данные хорошо сбалансированы — когда число примеров для каждого исхода примерно одинаково. На практике же во многих задачах доминируют редкие события. Например, лишь малая часть медицинских снимков показывает опухоль, и лишь крошечная доля транзакций оказывается мошеннической. Такое несоответствие позволяет алгоритму выглядеть хорошо на бумаге, в основном предсказывая распространённый исход, даже если он постоянно пропускает редкий. По мере того как разрыв между частыми и редкими случаями растёт, граница решений модели смещается в сторону большинства, и распознавание редкого класса становится сложнее.
Уравновешивание при помощи умной выборки
Исследователи часто пытаются восстановить баланс в данных перед обучением моделей. Один вариант — сократить класс большинства (under-sampling), отбросив некоторые обычные примеры, чтобы их число приблизилось к числу редких. Другой — копировать или генерировать дополнительные редкие примеры (over-sampling), увеличивая их долю, не теряя исходные данные. Третий, гибридный подход сочетает оба приёма: убирают часть примеров большинства и одновременно усиливают класс меньшинства. У каждого подхода есть компромиссы: сокращение рискует выбросить полезную информацию, а дублирование множества примеров может замедлить обучение и привести к переобучению. Авторы используют все три стратегии, чтобы создавать более ровные обучающие наборы, адаптированные к конкретным данным.
Обучение и обрезка леса решающих деревьев
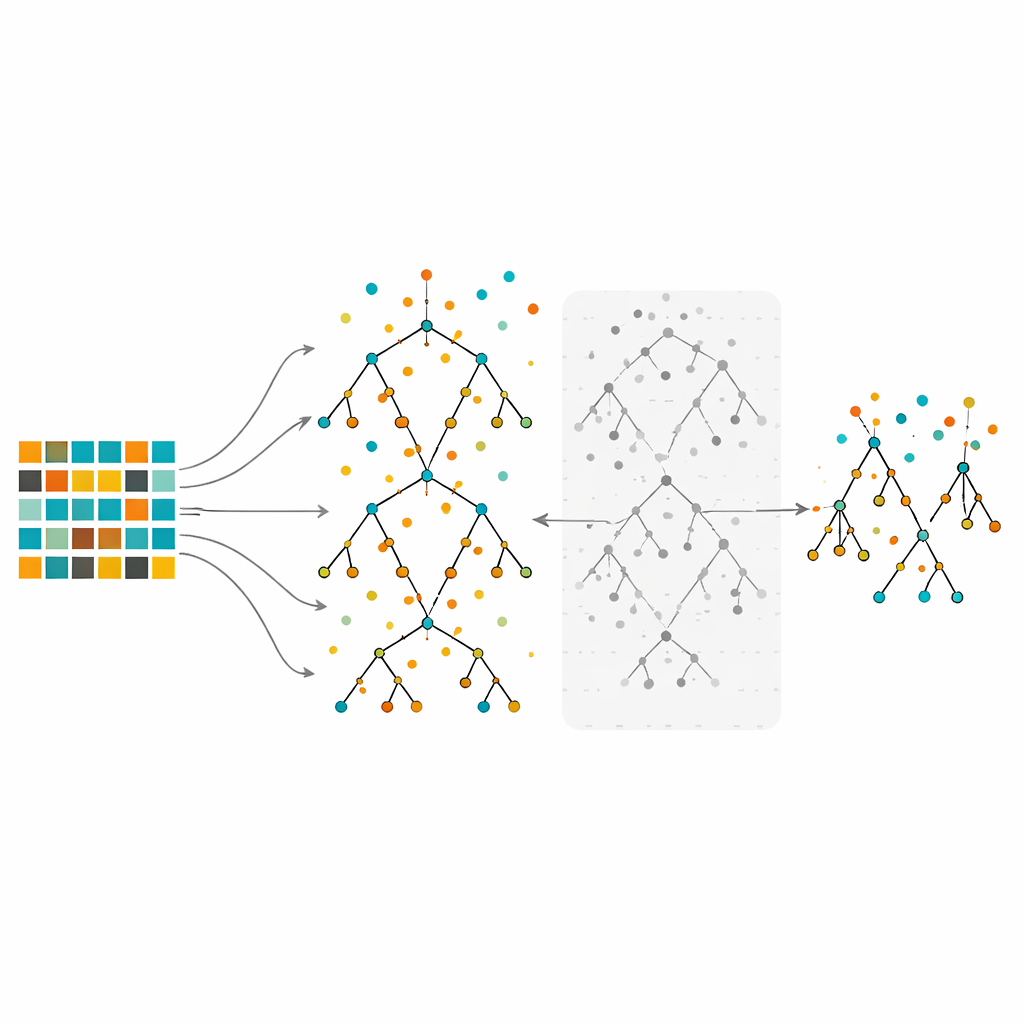
Исследование сосредоточено на случайных лесах — ансамблевом методе, который строит множество деревьев решений на слегка разных подвыборках данных и затем объединяет их голоса. Случайные леса хорошо работают с комплексными данными и помогают выявлять наиболее важные признаки. Тем не менее при обучении на сильно несбалансированных данных даже большие леса могут склоняться в пользу класса большинства. В предлагаемом методе авторы сначала восстанавливают баланс данных с помощью under-sampling, over-sampling или их гибрида. Затем они выращивают множество деревьев по обычной процедуре случайного леса, но с важным дополнением: вместо того чтобы сохранять каждое дерево, они оценивают каждое по отложенным (out-of-bag) наблюдениям — точкам данных, которые не использовались при построении данного дерева — и отбрасывают половину деревьев с наихудшими показателями ошибки. Этот шаг обрезки даёт меньший, более избирательный лес, собранный из наиболее надёжных деревьев.
Тестирование на многочисленных реальных наборах данных
Чтобы оценить работу обрезанного леса, авторы протестировали его на десяти общедоступных наборах данных, отражающих широкий спектр приложений — от медицинских и биологических измерений до фильтрации спама и классификации звуков. Каждый набор содержит два класса, один из которых явно реже другого; наборы различаются по размеру, числу признаков и степени несбалансированности. Новый метод сравнивается с несколькими широко используемыми подходами: k-ближайших соседей, одним деревом решений, стандартным случайным лесом, вариантом Balanced Random Forest и методами опорных векторов. При различных стратегиях выборки обрезанный лес последовательно показывает более низкую ошибку классификации по сравнению с альтернативами на большинстве наборов. Комбинация гибридной выборки и обрезки даёт наилучшие общие результаты и по точности, и по стабильности работы на всех десяти задачах.
Более точные модели, которые тратят меньше ресурсов
Кроме улучшения точности, подход повышает и эффективность. Обрезая менее эффективные деревья, итоговый ансамбль становится компактнее и требует меньше вычислений для обучения и предсказаний, не теряя при этом — а часто и улучшая — способность обнаруживать редкие случаи. Статистические тесты подтверждают, что преимущества перед конкурирующими методами не случайны. Для практиков, сталкивающихся с несбалансированными данными, эта работа показывает: аккуратное выравнивание обучающего набора, а затем обрезка случайного леса на основе out-of-bag показателей может дать модели, одновременно более точные и более эффективные. Проще говоря, метод помогает алгоритмам уделять должное внимание редким, но важным сигналам, скрывающимся в море обычных примеров.
Цитирование: Faiz, N., Iftikhar, S., Jan, S. et al. Pruning tree forest and re-sampling for class imbalanced problem. Sci Rep 16, 8087 (2026). https://doi.org/10.1038/s41598-026-38320-1
Ключевые слова: несбалансированность классов, случайный лес, повторная выборка, машинное обучение, ансамблевые методы