Clear Sky Science · ru
Коррекция шумных меток через сравнительную дистилляцию: подход адаптации домена
Почему беспорядочные данные становятся всё большей проблемой
Современный искусственный интеллект живёт за счёт данных, но эти данные часто ошибочны, неполны или размечены непоследовательно. Когда метки шумные — например, фото кота помечено как собака — обучающимся системам легко заблудиться: они теряют точность и надёжность. В этой работе рассматривается именно такая практическая проблема: как обучать системы распознавания изображений, чтобы они оставались эффективными, даже если тренировочные метки содержат ошибки и изображения приходят из разных сред, например из интернет‑каталогов и реальных фотографий.
Обучение в разных мирах
На практике модели ИИ часто обучаются в «исходном» мире, где метки проверены тщательно, а затем должны работать в «целевом» мире, где меток мало и они подвержены ошибкам. Например, предметы офиса, снятые в студии, аккуратны и правильно размечены, тогда как снимки тех же предметов с веб‑камер или сделанные в повседневной обстановке бывают грязными и помечены непоследовательно. Традиционные методы адаптации домена пытаются сократить этот разрыв, выравнивая общие статистики двух миров. Однако они обычно предполагают, что метки в целевом домене, когда они есть, корректны — рискованное допущение, которое рушится в реальных приложениях с краудсорсинговыми пометками, датчиками низкого качества или автоматическими инструментами аннотации.
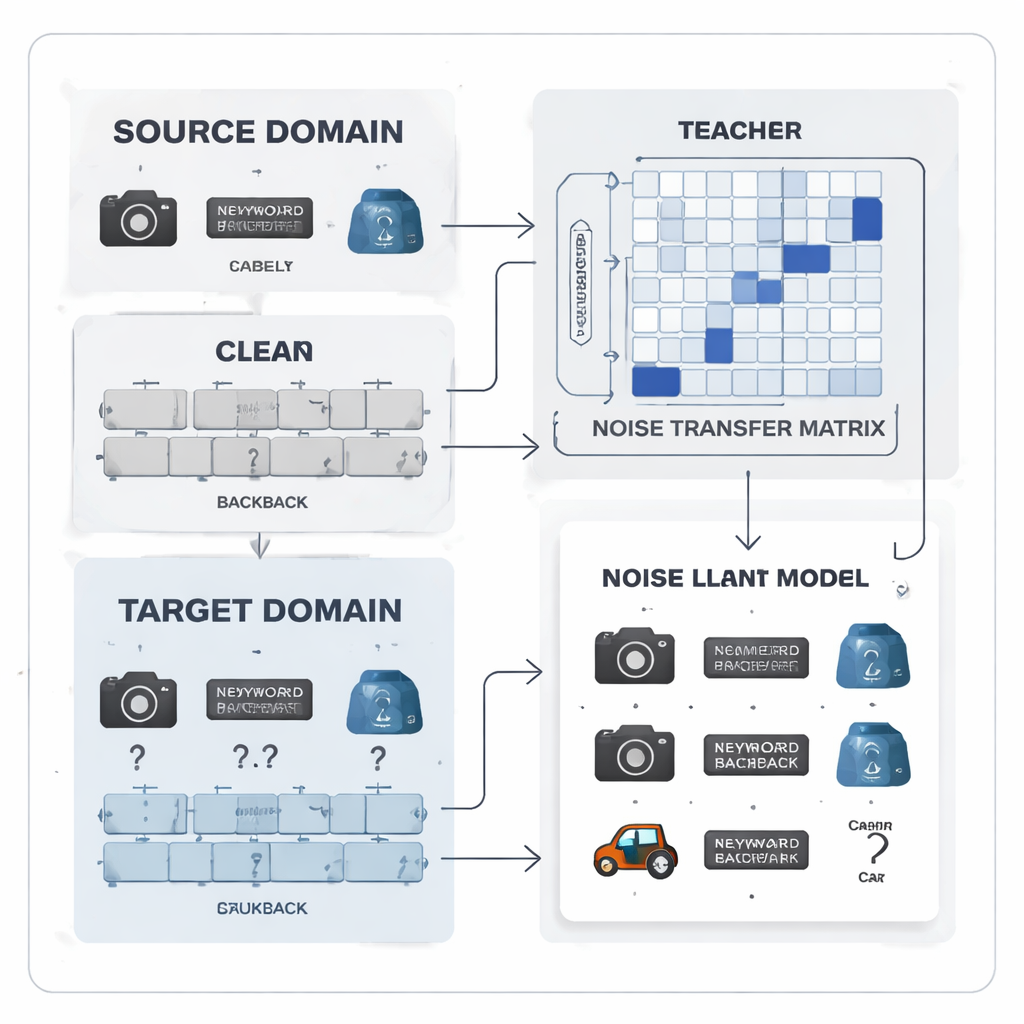
Преобразование ошибок меток в изучаемую закономерность
Авторы предлагают рассматривать шум в метках не как случайный хаос, а как изучаемую закономерность. Они вводят «матрицу переноса шума» — таблицу, фиксирующую, с какой вероятностью истинный класс может быть ошибочно помечен как другой. Вместо того чтобы оценивать эту матрицу по нескольким идеальным «якорным» примерам — что нереалистично при шумных метках и несбалансированных классах — матрица обучается непосредственно во время тренировки. Чтобы дать обучение старт, метод строит категориальные «прототипы» — усреднённые