Clear Sky Science · ru
Генерация пограничных тестовых образцов для тестеров случайности с помощью интеллектуальной оптимизации и эволюционных алгоритмов
Почему почти‑случайное важно для повседневной безопасности
Каждый раз, когда вы делаете покупки в интернете, разблокируете телефон или отправляете приватное сообщение, незримые математические кости подбрасываются, чтобы защитить ваши данные. Эти «кости» представляют собой длинные строки предположительно случайных битов, используемые в криптографических ключах. Если эти биты даже немного менее случайны, чем требуется, целеустремлённые злоумышленники иногда могут обнаружить эксплуатационные закономерности. В статье рассматривается новый способ создания «почти‑случайных» тестовых последовательностей — данных, которые выглядят крайне случайно, но скрывают крохотные дефекты — чтобы инженеры могли серьёзно стресс‑тестировать устройства, охраняющие нашу цифровую жизнь.
Когда случайные числа не настолько случайны
Современные системы безопасности опираются на два типа генераторов случайных чисел. Истинные генераторы случайных чисел используют непредсказуемые физические эффекты, такие как электронный шум или квантовые флуктуации, тогда как псевдослучайные генераторы применяют алгоритмы, расширяющие короткие случайные семена в длинные последовательности. На практике качество обоих типов в конечном счёте зависит от физического источника непредсказуемости, называемого источником энтропии. К сожалению, реальные источники энтропии хрупки: изменения температуры, старение аппаратуры или ошибки проектирования могут незаметно снизить их случайность. Чтобы обнаруживать такие проблемы, стандарты, например NIST, определяют наборы статистических тестов, проверяющих, выглядят ли выходные биты достаточно случайными. Всё чаще устройства встраивают «тестеры случайности в реальном времени», которые контролируют собственный вывод в процессе работы. Однако до сих пор не было хорошего способа сгенерировать реалистичные, труднообнаружимые случаи отказа, чтобы проверить, действительно ли такие встроенные проверяющие механизмы работают.
Проектирование последовательностей, которые едва не проходят тесты на случайность
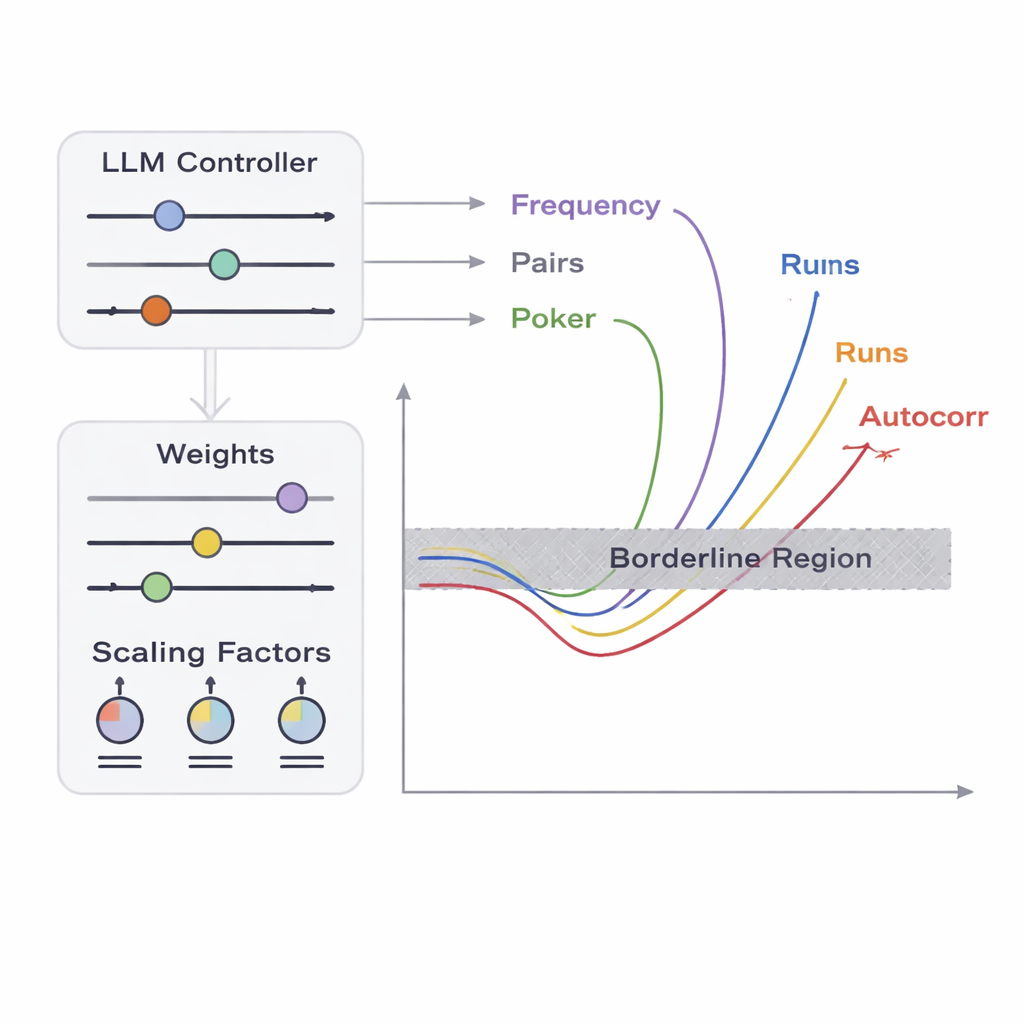
