Clear Sky Science · ru
NeuroAction: нейроэволюционный подход к обучению с подкреплением для автономных транспортных средств
Почему важны более умные стили вождения
Большинство из нас представляет себе автопилотированные автомобили как спокойных, идеально рациональных водителей. Однако современные системы обычно стремятся к единой смеси целей — например, не врезаться и при этом довезти вас быстро — и эту смесь задают инженеры. NeuroAction, подход, описанный в этой статье, стремится дать автономным автомобилям нечто, ближе к человеческой гибкости: способность выбирать из множества безопасных стилей вождения, от осторожного «ребенок в машине» до бодрого движения по магистрали, без переработки и повторного обучения каждый раз.
От решения «на всех подряд» к множеству безопасных вариантов
Современные системы глубокого обучения с подкреплением для вождения обучаются методом проб и ошибок: они наблюдают дорогу, выполняют действия — руление и ускорение — и получают единую числовую награду, которая смешивает разные цели, такие как скорость, безопасность и положение в полосе. Чтобы изменить поведение системы, инженерам приходится очень тщательно проектировать эту единую награду. Если придать скорости слишком большой вес, автомобиль станет агрессивным; если переоценить безопасность, он может ползти. Изменение предпочтений позже обычно означает возвращение к переобучению большой нейронной сети с нуля, что занимает много времени, требует много памяти и сильно зависит от настроек.
Разделение вождения на простые цели
