Clear Sky Science · ru
Декомпозиция тензора без заранее заданного ранга с помощью метрического обучения
Поиск закономерностей в море данных
Современная наука тонет в сложных данных: стопки медицинских снимков, карты мозговой активности, астрономические изображения и моделирования материалов. Понять эти данные часто означает ужать их в более простые формы, не потеряв при этом важного. В этой статье предлагается новый подход к этой задаче. Вместо того чтобы пытаться восстановить каждый пиксель, он сосредоточен на захвате истинных отношений между образцами — какой мозг похож на какой, какая форма галактики напоминает какую — так что итоговая карта данных отражает смысл, а не просто сырые детали.
От восстановления изображений к измерению похожести
Традиционные инструменты для упрощения многомерных данных, известные как тензорные декомпозиции, работают немного как разложение аккорда на ноты. Они факторизуют «блок» данных на небольшое число базовых шаблонов и веса. Для этого заранее нужно указать, сколько шаблонов — «ранг» — разрешено использовать, а оценка качества строится по тому, насколько хорошо можно восстановить исходные данные. Это идеально для сжатия или удаления шума, но не обязательно для задач вроде «это два лица одного человека?» или «к какому классу относится этот снимок мозга — аутизм или типичное состояние?», где важнее правильная группировка, чем идеальное восстановление.
Параллельно, глубокое обучение популяризировало другую идею: вместо алгебраической декомпозиции тензора учить компактный числовой код, или встраивание (embedding), через нейронную сеть. Классические автокодировщики по-прежнему ориентированы на восстановление. В этой работе цель переворачивается. Предлагается «безранговая» схема, которая не фиксирует ранг заранее и не стремится к точному восстановлению пикселей. Вместо этого она обучает меру расстояния так, чтобы точки, которые должны быть близки (один и тот же человек, тот же диагноз, тот же физический класс), оказывались соседями в пространстве встраивания, а точки, которые должны различаться, отталкивались друг от друга.
