Clear Sky Science · ru
Эффективные вычисления и проектирование высокоскоростной Vedic-умножительной архитектуры двойной точности
Почему важны более быстрые вычисления
Каждый раз, когда вы смотрите потоковое видео, пользуетесь навигацией на телефоне или позволяете ИИ анализировать медицинские снимки, специализированное аппаратное обеспечение незаметно выполняет миллиарды мелких вычислений в секунду. Большая часть этих операций — умножения чисел в форматe с плавающей запятой, стандартного представления действительных чисел, таких как 3.14159. В этой статье исследуется более рациональный способ создания одного из ключевых компонентов: высокоскоростного и энергоэффективного умножителя, который использует идеи древней ведической математики для повышения производительности современной цифровой аппаратуры.
От древних математических трюков к современным чипам
Арифметика с плавающей запятой лежит в основе цифровой обработки сигналов, обработки изображений, коммуникаций и ускорителей для глубокого обучения. Стандартные умножители должны обрабатывать длинные двоичные слова — 64 бита для двойной точности — и делать это быстро, не расходуя лишнюю площадь кристалла и энергию. Традиционные подходы, такие как алгоритмы Бута, Карацубы и матричные умножители, балансируют между скоростью, размером аппаратуры и сложностью проектирования. Ведическая математика, набор из 16 классических арифметических правил, разработанных в Индии, включает метод умножения Урдхва Тираякбхьям, или «вертикально и по диагонали». Он формирует частичные произведения в высокопараллельном режиме, что может сократить число промежуточных шагов и требуемую аппаратную реализацию. Исследователи недавно адаптировали эти идеи для цифровых схем, но существующие разработки по-прежнему несут накладные расходы при применении к операциям двойной точности с плавающей запятой.
Что особеннего в новом умножителе
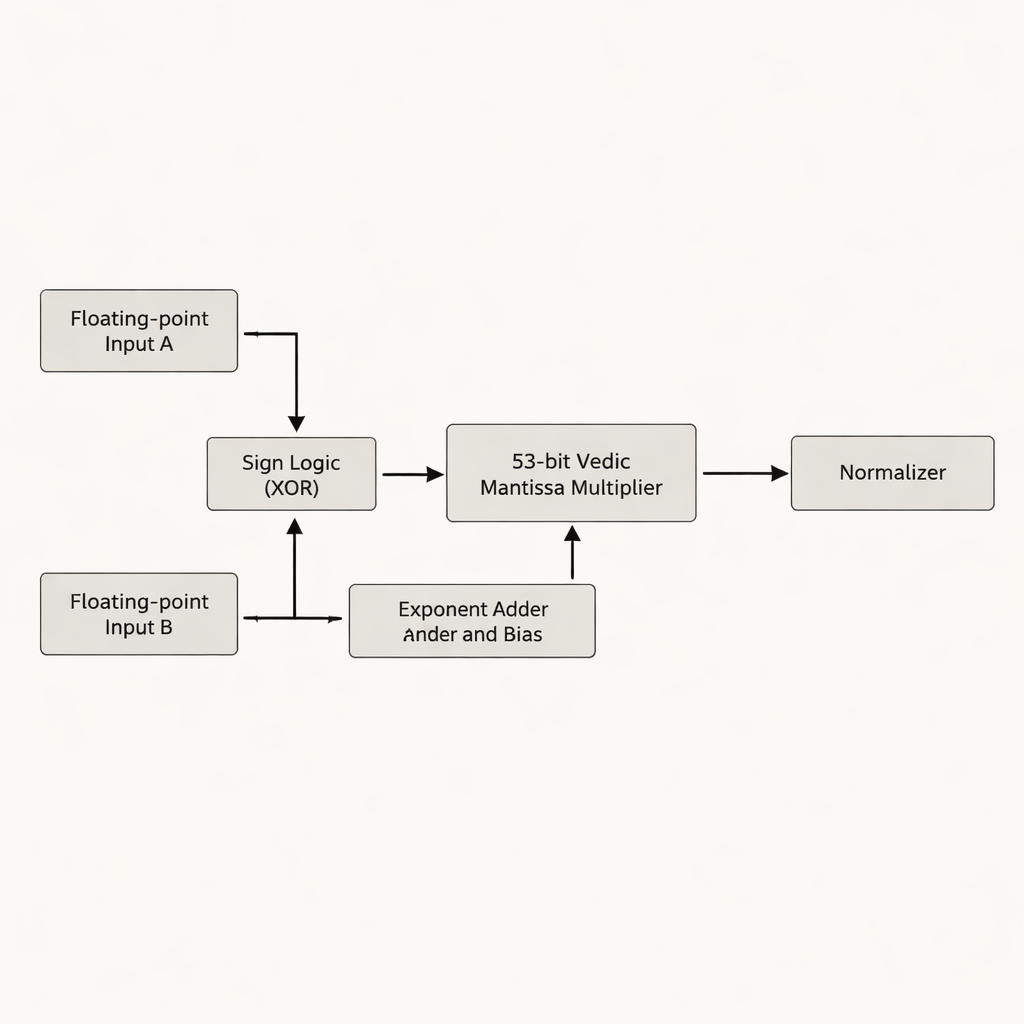
