Clear Sky Science · ru
Федеративное обучение для гетерогенных систем электронных медицинских карт с экономичным отбором участников
Почему обмен данными между больницами так затруднён
Современные больницы собирают огромные объёмы цифровой информации о пациентах — от лабораторных тестов и показателей жизненно важных функций до назначений и процедур. В теории объединение таких записей из разных учреждений должно позволить врачам создавать более совершенные модели, которые предсказывают риски и помогают выбирать эффективные лечения. На практике же больницы используют разные программные системы, хранят данные в несовместимых форматах и обязаны строго защищать приватность пациентов и бюджеты. В этом исследовании рассматривается, как позволить больницам учиться друг у друга без копирования данных и лишних расходов.
Обучение вместе без передачи исходных записей
Авторы опираются на подход, называемый федеративным обучением: каждая больница обучает локальную модель на собственных записях пациентов и передаёт лишь обновления модели, а не сырые данные. Центральная «хост»-больница координирует этот процесс и стремится улучшить модель прогнозирования для своих задач, например прогноз осложнений в отделении интенсивной терапии. Другие больницы, именуемые субъектами, участвуют в обмене за вознаграждение. Такая схема исключает передачу чувствительных записей между организациями, но вносит две непростые проблемы: как работать с многочисленными разными системами записей и как избежать оплаты партнёров, которые фактически не помогают модели.
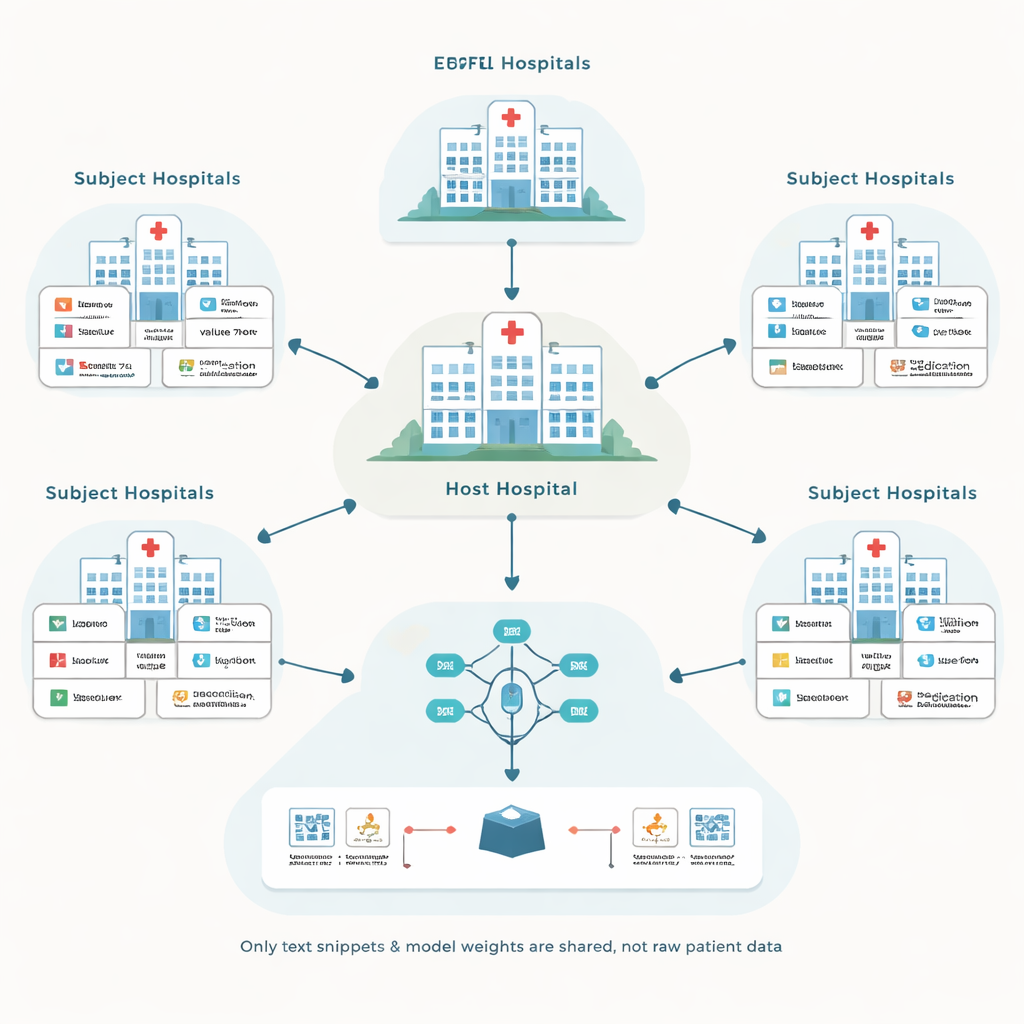
Преобразование разрозненных записей в общий язык
Системы электронных медицинских карт сильно различаются по маркировке и кодировке информации. Одна больница может хранить анализ уровня глюкозы под одним числовым кодом, а другая — под другим. Традиционные решения пытаются привести всё к единому, тщательно продуманному стандарту, что дорого и требует многих часов работы экспертов. Вместо этого предложенная система, названная EHRFL, преобразует каждое медицинское событие в короткий текст. Например, запись лабораторного анализа глюкозы превращается в фразу «lab event glucose value 70 mg/dL». Поскольку у каждой больницы уже есть словари, сопоставляющие локальные коды читабельным именам, такое преобразование можно автоматизировать без ручной тонкой настройки.
