Clear Sky Science · ru
Гибридная стековая ансамблевая модель для многометочной детекции эмоций в тексте
Почему важно распознавание эмоций в тексте
Каждый день люди выливают свои чувства в постах в соцсетях, отзывах и сообщениях. В этом потоке слов спрятаны ранние сигналы о проблемах с психическим здоровьем, росте языка вражды и общественных реакциях на кризисы и катастрофы. Но компьютеры обычно видят только «позитив» или «негатив», упуская смесь эмоций, которую люди часто выражают одновременно. В этой статье рассматривается новый подход к обучению машин распознавать несколько эмоций в одном фрагменте текста и делать это не только по-английски, но и на языках, которые редко получают выгоду от передовых технологий ИИ.
Вне простого «позитив/негатив»
Традиционные инструменты анализа настроений похожи на грубые термометры: они показывают, хорошо ли настроение или плохо, но не умеют различать, испытывает ли человек гнев, страх, надежду или облегчение одновременно. Авторы утверждают, что понимание этой более богатой эмоциональной палитры важно для приложений, таких как реагирование на бедствия, поддержка в терапии и клиентский сервис. Сообщение, сочетающее страх и срочность, например, может требовать немедленного внимания, тогда как сообщение, смешивающее печаль и оптимизм, потребует иного вида поддержки. Захват нескольких эмоций одновременно — так называемая многометочная детекция эмоций — поэтому является ключевым шагом к более чувствительным, ориентированным на человека системам.
Дать голос забытым языкам
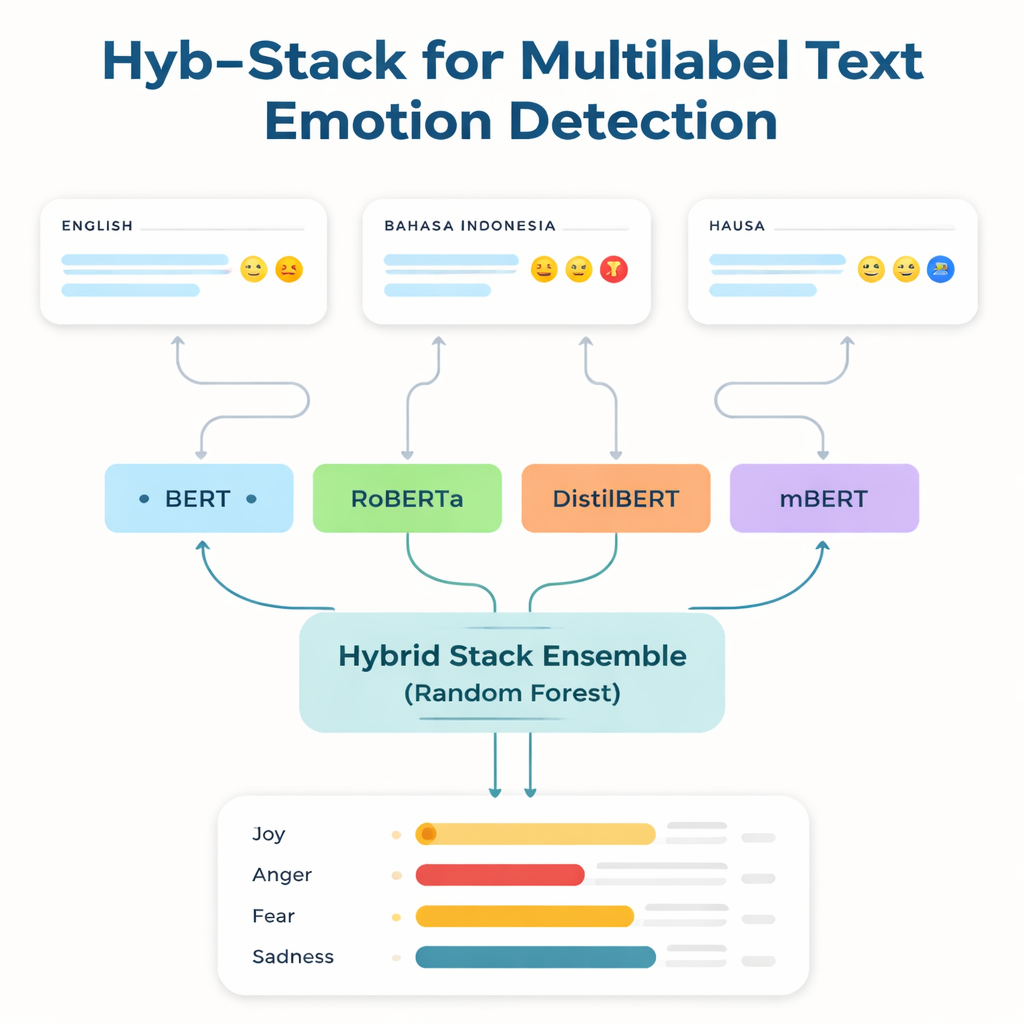
Большинство мощных языковых технологий обучаются и настроены на английском и нескольких других широко используемых языках. Носители языков с ограниченными ресурсами — тех, для которых мало размеченных данных и цифровых инструментов — часто остаются позади. Чтобы сократить этот