отпечатки признаков для каждого класса, извлечённые сильной предварительно обученной моделью. Сходство между этими прототипами используется для инициализации матрицы так, чтобы изначально более связанные и легко спутываемые категории, например похожие офисные инструменты, были сильнее связаны, давая системе раннюю способность корректировать метки.
Команда учитель–ученик для более чистых сигналов
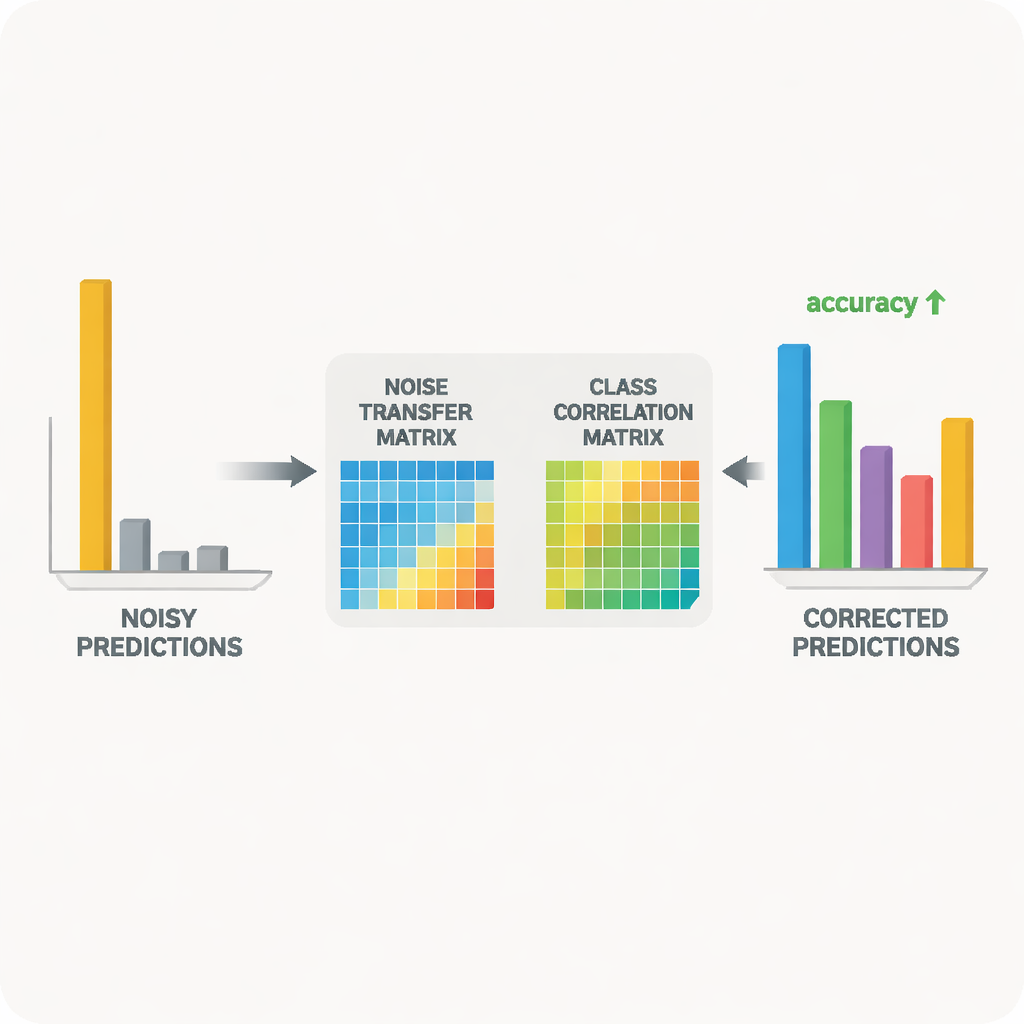
В основе системы — пара нейронных сетей учитель–ученик. Учитель основан на крупной самоконтролируемой визуальной модели, которая извлекла богатые визуальные признаки из огромных объёмов немаркированных данных. Ученик — более лёгкая сеть, которая должна хорошо работать на шумных целевых данных. Учитель выдаёт «мягкие» предсказания, которые показывают взаимосвязь между классами; на основе этих оценок строится матрица корреляции классов, суммирующая, какие метки склонны сосуществовать. Эта матрица служит ориентиром, подталкивая матрицу переноса шума к более реалистичным исправлениям. Одновременно ученик обучается подражать поведению учителя посредством дистилляции, а контрастивное обучение поощряет обе сети давать схожие внутренние представления для разных аугментированных видов одного и того же изображения и различать представления разных объектов.
Стабильность исправлений и борьба с чрезмерной уверенностью
Если позволить матрице переноса шума меняться свободно, она может стать нестабильной или чрезмерно чувствительной к выбросам. Чтобы этого избежать, авторы используют математический приём, основанный на сингулярном разложении, который разбивает матрицу на основные направления растяжения. Наказывая общий «объём», задаваемый этими направлениями, метод препятствует экстремальным искажениям, которые усиливали бы шум. Другая проблема возникает, когда модель становится слишком уверенной в своих предсказаниях, распределяя почти всю вероятность на один класс; при таких резких предсказаниях трудно корректировать ошибочные метки. Для этого вводится регуляризация энтропии на основе энтропии Цалса, которая сглаживает вероятности предсказаний. Это облегчает частичное перераспределение массы вероятности матрицей переноса шума с неверного класса в более правдоподобные альтернативы.