Построение профилей пациентов на основе текста
После того как события записаны в текстовом виде, EHRFL использует современные модели обработки языка, чтобы превратить каждое событие в численный вектор, а затем объединяет множество событий в единое «встраивание пациента» — компактное резюме медицинской истории человека за выбранный временной интервал. Эти встраивания подаются на слой прогнозирования, который решает несколько клинических задач одновременно, например прогноз смерти в стационаре или повреждения почек после госпитализации в реанимацию. Авторы проводят федеративное обучение на пяти больших реальных наборах данных из отделений интенсивной терапии, охватывающих разные больницы, периоды и системы записи. Во многих алгоритмах, включая часто применяемые федеративные методы, модели, обученные по текстовому подходу, последовательно превосходят модели, обученные только на данных одной больницы, даже при различиях в форматах данных.
Выбор подходящих партнёров при защите приватности
Больше партнёрских больниц не всегда означает лучшее качество. Некоторые учреждения имеют такие отличия в популяции пациентов или шаблонах записей, что их включение может замедлить обучение или немного ухудшить производительность, при этом увеличивая затраты. Чтобы это предотвратить, авторы предлагают шаг отбора на основе сходства встраиваний пациентов между больницами. Хост сначала обучает модель на собственных данных, делится весами модели, и каждая кандидатная больница использует их для вычисления встраиваний пациентов. Для защиты приватности каждый субъект обрезает экстремальные значения в своих встраиваниях, усредняет их в единый вектор и затем добавляет тщательно скорректированный случайный шум перед отправкой только этого зашумлённого среднего хосту. Хост сравнивает своё среднее с каждым средним субъекта с помощью простых мер сходства и выбирает в полный федеративный запуск только наиболее похожие больницы.