разрыв, исследователи сосредоточились на трех наборах данных: известном англоязычном бенчмарке по эмоциям; коллекции на бахаса-Индонезия, ориентированной на оскорбления и язык вражды; и новом корпусе твитов на языке хауса, который они создали и назвали HaEmoC_V1. Набор данных по хауса включает более двенадцати тысяч тщательно очищенных и размеченных твитов, каждый из которых помечен одной или несколькими из одиннадцати эмоций, таких как гнев, радость, доверие, пессимизм и ожидание. Метки проверяли эксперты, а показатели согласованности показали, что разметка последовательна и надежна.
Объединение нескольких «умных» читателей в одну систему
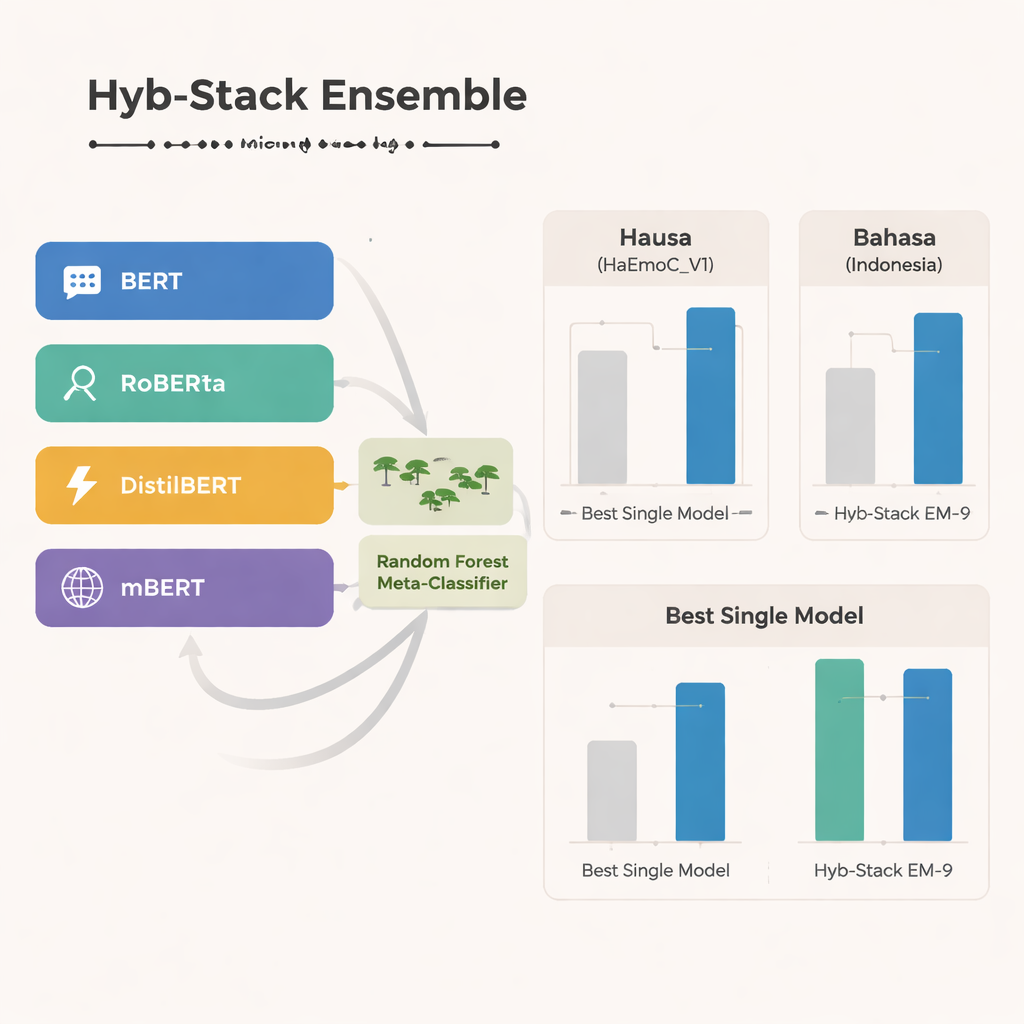
В основе исследования лежит Hyb-Stack, гибридный стековый ансамбль — своего рода «комитет экспертов» для языка. Четыре продвинутые трансформерные модели (BERT, RoBERTa, DistilBERT и мультиязычная mBERT) каждая дообучается для распознавания эмоциональных сигналов в тексте. Вместо того чтобы полагаться только на одну модель, Hyb-Stack позволяет им всем делать предсказания, а затем передаёт их внутренние оценки на второй уровень принятия решений: классификатор Random Forest. Этот мета-классификатор учится взвешивать разные сильные стороны каждой модели, улавливая сложные шаблоны совместного возникновения эмоций. Команда также тестирует более простые ансамблевые методы, которые просто усредняют предсказания, с учётом или без учёта весов по предыдущей производительности, чтобы понять, оправдывает ли себя более сложный стек.
Насколько хорошо работает гибридный подход
Во всех трех языках мультиязычная mBERT выделяется как самая сильная одиночная модель, особенно хорошо работающая на недавно собранных данных по хауса и на наборе по языку вражды на бахаса-Индонезия. Тем не менее гибридный ансамбль идёт ещё дальше. Одна конкретная комбинация — называемая