Clear Sky Science · ru
Построение и усовершенствованные методы извлечения онтологической сети знаний на основе больших языковых моделей
Умные карты для сложных решений
Современные решения в областях с высокими ставками — таких как крупномасштабные операции, управление инфраструктурой или реагирование на катастрофы — зависят от умения быстро осмысливать огромный объём разрозненной информации. Руководства, потоки данных с датчиков, отчёты и симуляции рассказывают лишь части общей картины, и их редко организуют так, чтобы люди или компьютеры могли легко ими воспользоваться. В этой работе предлагается способ превратить фрагментированную информацию в живые «карты знаний», основанные на больших языковых моделях, чтобы планировщики и аналитики могли задавать лучшие вопросы и получать быстрее и надёжнее ответы.
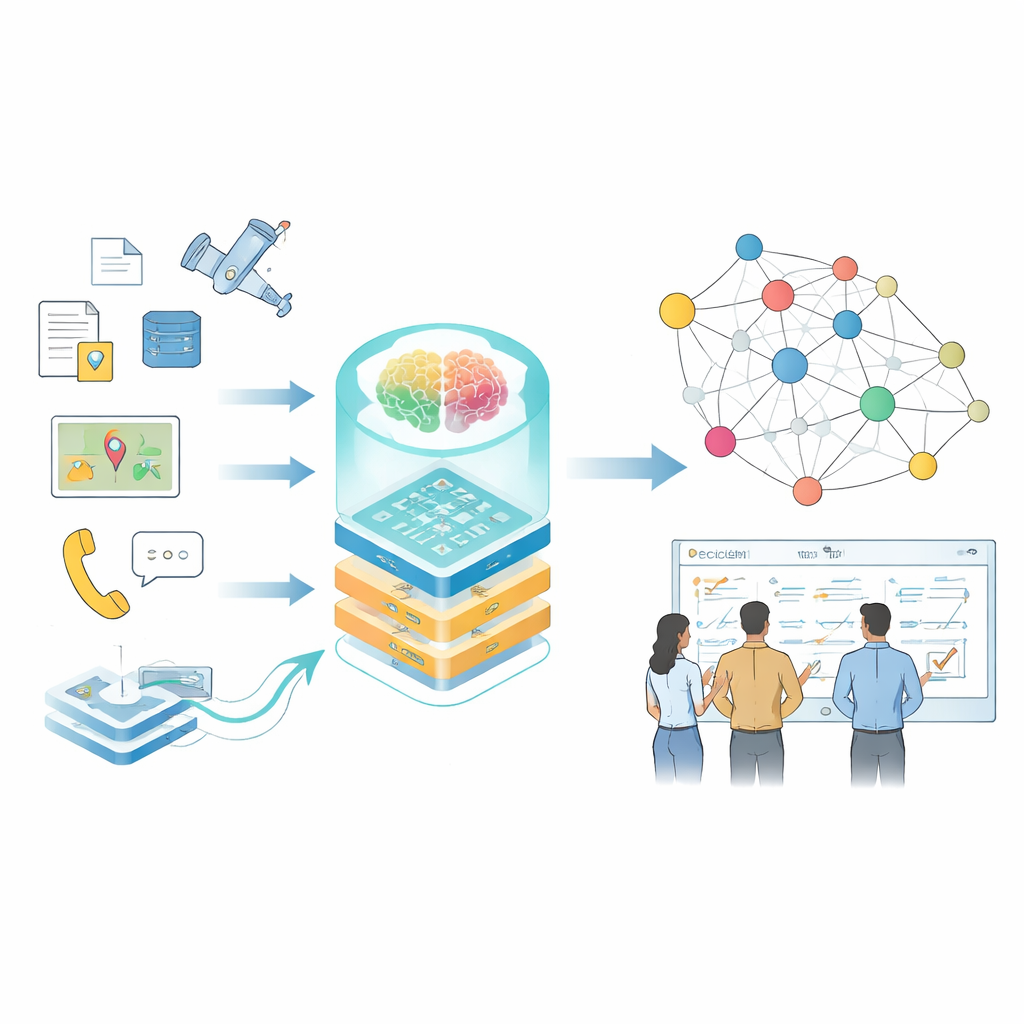
От разрозненных фактов к связанным знаниям
Авторы сосредотачиваются на графах знаний — способе представления информации в виде сети связанных фактов: кто сделал что, с каким оборудованием, при каких условиях. В повседневных задачах такие графы уже лежат в основе поисковых систем и рекомендателей, но специализированные области создают более сложные проблемы: данные бывают конфиденциальными, терминология — плотной, форматы варьируются от свободного текста до логов датчиков, а условия меняются быстро. Традиционные инструменты, опирающиеся на написанные вручную правила или небольшие модели, с трудом успевают за изменениями, а универсальные языковые модели часто неверно интерпретируют технические термины или упускают тонкие взаимосвязи, важные для принятия реальных решений.