NeuroAction решает эту проблему, разбивая задачу вождения на несколько четких целей вместо одной. В исследовании виртуального водителя автомобиля оценивали независимо по трем параметрам: как быстро он передвигается в безопасном диапазоне, насколько точно держится правой (как правило, более безопасной) полосы и насколько успешно избегает столкновений. Вместо объединения этих показателей в один балл метод рассматривает их как отдельные метрики. За кулисами каждая возможная политика вождения — нейронная сеть, превращающая данные с датчиков в решения о рулении и скорости — оценивается одновременно по всем трем осям.
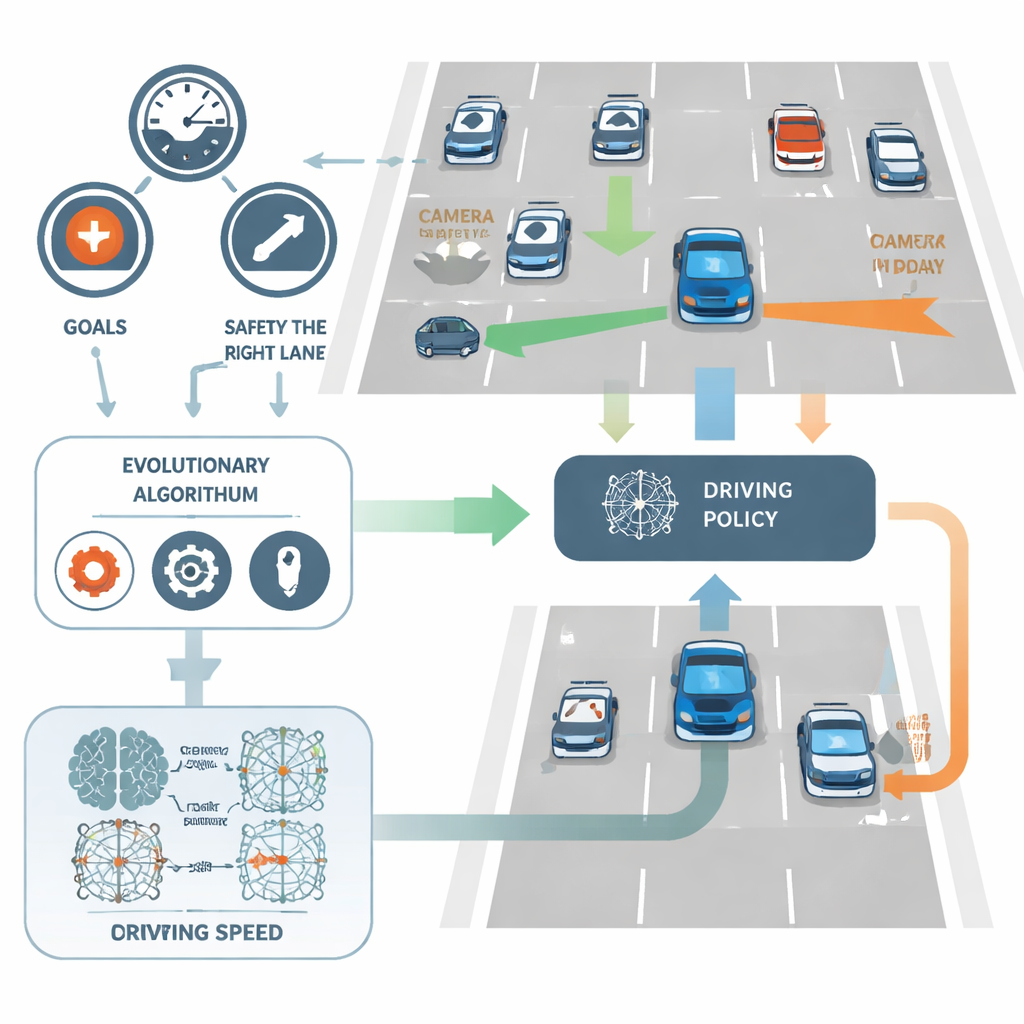
Пусть эволюция ищет лучших водителей
Вместо тонкой настройки весов сети стандартным методом обратного распространения ошибки NeuroAction использует идеи, заимствованные из биологической эволюции. Создается популяция разных политик вождения, которые тестируют в симулированной среде шоссе. Политики, находящие хорошие компромиссы между скоростью, дисциплиной по полосам и безопасностью, сохраняются и комбинируются, а худшие отбрасываются. За многие поколения этот эволюционный процесс обнаруживает целый фронт сильных решений — известный как фронт Парето — где ни одну политику нельзя улучшить по одной цели, не пожертвовав хотя бы одной из остальных.
Сравнение эволюционного и градиентного обучения
Авторы применили NeuroAction к широко используемому 2D-симулятору шоссе, используя стандартного агента на основе нейронной сети. Затем параметры агента оптимизировали с помощью нескольких известных многоцелевых эволюционных алгоритмов, сравнивая, насколько полно каждый из них покрывает спектр желаемых компромиссов. Ключевая мера эффективности — «гиперобъем» обнаруженного фронта — отражает и качество, и разнообразие решений. Один из алгоритмов, NSGA-II, показал наилучшее общее покрытие, в то время как близкий родственник, NSGA-III, дал особенно согласованные результаты при повторных запусках.
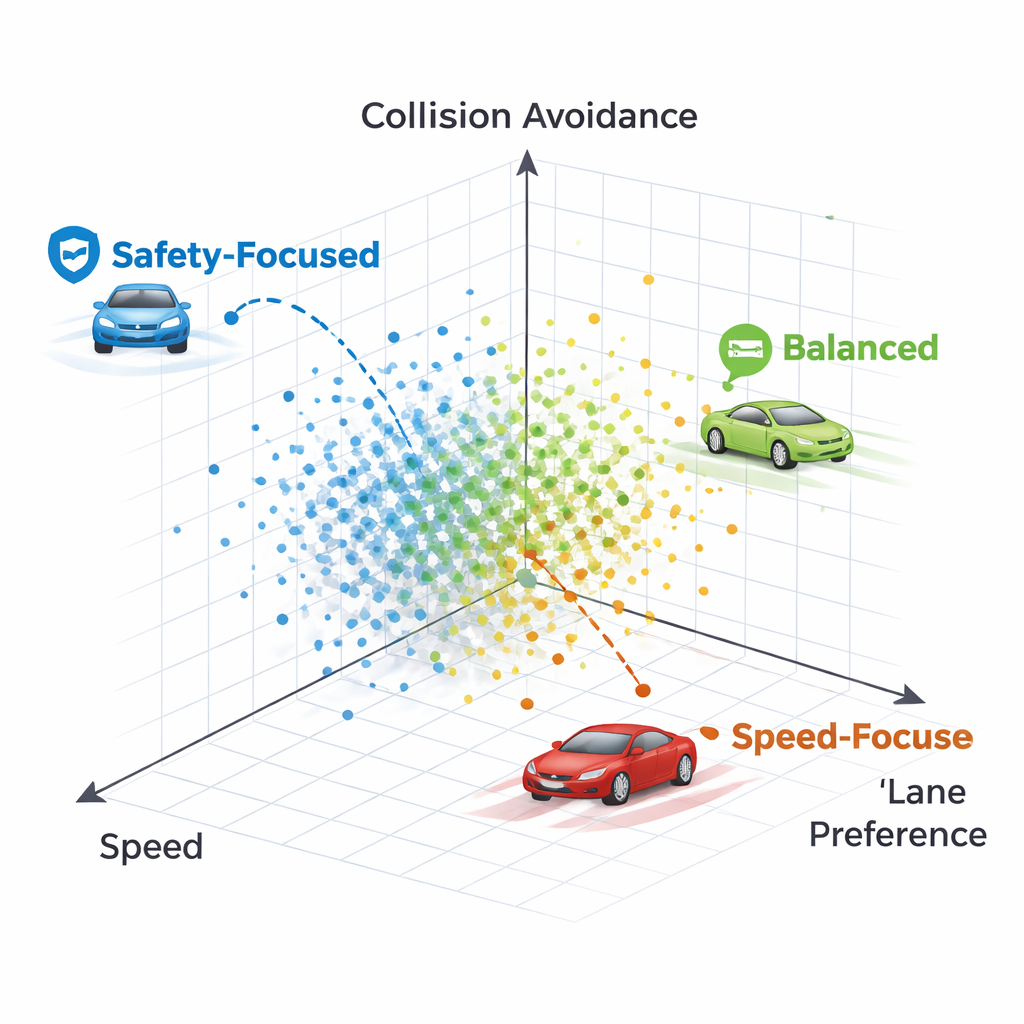
Какие бывают стили вождения
