Clear Sky Science · ru
Обнаружение вторжений на основе аномалий в эталонных наборах данных для сетевой безопасности: всесторонняя оценка
Почему умные защиты важны для всех в сети
Каждое отправленное вами письмо, просматриваемое видео или оплаченный онлайн счет проходит через сети, которые постоянно проверяются злоумышленниками. Средства безопасности, называемые системами обнаружения вторжений, действуют как цифровые сигнализации, сканируя трафик в поисках признаков проблем. Но по мере того как атаки становятся разнообразнее и изощреннее, старые инструменты на основе правил всё чаще отстают. В этом исследовании рассматривается, как современные методы глубокого обучения могут обеспечить более точные и адаптивные сигналы тревоги, способные обнаруживать как известные, так и ранее не встречавшиеся угрозы при минимальном количестве ложных срабатываний.
От фиксированных правил к обучению на опыте
Традиционные инструменты обнаружения вторжений работают подобно антивирусному ПО: они ищут известные сигнатуры — специфические шаблоны, соответствующие зафиксированным атакам. Этот подход быстр и надежен для знакомых угроз, но оказывается бессильным, когда злоумышленники меняют тактику или используют так называемые эксплойты нулевого дня. Более новая стратегия — обнаружение аномалий — вместо этого изучает, как выглядит нормальное поведение сети, и помечает необычную активность. Это делает её лучше в ловле новых атак, но повышает риск большого числа ложных тревог. Авторы сосредотачиваются на глубоком обучении, разделе искусственного интеллекта, в котором многослойные сети простых вычислительных единиц автоматически учат шаблоны из данных, стремясь совместить адаптивность обнаружения аномалий с надежностью систем по сигнатурам.
Сравнение двух механизмов обучения
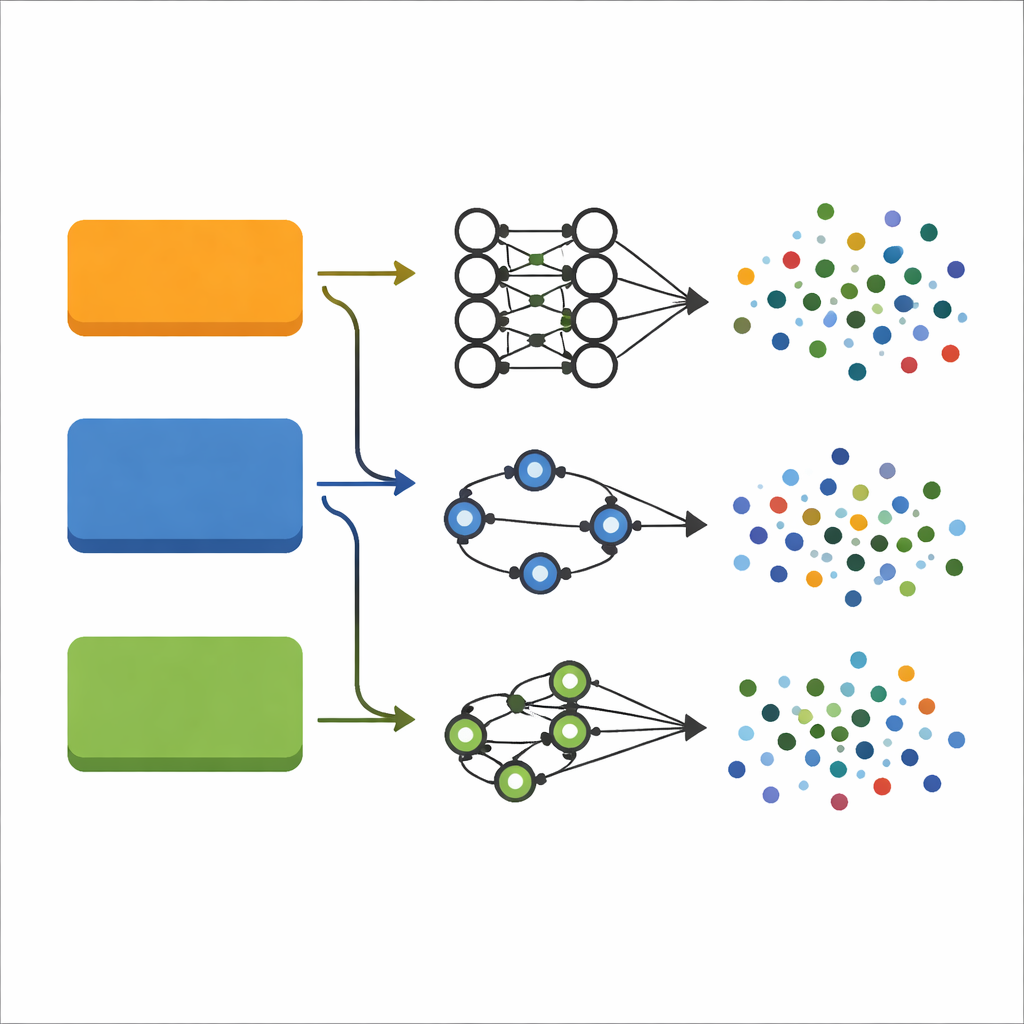
