Clear Sky Science · ru
Применение роевых глубинных нейронных сетей и ансамблевых моделей для восстановления данных по удельной проводимости
Почему важно заполнять пробелы в данных
Прибрежные воды — это передовая линия, где деятельность человека встречается с океаном. Ученые отслеживают соленость этих вод с помощью показателя, называемого удельной проводимостью, который помогает выявлять утечки загрязнений, изменения притока пресной воды и долгосрочные экологические сдвиги. Но датчики выходят из строя, штормы отключают питание, а приборы имеют ограничения. В результате в ключевых записях возникают неприятные пробелы — как раз тогда, когда менеджерам и исследователям нужны непрерывные данные. В этом исследовании поставлен практический вопрос: может ли современный искусственный интеллект надежно «починить» такие поврежденные записи, чтобы прибрежные решения опирались на полную и достоверную информацию?
Наблюдая, как дышит Мексиканский залив
Исследователи сосредоточились на Мексиканском заливе, одном из крупнейших морских экосистем мира и регионе с сильным промышленным и сельскохозяйственным давлением. Они использовали измерения с пяти станций Геологической службы США вблизи рек Паскагула и озера Маллет, каждая из которых регистрировала соленость воды (через удельную проводимость), температуру и уровень воды каждые 15 минут. Одна станция, обозначенная как E, имела примерно 5% пропущенных данных по удельной проводимости — именно такая проблема встречается в реальных сетях мониторинга. Данные с четырёх соседних станций образовали некую экологическую страховку: даже когда станция E «слепла», остальные продолжали наблюдать. Основная идея заключалась в том, чтобы научить компьютерные модели понимать, как все пять станций «дышат» вместе, чтобы пробелы на одной площадке можно было выводить по полным записям остальных.
Испытание умных алгоритмов
Для решения этой задачи команда собрала десяток различных подходов к моделированию. С одной стороны были привычные инструменты, такие как множественная линейная регрессия, которые пытаются установить линейные связи между входами и выходами. В середине — более гибкие модели, такие как классические нейронные сети, нечеткая логика и специальная сеть с долгой кратковременной памятью (LSTM), часто используемая для временных рядов. Они также применили самоорганизующийся метод под названием GMDH (group method of data handling) и его нелинейный вариант (NGMDH), который способен самостоятельно строить многослойные формулы. Наконец, были использованы древовидные методы: одиночная модель решения на дереве (CART) и два «ансамблевых» подхода — Random Forest и XGBoost, которые объединяют множество деревьев для вынесения итогового решения, подобно панели экспертов, голосующих за ответ.
Глубокое обучение, усиленное роем
Обучение глубоких нейронных сетей печально известно своей сложностью: их многочисленные параметры и настройки легко застревают в неудачных конфигурациях. Чтобы улучшить их, авторы связали LSTM и NGMDH с недавним методом оптимизации, вдохновлённым вихревой водой, названным оптимизацией на основе турбулентного потока воды (TFWO). В этой схеме каждое возможное множество параметров модели представляют как «частицу», движущуюся по спиралевидной траектории в пространстве всех решений. В ходе множества циклов частицы подтягиваются к областям, дающим меньшие ошибки предсказания. Поисковая стратегия в стиле роя сделала оба типа нейросетей заметно точнее по сравнению со стандартными версиями, снизив их средние ошибки примерно на 6–11 процентов. Тем не менее даже эти улучшенные глубокие модели в конечном счёте уступили древовидным подходам.