Авторы предлагают умножитель для чисел двойной точности, который сосредоточен на мантиссе — части числа с плавающей запятой, содержащей значащие цифры. Вместо выравнивания 52-битной мантиссы до 54 бит, как делают многие предыдущие решения, они работают с фактической эффективной 53-битной мантиссой, избегая пустых «неиспользуемых» битов, которые потребляют дополнительную память и коммутацию на кристалле. Сердце архитектуры — 53-битный ведический умножитель на основе Урдхва Тираякбхьям, организованный в иерархию из меньших блоков: 3-битные единицы образуют 6-битные, те — 12-, 13-, 26- и 52-битные блоки, которые комбинируются в финальной 53-битной ступени. Архитектура разделяет работу на три основные фазы — вычисление знака, сложение показателей и смещение, а также умножение мантиссы с последующей нормализацией — соответствуя стандарту IEEE-754 и устраняя избыточную логику.
Блоки простого размера для более чистой аппаратуры
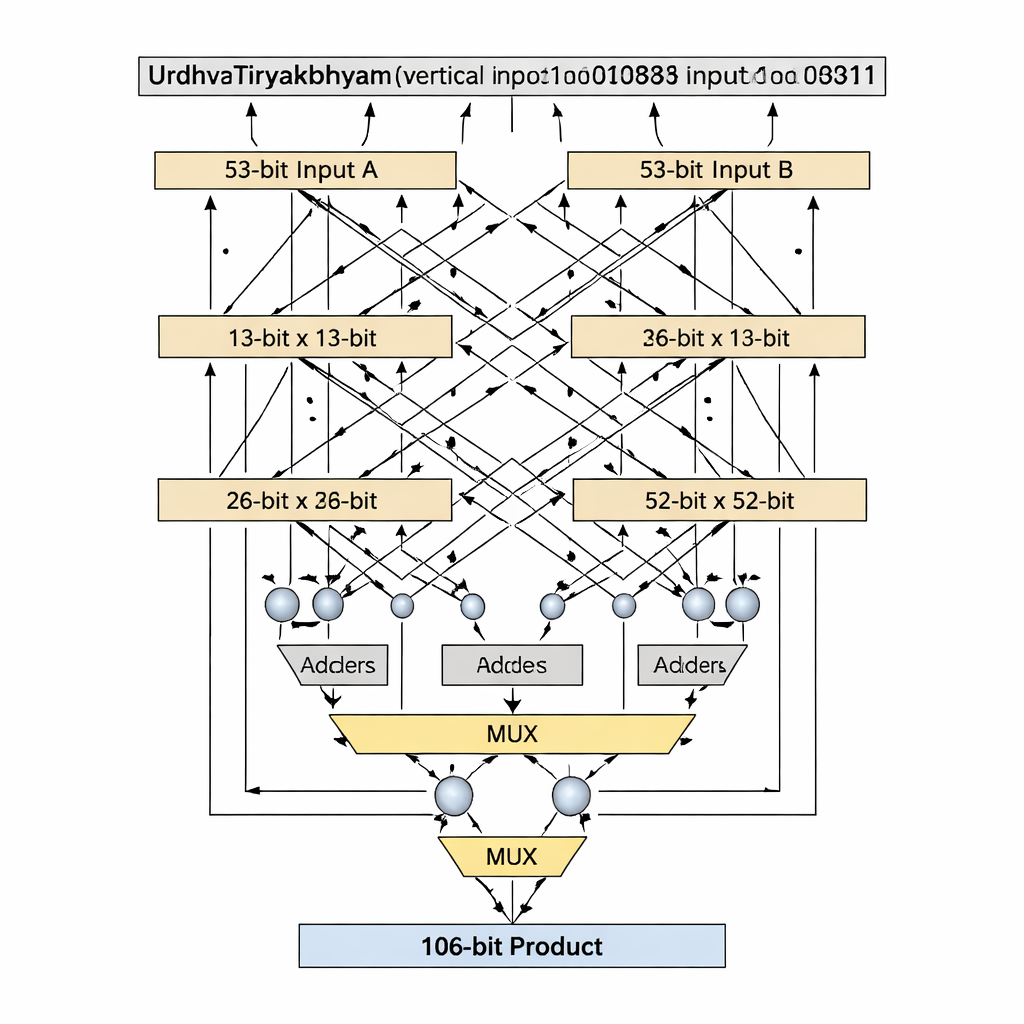
Ключевая инновация — способ работы с ширинами разрядов, которые являются простыми числами, такими как 13 и 53, — они не делятся равномерно на одинаковые блоки. Стандартные ведические разложения предполагают равномерное деление входов, но это становится неудобным или неэкономичным для простых длин. Авторы предлагают алгоритм «prime-bit», который хитро повторно использует меньший (n−1)-битный ведический умножитель вместе с сумматорами, мультиплексорами и одной дополнительной логической шиной, чтобы эмулировать n-битный умножитель без выравнивания. Для 13-битной ступени входы разбиваются на 1-битную и 12-битную части; частичные произведения создаются с помощью 12-битного ведического умножителя, условного выбора (через мультиплексоры) на основе старших битов и небольшого числа сумматоров. Та же схема масштабируется до 53 бит с ядром в 52 бита. Такое адаптированное разложение сокращает критический путь — самую длинную цепочку логики, по которой проходит сигнал — сохраняя при этом низкое количество логических элементов.
Измеренные выигрыши в скорости, размере и потреблении
Проект был описан на языке описания аппаратуры Verilog и реализован на программируемой логической матрице Xilinx Zynq с использованием инструментов Vivado. В диапазоне ведических умножителей на 13, 26, 52, 53 и 64 бита предложенный 53-битный блок демонстрирует выгодный баланс задержки, использования логики (таблиц поиска и выводов) и оценочной мощности. В сравнении с ранее опубликованными умножителями двойной точности на основе Бута, Карацубы и других ведических компоновок новая архитектура существенно уменьшает наихудшую задержку и объём ресурсов FPGA без увеличения сложности окружающей плавающей арифметики. Поскольку умножение мантиссы быстрее и глубина логики меньше, активность переключений снижается, что указывает на лучшее соотношение мощность–задержка, хотя прямые кросс-технологические сравнения мощности провести сложно.