Исследователи оценивают две популярные модели глубокого обучения: глубокую нейронную сеть (DNN), которая обрабатывает каждое сетевое соединение как богатую числовую запись, и рекуррентную нейронную сеть (RNN), добавляющую внутреннюю «память», призванную захватывать зависимости в упорядоченных данных. Вместо ручной разработки признаков они подают этим моделям полные наборы измерений, описывающих каждое соединение, предварительно преобразовав текстовые поля в числа и масштабировав все значения. Обе модели обучаются и тестируются одинаковым образом на трех широко используемых эталонных наборах сетевого трафика: KDDCup99, NSL-KDD и UNSW-NB15, которые вместе охватывают широкий спектр типов атак — от перегрузки сервера трафиком (DoS) до скрытных попыток получить повышенные привилегии.
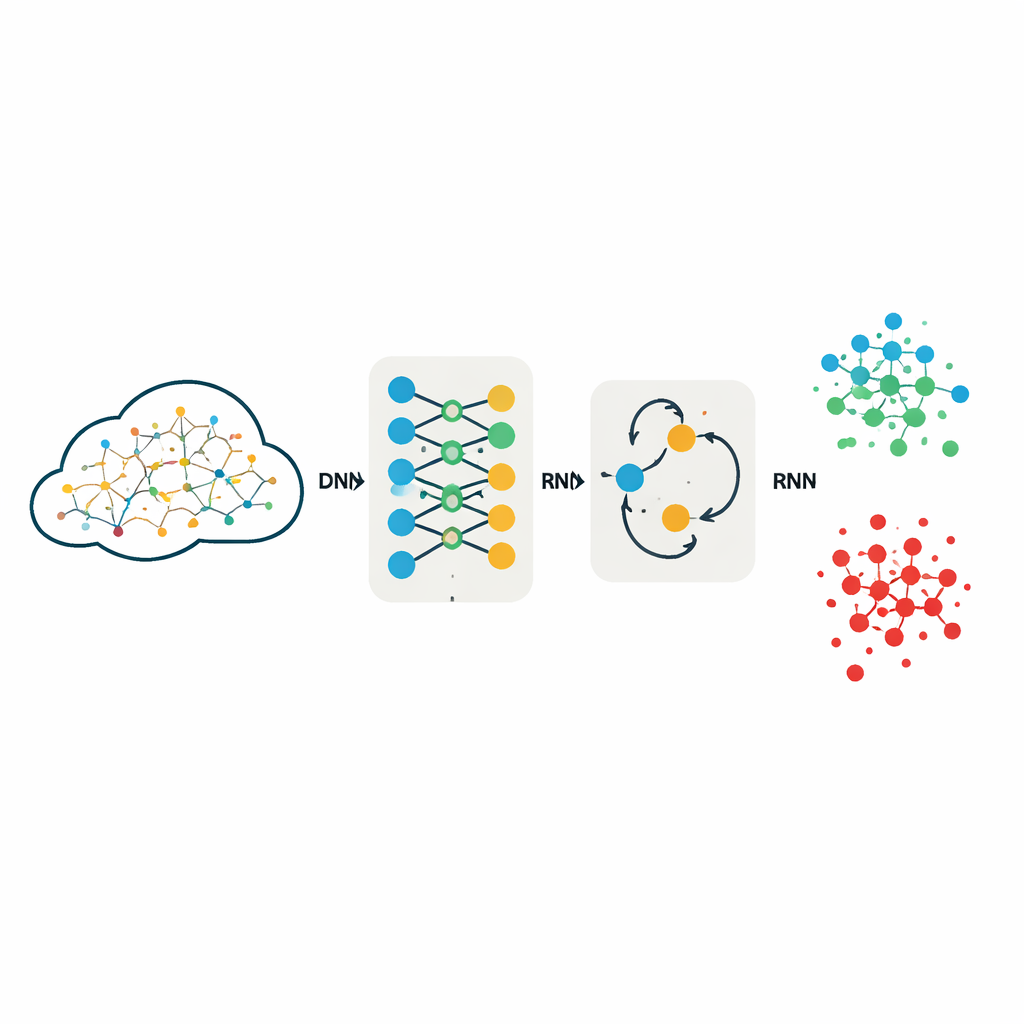
Как тщательно была организована работа
Чтобы сравнение было честным и воспроизводимым, команда намеренно сохраняет дизайн моделей простым и прозрачным. DNN использует три полносвязанных слоя для преобразования 40–42 входных признаков в прогнозы по пяти или десяти категориям трафика, например «нормальный» или различные семейства атак. RNN применяет легковесный рекуррентный слой с последующим слоем принятия решения, рассматривая каждую запись как очень короткую последовательность, чтобы по‑прежнему моделировать взаимодействия между признаками. Обе модели используют одинаковую функцию активации и широко применяемую стратегию оптимизации, известную стабильностью обучения. Важно, что авторы не отбрасывают признаки, чтобы уменьшить объём данных; предыдущие работы показали, что агрессивное сокращение признаков может отбросить тонкие подсказки, важные для различения редких, но опасных атак.
Что говорят результаты об точности и надежности
На старых наборах KDDCup99 и NSL-KDD обе модели демонстрируют впечатляющие показатели: точность превышает 99% при доле ложных тревог ниже 1%. Это означает, что почти все вредоносные соединения правильно обнаруживаются, а очень немногие легитимные соединения ошибочно помечаются. На более современном и сложном наборе UNSW-NB15 с десятью классами