Clear Sky Science · ru
Эффективное обнаружение вторжений в наборе данных TON-IoT с использованием гибридного подхода выбора признаков
Почему защита умных устройств важна
Миллиарды повседневных устройств — от домашних камер до промышленных датчиков — теперь общаются друг с другом через интернет, образуя так называемый Интернет вещей (IoT). Хотя эта связность приносит удобство и эффективность, она также открывает новые двери для хакеров. В статье, которую здесь резюмируют, рассматривается простой, но важный вопрос: как надежно обнаруживать атаки в этих разрастающихся сетях устройств без использования тяжелого, энергозатратного программного обеспечения безопасности?
Проблема обнаружения цифровых взломов
Чтобы изучать атаки на IoT-системы, исследователи часто полагаются на большие публичные наборы данных, фиксирующие, как выглядит сетевой трафик при нормальной работе и во время кибератак. Один из наиболее широко используемых — набор данных ToN-IoT, который содержит реальный трафик с реалистичной промышленной испытательной площадки и включает множество типов атак, таких как отказ в обслуживании, вымогательское ПО, подбор паролей и перехват трафика «man-in-the-middle». Авторы показывают, однако, что в этом наборе данных есть скрытая ловушка: многие атаки запускались из фиксированных диапазонов IP-адресов и портов. Это означает, что модель может «обманывать», изучая, кто является атакующим, вместо того, чтобы распознавать сами вредоносные паттерны. Такие модели могут показывать очень высокие результаты в лаборатории, но катастрофически провалиться, когда атака исходит с нового адреса.
От громоздких данных к лаконичному представлению поведения
Исходные сетевые данные ToN-IoT содержат 44 различных показателя для каждого соединения — от IP-информации до деталей веб- и зашифрованного трафика. Обработка всех этих признаков увеличивает время вычислений и требования к памяти, что проблематично для небольших IoT-шлюзов и устройств на периферии. Авторы сначала, опираясь на понимание механики атак, отбрасывают признаки, которые либо смещены (такие как IP-адреса и номера портов), либо мало помогают различать атаки. Они утверждают, что большинство угроз в IoT в конечном счете проявляются как странные шаблоны в объеме отправленных и полученных пакетов и байт, а также в длительности соединений — независимо от того, кто с кем общается. Этот первый этап сокращает набор признаков с 44 до семи ключевых статистик трафика, связанных с объемом и продолжительностью.
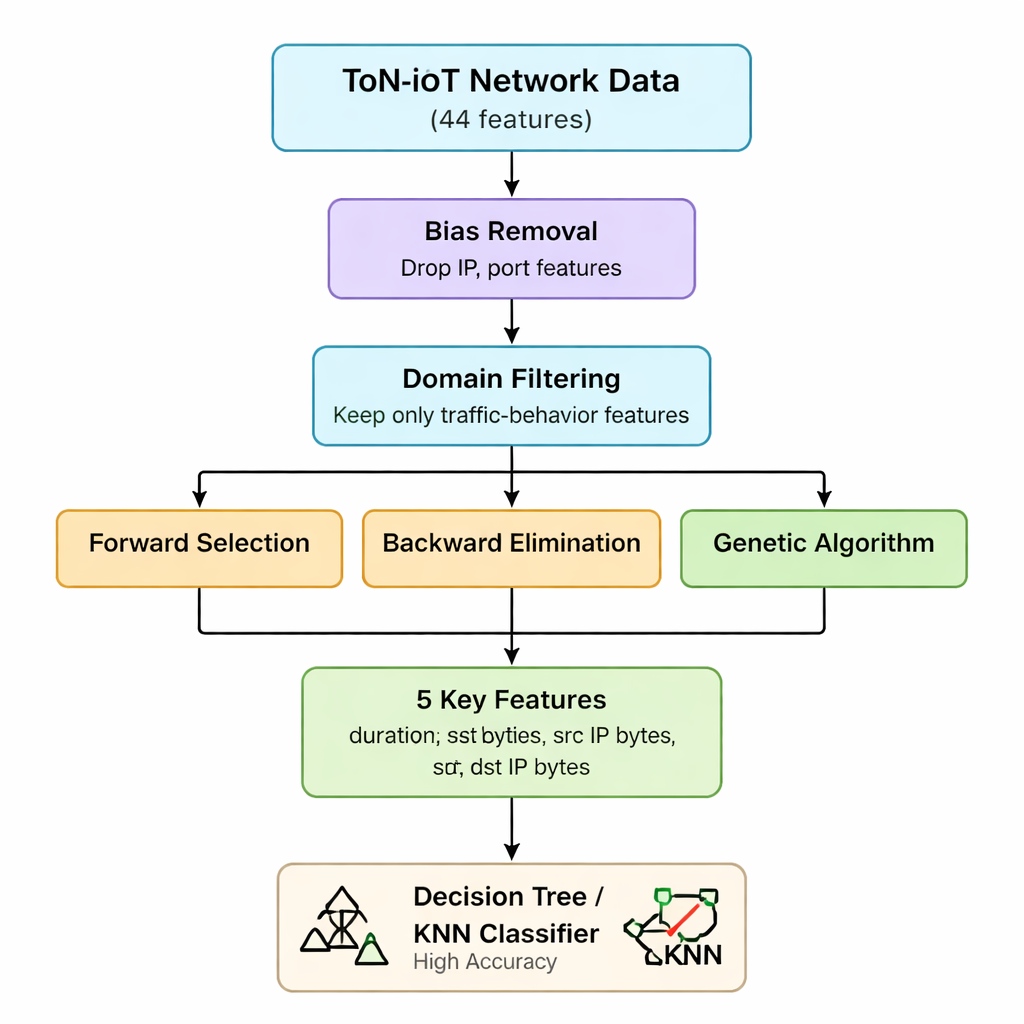
Гибридный выбор признаков: три подхода к одним и тем же данным