EM-9, объединяющая BERT, DistilBERT и mBERT внутри фреймворка Hyb-Stack — постоянно показывает лучшие результаты. Она достигает более высоких F1-показателей, распространённой метрики точности, чем любая отдельная модель или простой способ усреднения, при этом наибольший прирост наблюдается в наборах данных с ограниченными ресурсами — хауса и бахаса-Индонезия. Детальные анализы ошибок показывают, что оставшиеся промахи обычно случаются между близкими по смыслу эмоциями, такими как радость и удивление или печаль и страх, что отражает естественную нечеткость человеческих чувств, а не явные сбои системы.
Что это значит для реальных систем
Для широкой аудитории главный вывод заключается в том, что объединение нескольких моделей ИИ умным образом может помочь компьютерам точнее распознавать эмоции в тексте, особенно на языках, которые долгое время были обделены технологиями. Создав высококачественный корпус эмоций на языке хауса и показав, что гибридные ансамбли превосходят одиночные модели и простые схемы голосования, авторы демонстрируют практический путь к более инклюзивным, эмоционально осведомлённым инструментам. В будущем работа будет расширять подход на более тонкие оттенки эмоций, смешанный язык (code-mixing), эмодзи и дополнительные недостаточно представленные языки с целью создания систем, которые смогут определять не только счастливы или грустны люди, но и как и почему они так себя чувствуют — вне зависимости от того, на каком языке они говорят.
Цитирование: Adamu, H., Azmi Murad, M.A. & Nasharuddin, N.A. A hybrid stacked ensemble learning framework for multilabel text emotion detection. Sci Rep 16, 7714 (2026). https://doi.org/10.1038/s41598-026-38172-9
Ключевые слова: обнаружение эмоций, многоязычная обработка естественного языка, ансамблевое обучение, трансформерные модели, языки с ограниченными ресурсами