производительность снижается, как и следовало ожидать, но остаётся высокой. DNN достигает примерно 96% точности, тогда как RNN отстаёт примерно на 82%. Детализированные показатели показывают, что DNN не только хорошо классифицирует распространённые атаки, но и эффективно справляется с редкими категориями, такими как черви и атаки «пользователь в корень» (user-to-root), демонстрируя высокие F1‑метрики, которые учитывают баланс между обнаружением атак и пропусками. Эксперименты с более сложной моделью на базе трансформеров показали худшие результаты, что говорит о том, что дополнительная архитектурная сложность не гарантирует улучшения безопасности.
Что это значит для безопасности сетей
Авторы приходят к выводу, что хорошо спроектированные, но относительно простые модели глубокого обучения могут стать основой практических систем обнаружения вторжений. Обучая модели непосредственно на полнофункциональных эталонных наборах данных и тщательно настраивая процесс обучения, DNN в частности достигает передовой точности с низким числом ложноположительных срабатываний по широкому спектру типов атак. Для обычных пользователей это означает появление инструментов безопасности, которые лучше замечают как рутинные, так и необычные угрозы, не подавая ложных сигналов постоянно. Авторы предлагают, что будущее исследование может опираться на эту основу, совершенствуя рекуррентные модели, изучая избирательное сокращение признаков для ускорения и комбинируя глубокие извлекатели признаков с традиционными классификаторами, что приблизит нас к обнаружению вторжений, одновременно мощному и эффективному в реальных сетях.
Цитирование: Kumar, L.K.S., Nethi, S.R., Uyyala, R. et al. Anomaly-based intrusion detection on benchmark datasets for network security: a comprehensive evaluation. Sci Rep 16, 8507 (2026). https://doi.org/10.1038/s41598-026-38317-w
Ключевые слова: обнаружение вторжений, сетевая безопасность, глубокое обучение, обнаружение аномалий, кибератаки