С точки зрения тестера тривиальные отказы — например, все нули в выводе — легко заметить. Настоящая задача — обнаружить пограничные случаи: последовательности, почти неотличимые от идеальной случайности, но всё‑таки не проходящие один или несколько статистических тестов. Авторы сосредотачиваются на пяти классических тестах, которые оценивают разные аспекты битовых паттернов: частоту появления нулей и единиц, поведение пар битов, распределение коротких шаблонов, корреляцию битов со сдвинутыми копиями и длины серий одинаковых битов. Для каждого теста они определяют «пограничную зону»: узкую полосу, где данные лишь слегка нарушают обычные допустимые пороги. Создать длинную последовательность, которая одновременно попадает во все эти узкие зоны, крайне маловероятно случайно, потому что тесты взаимодействуют сложными, нелинейными способами. Именно здесь на помощь приходят оптимизация и ИИ.
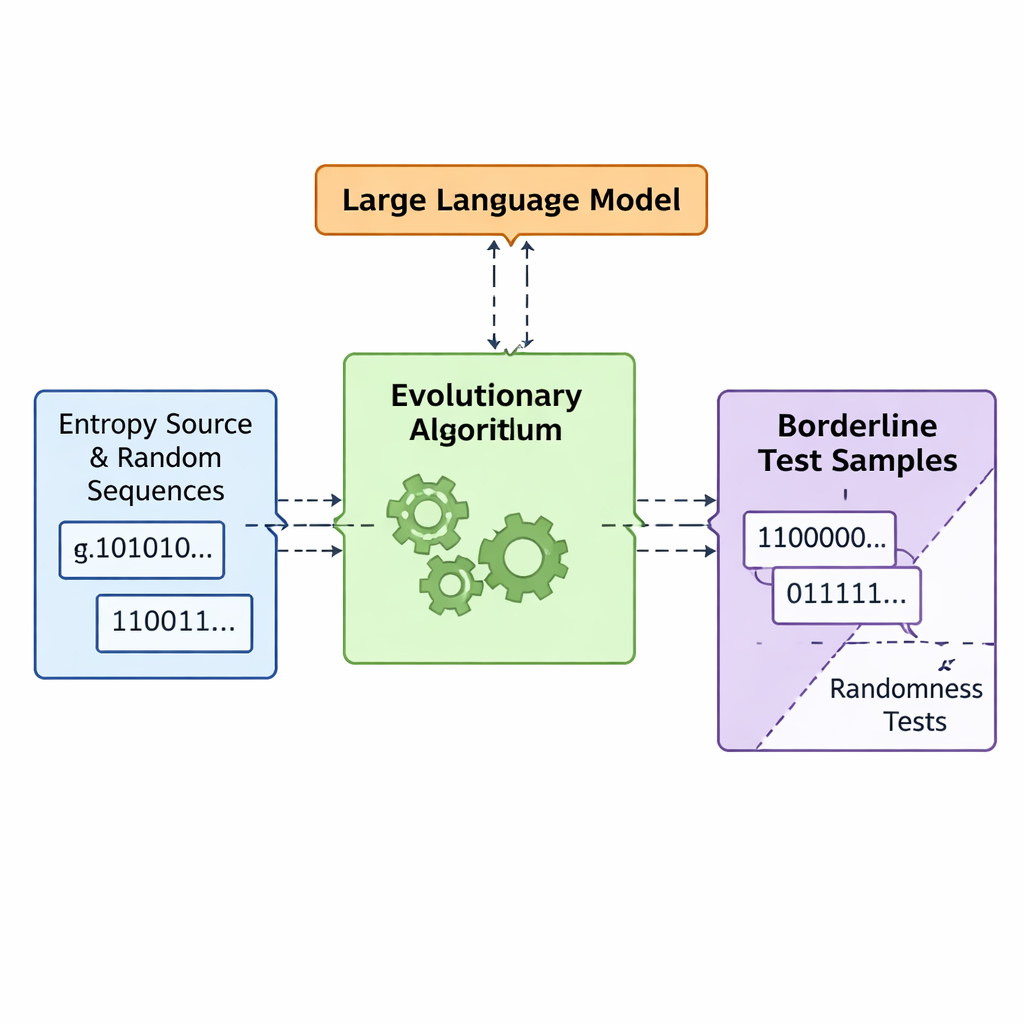
Пусть эволюция и языковые модели совместно проектируют «плохую» случайность
Исследователи предлагают фреймворк под названием APAM‑IGLLM, который рассматривает генерацию последовательностей как задачу высокоразмерной оптимизации. Каждый кандидат — это строка битов, а его «пригодность» измеряет, насколько близко он подходит к пограничным зонам пяти тестов. Генетический алгоритм многократно мутирует и рекомбинирует эти последовательности, сохраняя те, что приближаются к целевой области. Поверх этого большая языковая модель (LLM) выступает в роли тактического тренера. На каждой итерации она анализирует сводную статистику популяции и краткосрочную историю, затем предлагает, как настроить внутренние рычаги — веса и коэффициенты масштабирования, определяющие, насколько сильно каждый тест влияет на функцию пригодности. Это создаёт петлю обратной связи: генетический алгоритм исследует пространство возможных последовательностей, а LLM корректирует поиск так, чтобы все пять оценок тестов сходились к крошечному пересечению, где последовательности едва перестают быть случайными.
Насколько правдоподобно могут выглядеть дефектные данные?
