Clear Sky Science · ru
Чувствительные к риску двойные распределённые критики с лямбда‑нижней доверительной границей для обучения с подкреплением в задачах непрерывного управления
Обучение роботов осторожности
Многие из наиболее впечатляющих сегодня роботов и программ для игр опираются на обучение с подкреплением — процесс обучения методом проб и ошибок, в котором программные агенты учатся, собирая вознаграждения. Но такие агенты часто гонятся за максимально возможным счётом, игнорируя риск своих решений, что приводит к неустойчивому обучению и иногда к авариям. В этой работе представлен метод под названием TDC-λ (Twin Distributional Critics with a Lambda Lower Confidence Bound), который учит агентов не только стремиться к высоким результатам, но и сохранять надёжную безопасность в процессе обучения.
Почему стабильность важна в обучающихся системах
Стандартные алгоритмы для задач непрерывного управления, такие как широко распространённые TD3 и Soft Actor–Critic (SAC), позволили роботам бегать, прыгать и балансировать в сложных симуляторах. Однако эти методы обычно оценивают каждое действие одним числом: оценкой ожидаемого вознаграждения в долгосрочной перспективе. Такое упрощённое число может вводить в заблуждение при шумном процессе обучения, заставляя систему переоценивать качество некоторых действий. В результате кривая обучения может выглядеть убедительно в среднем, но сильно варьироваться между запусками, что проблематично, если тот же алгоритм должен управлять реальными машинами или системами с критичными требованиями к безопасности.
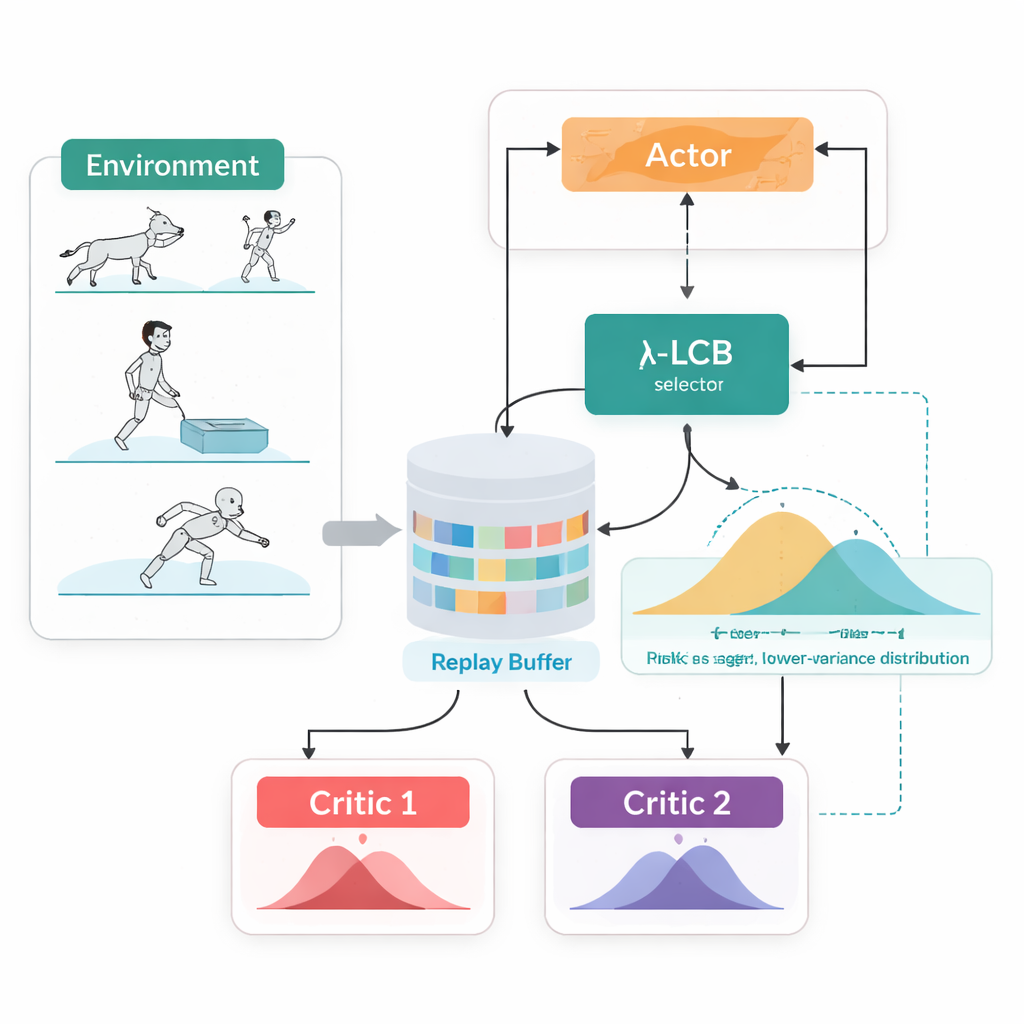
Смотреть на полные будущие распределения, а не на отдельные числа
TDC-λ решает эту проблему, изменяя способ оценки будущего агентом. Вместо прогнозирования одного ожидаемого вознаграждения для каждого действия он обучает два отдельных «критика», каждый из которых выдаёт полное распределение возможных будущих возвратов. Из этих распределений алгоритм вычисляет не только средний результат, но и разброс возможных исходов. Этот разброс отражает неопределённость или риск. Используя