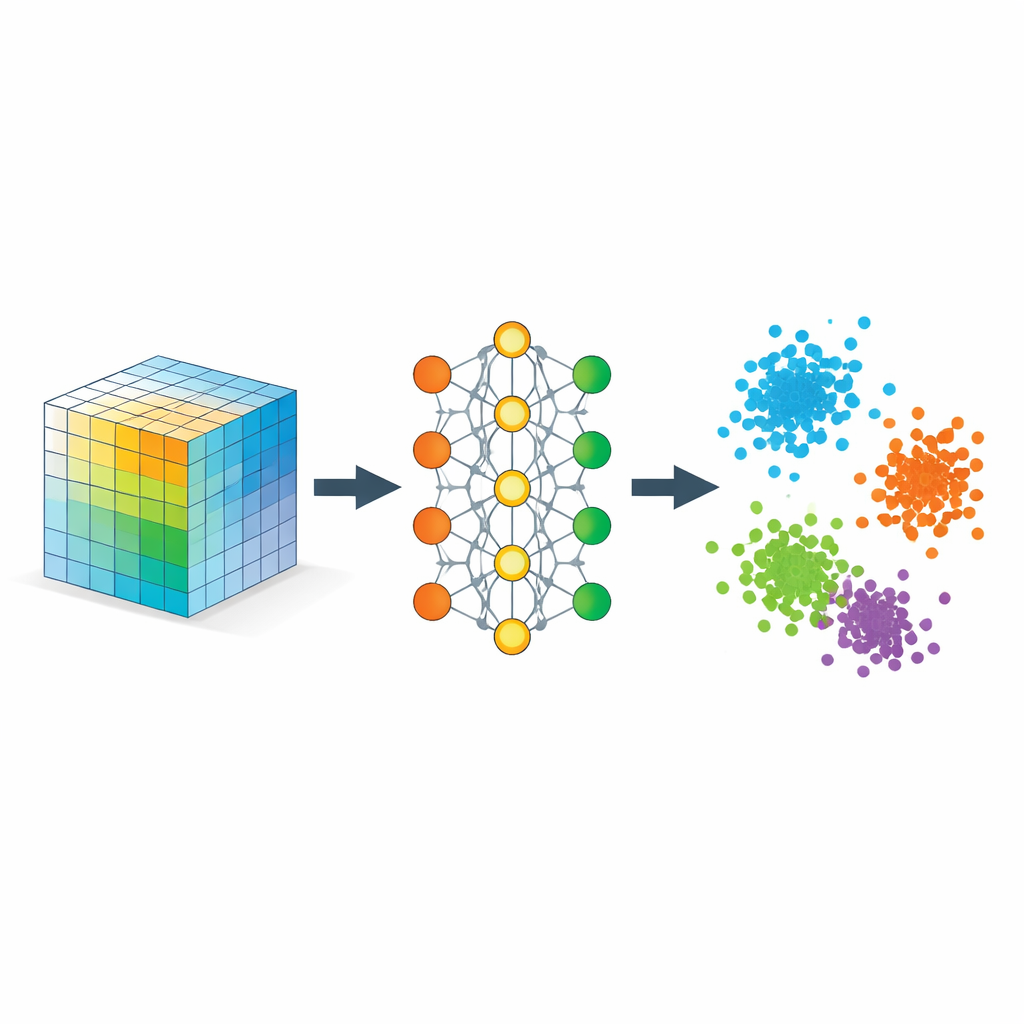
Обучая сеть тому, что значит «близко»
Ключевой ингредиент — стратегия, называемая метрическим обучением, реализованная здесь через триплеты примеров: якорный образец, положительный образец того же типа и отрицательный образец другого типа. В процессе обучения сеть поощряется, когда якорь оказывается ближе к положительному, чем к отрицательному, с заданным запасом безопасности. За множество таких триплетов это простое правило формирует пространство встраивания так, чтобы расстояния отражали семантическую схожесть, а не простое пиксельное сходство. Дополнительные регуляризаторы поощряют равномерное распределение информации по измерениям, предотвращают вырождение всего в одну линию и сохраняют локальные окрестности примерно неизменными, так что близкие в исходных данных точки остаются близкими в представлении.
Математически авторы показывают, что такое встраивание ведёт себя как гибкая тензорная декомпозиция, но без заранее заданного ранга. Выученные координаты можно интерпретировать как факторы в классическом разложении тензора сходства, чьи элементы измеряют, насколько сильно разные части данных согласуются друг с другом. Поскольку модель штрафует избыточные направления, она, как правило, эффективно использует все измерения встраивания, позволяя самим данным определить, сколько значимых компонент требуется. В то же время авторы дают теоретические гарантии сходимости стандартных процедур обучения и того, что полученная геометрия надёжно разделяет классы, не сильно искажая при этом значимые локальные отношения.
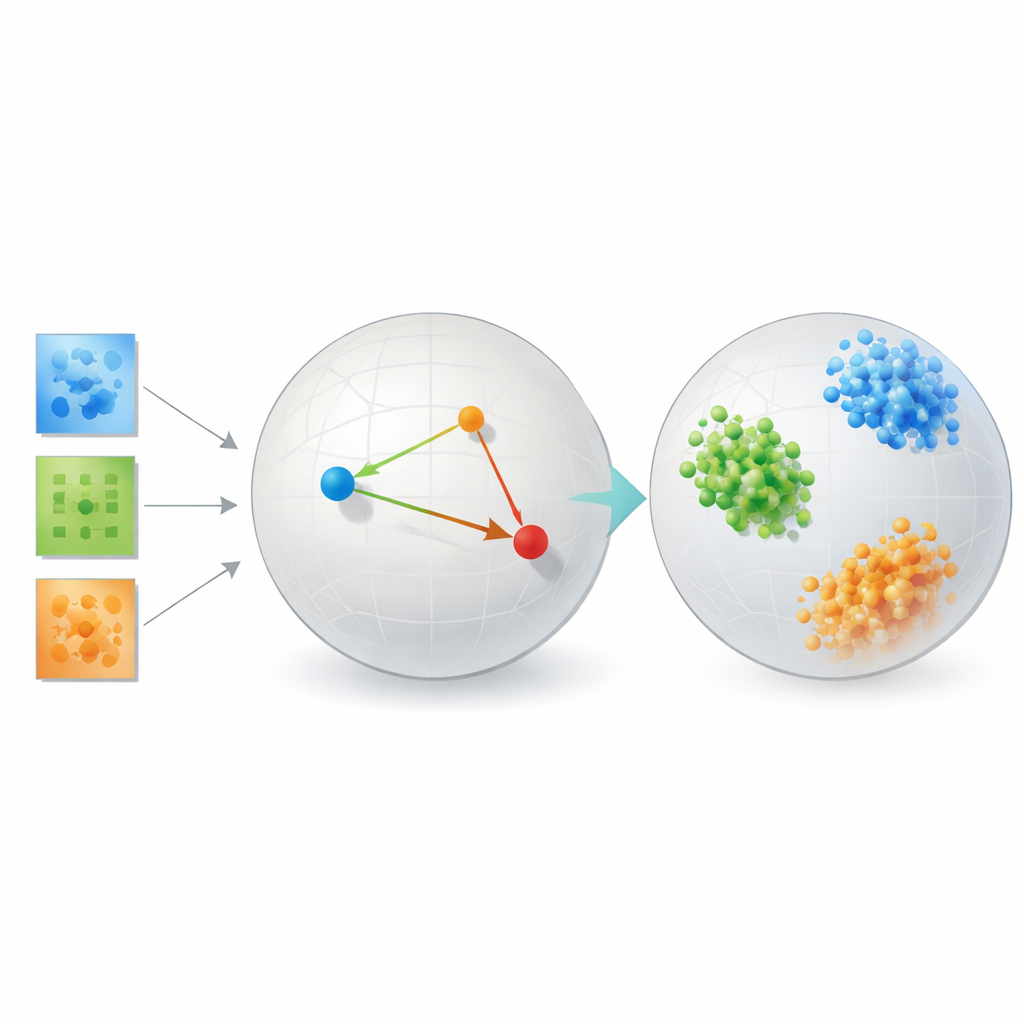
Проверка метода на практике
Чтобы показать, что подход не сводится к изящной теории, автор проверяет его на нескольких очень разных задачах. На бенчмарках по распознаванию лиц выученные встраивания группируют изображения одного человека в плотные, хорошо разделённые кластеры, значительно превосходя классические методы, такие как главный компонентный анализ, популярные инструменты визуализации вроде t-SNE и UMAP, а также традиционные тензорные декомпозиции с фиксированным рангом. На данных о связности мозга у людей с аутизмом и без метод находит пространство, в котором две группы разделяются чище, чем при использовании инструментов, ориентированных на восстановление, или автокодировщиков, намекая на то, что он улавливает клинически значимые паттерны взаимодействия областей мозга.