Доказательство идеи на реальных коллекциях изображений
Исследователи протестировали свой подход на двух широко используемых бенчмарках для перекрёстного распознавания объектов: Office‑31 и Office‑Home, которые содержат изображения повседневных офисных предметов в разных стилях, таких как товарные фото, клипарт и реальные снимки. В ряде задач «обучить в одном стиле — протестировать в другом» их метод сравнялся или превзошёл ведущие алгоритмы, особенно в самых сложных случаях, где сдвиг между доменами максимален. Детальные исследования показали, что каждый компонент — контроль объёма для матрицы шума, руководство по корреляции классов и сглаживание энтропии — вносил измеримый вклад. Визуализации изученной матрицы и пространства признаков подтвердили, что в ходе обучения ошибочно размеченные примеры постепенно притягивались к своим правильным категориям, а распределения исходных и целевых изображений становились лучше выровненными.
Что это значит для повседневных систем ИИ
Для неспециалиста главное: эта работа делает модели ИИ более терпимыми к ошибкам людей и машин при разметке данных, особенно когда модели переносятся из чистых лабораторных условий в более беспорядочную реальность. Явно изучая, как метки склонны искажаться, и используя мощную модель‑учителя для руководства исправлениями, метод способен очистить шумные тренировочные сигналы и дать более точные, более надёжные классификаторы. Хотя подход требует дополнительных вычислений, он указывает путь к будущему, в котором большие несовершенные наборы данных, собранные «в природе», можно безопаснее и эффективнее использовать, снижая зависимость от кропотливой ручной разметки.
Цитирование: Feng, Y., Liu, J. & Zhong, H. Correcting noisy labels via comparative distillation: a domain adaptation approach. Sci Rep 16, 7422 (2026). https://doi.org/10.1038/s41598-026-37935-8
Ключевые слова: шумные метки, адаптация домена, дистилляция знаний, классификация изображений, полу‑контролируемое обучение