простое правило, сформулированное как нижняя доверительная граница, TDC-λ предпочитает критика, предсказывающего более безопасный исход: возможно, чуть менее оптимистичный, но подтверждённый более последовательными доказательствами. Один параметр, λ, плавно регулирует степень осторожности — от поведения, подобного обычному TD3 при λ = 0, до более консервативного выбора при увеличении λ.
Один цикл обучения, два способа выбора действий
Ещё одна практическая особенность TDC-λ в том, что он поддерживает как детерминированные, так и стохастические способы выбора действий в единой системе. Во время обучения можно выбрать классическую детерминированную политику или гауссовскую политику с tanh‑сквошингом, которая семплирует действия и стимулирует исследование. Независимо от этого выбора, двойные распределённые критики обучаются одинаково, а при оценке всегда используется детерминированное среднее действие. Такая конструкция опирается на предыдущие наблюдения, что детерминированное поведение во время тестирования часто показывает результаты не хуже, а иногда и лучше, чем семплирование, при этом во время обучения сохраняется богатство исследовательского поведения.
Проверка метода на практике
Авторы оценивали TDC-λ на пяти популярных задачах из набора MuJoCo, где смоделированным роботам (HalfCheetah, Hopper, Ant, Walker2d и Humanoid) нужно научиться эффективно двигаться. По всем этим задачам новый метод сопоставим или превосходит по финальной производительности сильные базовые алгоритмы, включая TD3, DDPG, SAC и продвинутый потоково‑основанный подход MEOW, при этом неизменно демонстрируя меньшую вариативность между запусками. В более сложных высокоразмерных задачах, таких как Humanoid, немного большие значения λ — то есть более осторожные целевые оценки — приводили к лучшим долгосрочным возвратам и более узким интервалам производительности. Дополнительные эксперименты в других симуляторах (PyBullet и NVIDIA Isaac) и диагностике, отслеживающей изменчивость сигнала обучения, подтвердили вывод о том, что TDC-λ делает обучение более стабильным, не замедляя его.