Чтобы проверить, выглядят ли их искусственные дефекты реалистично, авторы сравнивают сгенерированные последовательности с широко используемыми эталонами. Они вычисляют как энтропию Шеннона, так и min‑энтропию — меры того, насколько непредсказуемым кажется каждый байт — и получают значения около 7.6–8 бит на байт, что очень близко к теоретическому максимуму 8 и сопоставимо с коммерческими аппаратными источниками случайности и публичным маяком случайности NIST. Они также запускают полный набор статистических тестов NIST SP 800‑22 и наблюдают, что их пограничные последовательности проходят и не проходят тесты почти с той же картиной, что и подлинные высококачественные случайные данные. Иными словами, для стандартных инструментов эти образцы выглядят по сути нормально, хотя они были целенаправленно сконструированы так, чтобы находиться рядом с несколькими порогами отказа. Это делает их идеальными «адверсариальными» входными данными для проверки устойчивости встроенных тестеров случайности.
Что это значит для реальной безопасности
Для неспециалиста эта работа предлагает новый способ проверки на безопасность механизмов генерации случайных чисел, лежащих в основе шифрования. Вместо того чтобы тестировать устройства только на явных сломанных или совершенно исправных источниках случайности, инженеры теперь могут подвергать их атаке тщательно подобранными, почти корректными последовательностями, имитирующими тонкие аппаратные дефекты или влияние окружающей среды. Если тестер случайности в реальном времени пропустит такие пограничные случаи, это указывает на потенциальную «слепую зону», которую следует устранить до развертывания устройства в банковских системах, защищённой связи или блокчейн‑инфраструктуре. Используя эволюционный поиск под управлением языковой модели, авторы предлагают практический инструмент для генерации таких требовательных тестовых данных, способствуя повышению надёжности скрытых основ цифровой безопасности.
Цитирование: Gao, P., Zhang, B., Wang, Z. et al. Generating borderline test samples for randomness testers via intelligent optimization and evolutionary algorithms. Sci Rep 16, 7268 (2026). https://doi.org/10.1038/s41598-026-38020-w
Ключевые слова: генераторы случайных чисел, источники энтропии, эволюционные алгоритмы, большие языковые модели, криптографическое тестирование