Далее команда применяет три разных «обёртки» (wrapper) — методы, которые многократно обучают модель, добавляя, удаляя или перестраивая признаки, чтобы увидеть, какой набор действительно важен. Метод прямого (forward) отбора наращивает набор от пустого, оставляя признак только если он повышает точность. Обратный (backward) отбор начинает со всех семи и удаляет те признаки, удаление которых не ухудшает точность. Генетический алгоритм параллельно исследует множество комбинаций, эволюционируя лучшие подмножества по поколениям. Все три метода тестируют с использованием простого классификатора на основе дерева решений, а мерой служит точность. Пересечение результатов приводит авторов к стабильному ядру из пяти признаков: длительность соединения, байты отправленные, байты полученные и соответствующие им IP-уровневые счётчики байтов. Эти пять переменных эффективно фиксируют аномальные всплески или дисбалансы в трафике, сигнализирующие о многих типах атак.
Лёгкие модели с высокой эффективностью
С этим уменьшенным и ориентированным на поведение набором данных исследователи оценивают, насколько хорошо простые модели машинного обучения умеют отличать безопасный трафик от атак. Используя только пять выбранных признаков, дерево решений достигает 98,6% точности для бинарной классификации «атака vs нормальное» и 97,2% точности при различении нескольких категорий атак. Модель k-ближайших соседей показывает схожую производительность, а более сложные ансамблевые методы, такие как случайный лес или градиентный бустинг, дают лишь незначительные улучшения, потребляя при этом больше вычислительных ресурсов и памяти. Важно, что авторы подтверждают с помощью статистических тестов, что выбранные ими признаки действительно информативны, а не являются артефактами способа сбора данных. Они отмечают, что тонкие man-in-the-middle-атаки, предназначенные для маскировки под нормальные потоки, по-прежнему сложнее обнаруживать, что указывает на то, что для таких случаев в будущем могут потребоваться более богатые подсказки протоколов или временных характеристик.
Что это значит для реальной безопасности
Для неспециалистов ключевая мысль такова: не всегда нужны громоздкие модели или десятки технических измерений, чтобы защищать IoT-системы. Отбросив признаки, которые работают только в одной лабораторной настройке, и сосредоточившись на нескольких поведенческих характеристиках трафика, авторы показывают, что простые и быстрые алгоритмы всё ещё могут обнаруживать большинство атак с высокой надёжностью. Их пятипризнаковая версия набора ToN-IoT проще в обработке на ограниченных по ресурсам устройствах на краю сети, что делает её практичной для маршрутизаторов, шлюзов и небольших хабов, которые должны реагировать на угрозы в реальном времени. Кратко говоря, исследование предлагает путь к более надёжному и внедряемому обнаружению вторжений для повседневных умных устройств, которые всё больше окружают нас.
Цитирование: Dharini, N., Janani, V.S. & Katiravan, J. Efficient detection of intrusions in TON-IoT dataset using hybrid feature selection approach. Sci Rep 16, 7763 (2026). https://doi.org/10.1038/s41598-026-37834-y
Ключевые слова: Безопасность IoT, обнаружение вторжений, машинное обучение, выбор признаков, сетевой трафик