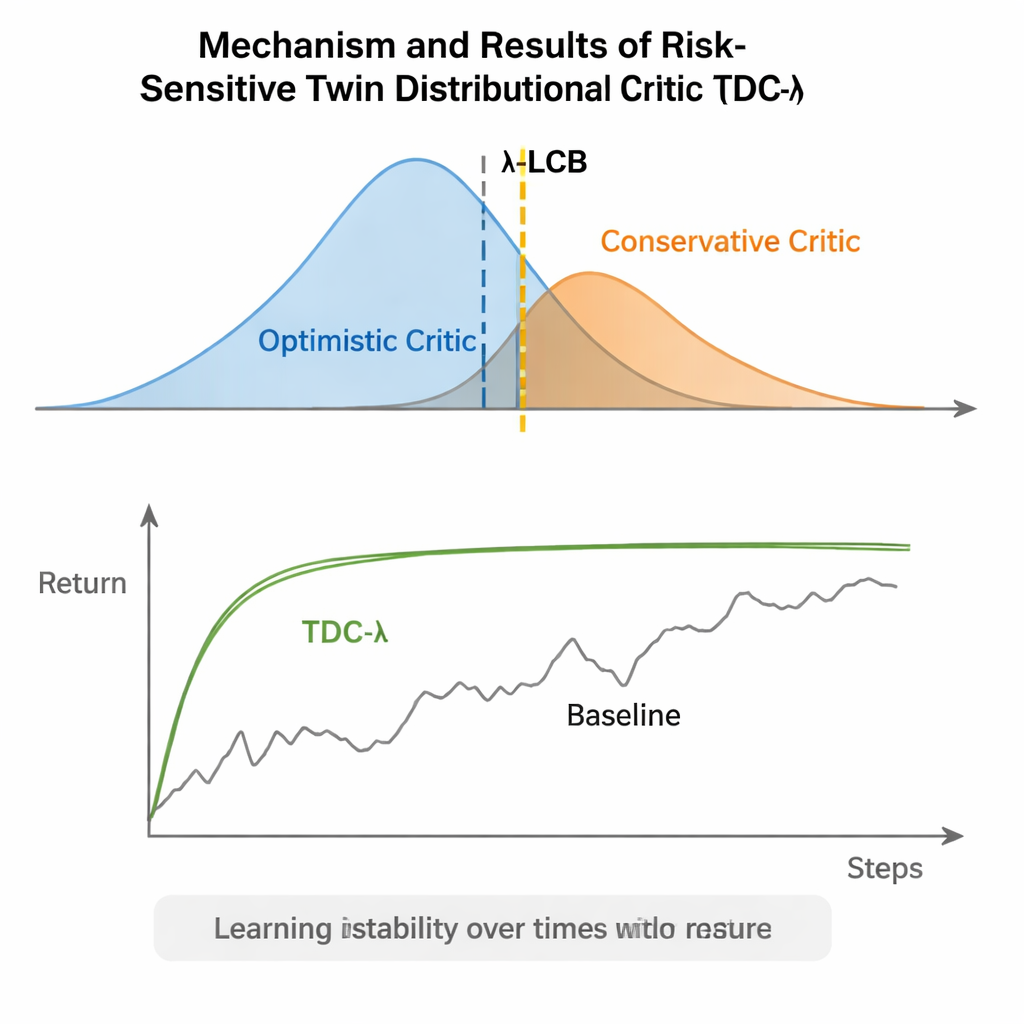
Простая регулировка для более безопасного обучения
Проще говоря, TDC-λ даёт системам обучения с подкреплением «запас прочности» при решении, насколько доверять собственной оптимистичности. Обучая полные распределения возможных исходов и затем склоняясь в сторону более безопасного критика с помощью регулятора λ, алгоритм уменьшает резкие колебания в обучении, сохраняя при этом высокую финальную производительность. Для практиков это даёт удобный инструмент для создания более надёжных контроллеров для роботов и других систем непрерывного управления: начните с умеренно консервативного λ и корректируйте его в зависимости от того, насколько волатильным кажется процесс обучения. Более общий вывод таков: тщательное формирование целей обучения — тех целевых значений, на которых обучается агент — может обеспечить большую часть устойчивости, которую часто приписывают более сложным архитектурам, делая продвинутое обучение с подкреплением более стабильным и доступным.
Цитирование: Osman, O., Yalcin Kavus, B., Karaca, T.K. et al. Risk sensitive twin distributional critics with a lambda lower confidence bound for continuous control reinforcement learning. Sci Rep 16, 6699 (2026). https://doi.org/10.1038/s41598-026-37910-3
Ключевые слова: обучение с подкреплением, непрерывное управление, обучение, чувствительное к риску, распределённые критики, робототехника