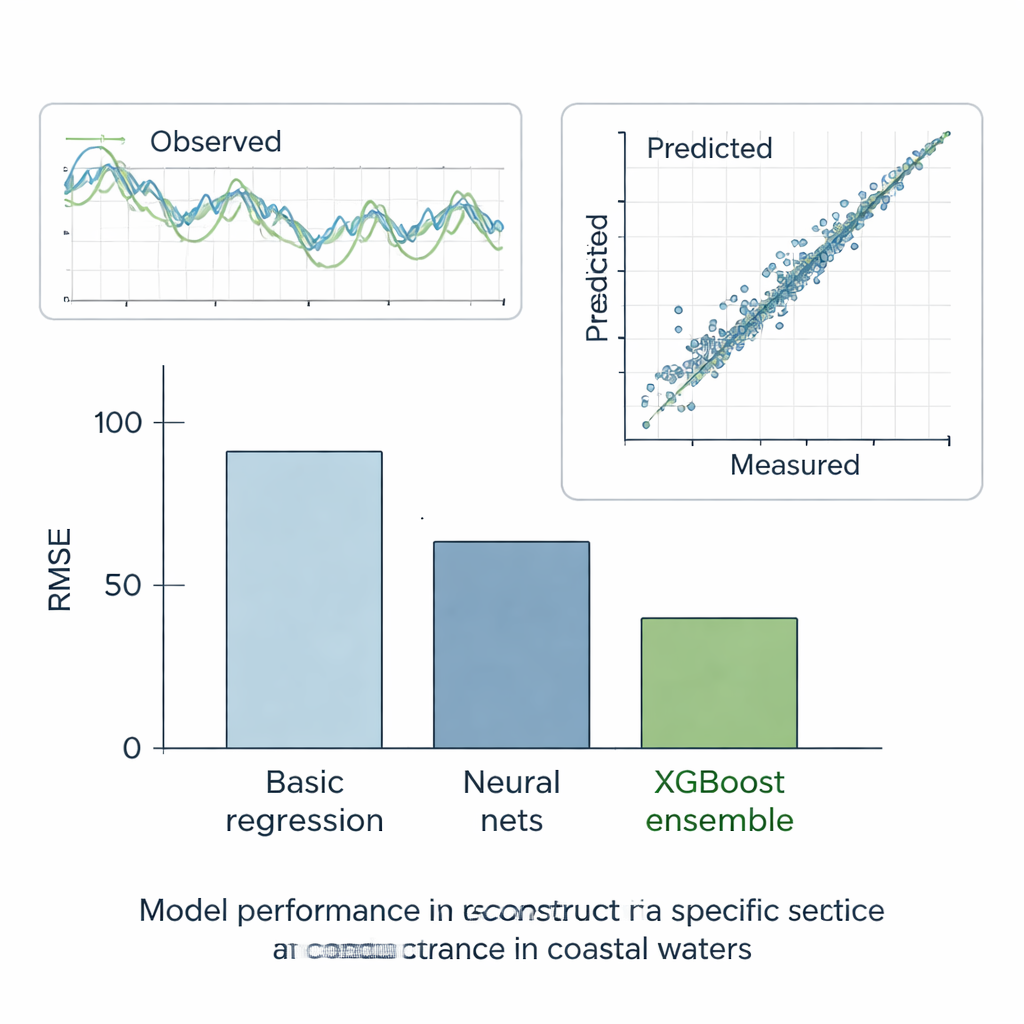
Ансамбли выходят вперёд
Авторы скрупулёзно протестировали все методы в шести сценариях. В пяти «что‑если» случаях они скрывали фрагменты в иначе полных записях и проверяли, насколько хорошо каждая модель могла восстановить пропущенные значения. В финальном, реальном сценарии они просили модели заполнить истинные пропуски на станции E, используя данные соседей. В этих испытаниях самая простая линейная модель показала наихудшие результаты, тогда как стандартные модели машинного обучения проявили себя гораздо лучше, снизив ошибку примерно вдвое. Деревья решений, автоматически разбивающие данные на более однородные группы, ещё больше улучшили показатели. Но явным победителем стал ансамбль XGBoost: строя сотни деревьев, каждое из которых исправляет ошибки предыдущих, он достиг чрезвычайно низкой ошибки и почти идеального совпадения между предсказанной и измеренной удельной проводимостью. Его реконструкции следовали наблюдаемым временным рядам и воспроизводили общую статистическую картину записей качества воды.
Что это значит для побережий и не только
Для неспециалистов вывод прост: тщательно разработанный ИИ способен надёжно заполнять пропущенные фрагменты записей качества прибрежных вод, особенно когда рядом есть станции, дающие контекст. Несмотря на мощь продвинутых нейросетей, это исследование показывает, что древовидные ансамблевые методы, такие как XGBoost, ещё точнее и на практике могут быть лучшим выбором для восстановления экологических наборов данных. Благодаря надёжным инструментам заполнения пробелов учёные могут лучше отслеживать тонкие изменения солёности прибрежных вод, выявлять эпизоды загрязнения и поддерживать управленческие решения, не позволяя себе быть сорванными неизбежными отказами датчиков. Те же стратегии можно адаптировать к многим другим инженерным и экологическим задачам, где потоки данных богаты, зашумлены и временами неполны.
Цитирование: Mahdavi-Meymand, A., Sulisz, W. & Nandan Bora, S. Application of swarm-based deep neural networks and ensemble models for reconstruction of specific conductance data. Sci Rep 16, 7292 (2026). https://doi.org/10.1038/s41598-026-38136-z
Ключевые слова: качество прибрежных вод, удельная проводимость, машинное обучение, восстановление пропущенных данных, XGBoost