Обучение больших языковых моделей новой специализации
Чтобы решить эту задачу, исследование дообучает мощную базовую языковую модель на тщательно подготовленном доменно‑специфичном наборе данных. Набор данных опирается на команды управления, инструкции по оборудованию, смоделированные сценарии и экспертную литературу. Прежде чем любой материал попадёт в модель, его тщательно обезличивают: конкретные координаты превращаются в относительные местоположения, названия подразделений заменяются на общие коды, а чувствительная логика частично маскируется при сохранении общих закономерностей. Данные хранятся в структурированном формате, который описывает общую ситуацию, конкретные задачи (такие как планирование, ранжирование угроз или ответы на вопросы) и связи между ними. Такая структура позволяет модели усваивать не только отдельные факты, но и то, как разные задачи разделяют контекст.
Слои адаптации для разных задач
Вместо переобучения всех параметров языковой модели — дорогостоящего и рискованного процесса — авторы применяют технику низкоранговой адаптации, организованную в несколько слоёв, каждый из которых фокусируется на отдельном аспекте проблемы. Один слой фиксирует базовую терминологию и концепты, другой внедряет оперативные правила и ограничения, а третий специализируется на адаптации к конкретным задачам, таким как планирование или оценка угроз. Отдельный управляющий компонент, «маршрутизирующая» сеть, анализирует каждый фрагмент входных данных и решает, какое сочетание этих лёгких адаптеров модель должна использовать. Такая архитектура позволяет системе эффективно переключаться между задачами, сохраняя и общую языковую компетенцию, и доменно‑специфическую экспертизу.
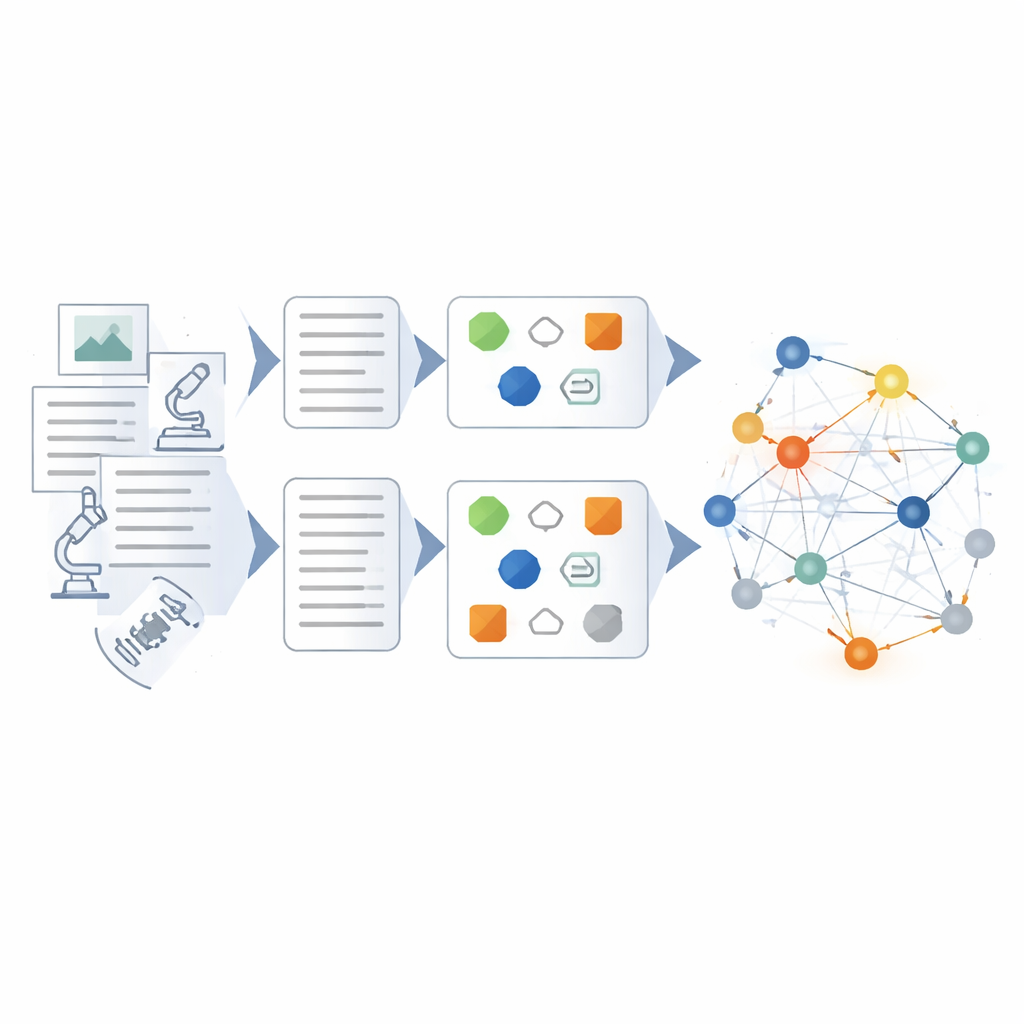
Построение и проверка сети знаний
Поверх дообученной модели авторы разрабатывают гибридный конвейер для самого построения графа знаний. Сначала сырые данные очищают и стандартизируют, чтобы термины и форматы были согласованы. Затем правил‑ориентированные методы и шаблоны, созданные экспертами, извлекают очевидные сущности и события. Дообученная языковая модель вмешивается для более сложной работы: сворачивает неструктурированные отчёты в сжатые резюме, выделяет