В исследовании также приведены контролируемые симуляции форм галактик и кристаллических структур, где «истинные» категории известны точно. Здесь рамки метрического обучения почти идеально кластеризуют синтетические галактики и кристаллы по их физическим типам. Во всех этих задачах метод последовательно идёт на компромисс: некоторая точность в восстановлении оригинальной пиксельной структуры уступает место представлению, в котором похожесть и различие совпадают с научным значением. Важно, что он делает это без огромных объёмов данных и вычислительных ресурсов, часто необходимых для обучения трансформерных моделей, которые в этих относительно небольших научных наборах данных работали хуже.
Почему это важно для будущих научных данных
Для учёных, ищущих закономерности в ограниченных высокоразмерных данных, эта работа предлагает привлекательную смену перспективы. Вместо угадывания ранга и оптимизации под восстановление, исследователи могут напрямую запросить встраивание, отражающее те отношения, которые для них важны: одинаковый диагноз, та же фаза материала, тот же астрофизический класс. Предложенная безранговая рамка метрического обучения показывает, что такие встраивания могут быть одновременно интерпретируемыми и эффективными, особенно при скудности данных. Как отмечает автор, остаются вызовы — включая работу с несбалансированными классами и масштабирование на множество категорий — но посыл ясен: во многих научных задачах изучение хорошего понятия похожести может быть ценнее, чем восстановление каждой детали исходного сигнала.
Цитирование: Bagherian, M. No-rank tensor decomposition via metric learning. Sci Rep 16, 8326 (2026). https://doi.org/10.1038/s41598-026-38221-3
Ключевые слова: метрическое обучение, тензорная декомпозиция, обучение представлению, снижение размерности, анализ научных данных