Анализируя отдельные политики на фронте Парето, авторы показывают, что каждая точка соответствует узнаваемому стилю вождения. Одна политика почти любой ценой держится в правой полосе, жертвуя скоростью и в итоге врезаясь в очень медленный впереди идущий автомобиль — чрезмерно осторожная стратегия, которая слишком высоко оценивает предпочтение полосы. Другая политика сначала перестраивается, а затем возвращается в свободную правую полосу, сохраняя более высокую скорость и при этом избегая аварий. В целом методы порождают спектр стратегий — от консервативных водителей, строго держащих полосу, до более напористых, но по-прежнему безопасных крейсеров — все они доступны одновременно без повторного обучения.
Что это значит для будущих автономных автомобилей
Для неспециалиста главная мысль в том, что NeuroAction превращает обучение автономных автомобилей в поиск множества хороших вариантов вместо одного фиксированного поведения. Это позволяет выбирать политику вождения, соответствующую ситуации — медленно и максимально безопасно при перевозке детей, быстрее, когда вы спешите — при сохранении ограничений по безопасности. Хотя текущие эксперименты проводились в симуляции и с упрощенными целями, эта структура указывает путь к более адаптивным, учитывающим предпочтения автономным автомобилям, которые смогут предлагать персонализированные, но надежные стили вождения на прочной математической основе.
Цитирование: Aboyeji, E., Ajani, O.S., Fenyom, I. et al. NeuroAction: a neuroevolutionary approach to reinforcement learning for autonomous vehicles. Sci Rep 16, 7403 (2026). https://doi.org/10.1038/s41598-026-38269-1
Ключевые слова: автономное вождение, обучение с подкреплением, эволюционные алгоритмы, многоцелевой оптимизации, автомобили с автопилотом