Влияние на ИИ и обработку сигналов
Чтобы проверить дизайн в реальной нагрузке, авторы интегрировали свой ведический умножитель двойной точности в сверточный блок свёрточной нейронной сети, где операции умножения и накопления доминируют по времени выполнения. Замена традиционных IEEE-754 и ранних ведических умножителей на новое решение сократила задержку свёртки, уменьшила энергопотребление и снизила время вывода, при этом сохраняя прежнюю точность классификации. Ожидаются аналогичные преимущества в других вычислительно тяжёлых задачах, таких как цифровая фильтрация, детекция границ и медицинские потоки обработки изображений, где более быстрые умножители напрямую повышают производительность и позволяют устройствам работать холоднее или от более компактных батарей.
Что это значит для повседневных технологий
Проще говоря, в статье показано, что заимствованный из ведической математики приём умножения и аккуратное согласование его с современными двоичными форматами дают умножитель, который меньше, быстрее и энергоэффективнее стандартных решений. Этот улучшенный строительный блок может быть встроен в процессоры, чипы обработки сигналов и ускорители ИИ, приводя к более быстрому анализу данных, более отзывчивым устройствам и потенциальному снижению энергопотребления в системах от смартфонов до медицинских сканеров. Авторы также очерчивают будущие направления, включая обратимую логику для ещё меньшего энергопотребления и интеграцию в более крупные вычислительные блоки, что наводит на мысль, что такое сочетание древней арифметики и современной аппаратуры только начинает своё развитие.
Цитирование: Kumar, A.S., Sahitya, G., Kusuma, R. et al. Efficient computation and design of high speed double precision Vedic multiplier architecture. Sci Rep 16, 7364 (2026). https://doi.org/10.1038/s41598-026-38147-w
Ключевые слова: Vedic-умножитель, операции с плавающей запятой, проектирование на FPGA, цифровая обработка сигналов, сверточные нейронные сети