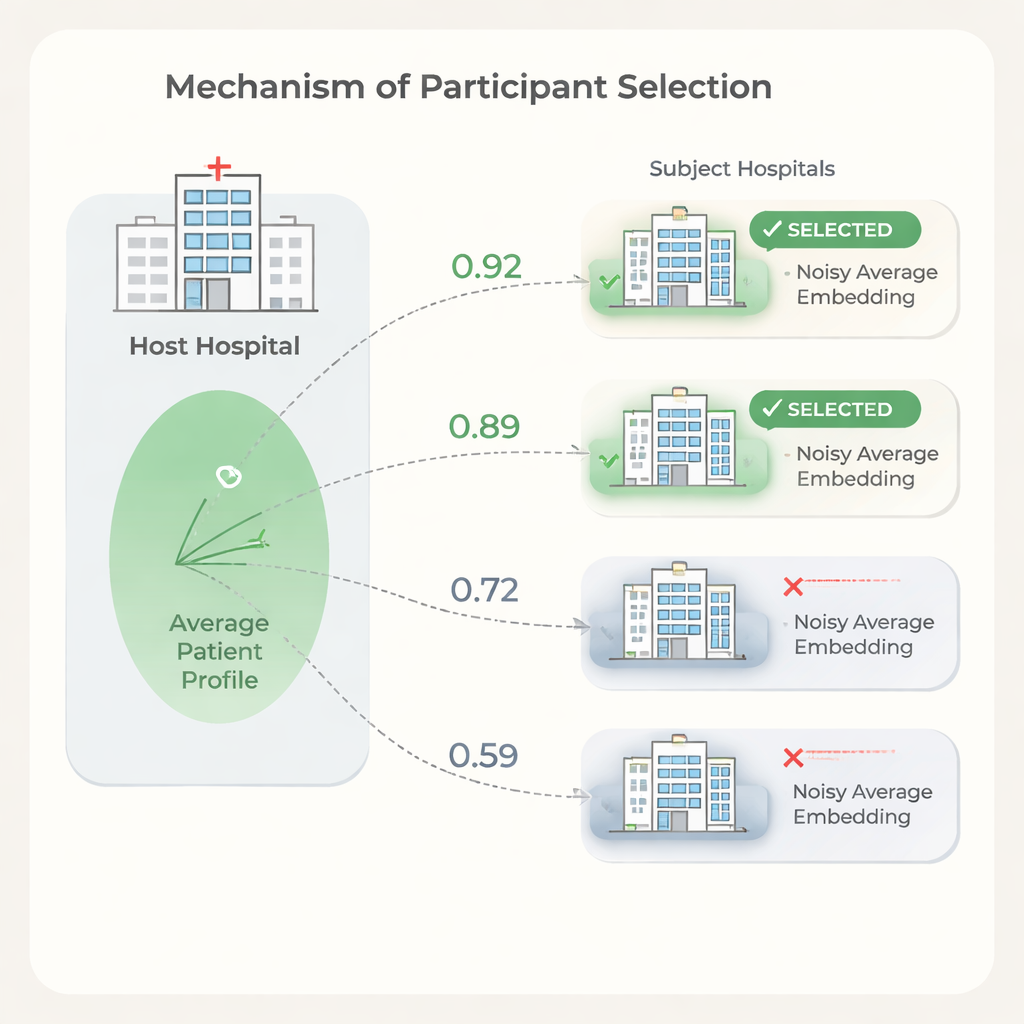
Экономия без потери точности
Эксперименты показывают, что сходство между средними встраиваниями пациентов больниц коррелирует с тем, насколько каждая больница помогает или вредит прогнозной производительности хоста. Используя этот сигнал для отбора партнёров, хост может исключать больницы с низким сходством и при этом сохранять или даже улучшать качество прогнозов по сравнению с использованием всех доступных сайтов. Авторы также приводят модель затрат, показывающую, что поскольку сборы за использование данных и время обучения масштабируются с числом участвующих больниц, даже умеренное сокращение числа партнёров может привести к значительной экономии. При этом шаг отбора лёгок в реализации: модель обучается один раз, и каждая больница выполняет простые вычисления над одним усреднённым вектором.
Что это значит для будущего ИИ в здравоохранении
Для непосвящённых главный вывод таков: возможно, больницы смогут «учиться вместе», не объединяя сырые записи пациентов, и делать это с уважением к приватности и финансовым ограничениям. Переводя разнородные записи в общий текстовый формат и затем используя приватные суммарные описания популяций пациентов для выбора совместимых партнёров, EHRFL предлагает практический рецепт создания специфичных для больницы инструментов прогнозирования. Хотя исследование сосредоточено на данных реанимации, те же идеи могут быть применимы в амбулаториях, отделениях неотложной помощи и даже в немедицинских областях, где организации хотят совместно улучшать модели, не теряя контроля над своими данными.
Цитирование: Kim, J., Kim, J., Hur, K. et al. Federated learning for heterogeneous electronic health record systems with cost effective participant selection. Sci Rep 16, 6876 (2026). https://doi.org/10.1038/s41598-026-38299-9
Ключевые слова: федеративное обучение, электронные медицинские записи, конфиденциальность пациентов, клиническое прогнозирование, искусственный интеллект в здравоохранении