ключевых участников и оборудование, а также выводит отношения, такие как причинно‑следственные цепочки или координация между подразделениями. Каждый извлечённый факт оценивается по нескольким критериям — насколько он соответствует известным шаблонам, насколько тесно связан с другими фактами и согласуется ли с многошаговыми путями рассуждений в графе. В систему добавляются только результаты с высокой уверенностью, а низкоуверенные помечаются для проверки.
Доказанная польза в точности и надёжности
Команда оценивает свой подход по трём ключевым задачам, отражающим реальные потребности: ответы на сложные вопросы о правилах и оборудовании, предложение планов действий для заданных ситуаций и ранжирование сценариев угроз по серьёзности. По всем этим задачам адаптированная модель стабильно превосходит известные универсальные системы, включая передовые модели с гораздо более общим обучением. Она даёт больше правильных ответов, генерирует более реалистичные планы и точнее ранжирует угрозы. Получившийся граф знаний одновременно велик и плотно связан: более 90 процентов сохранённых фактов проходят строгие проверки уверенности и помогают планировщикам быстрее принимать обоснованные решения.
Почему это важно в будущем
Для неспециалиста ключевое сообщение такое: языковые модели можно превратить из красноречивых «говорунов» в внимательных, специализированных аналитиков — при условии правильного набора данных, чётких ограничений и постоянной проверки качества. Эта работа показывает, как сделать это в чувствительной, быстро меняющейся области, при этом защищая конфиденциальную информацию. Предложенная схема не только организует разрозненные знания в удобную сеть, но и поддерживает её актуальность и надёжность, создавая образец для будущих систем поддержки принятия решений в любой сфере, где важно правильно принимать сложные решения.
Цитирование: Peng, L., Yang, P., Juexiang, Y. et al. The construction and refined extraction techniques of knowledge graph based on large language models. Sci Rep 16, 8104 (2026). https://doi.org/10.1038/s41598-026-38066-w
Ключевые слова: граф знаний, большая языковая модель, поддержка принятия решений, адаптация к домену, обезличивание данных