Clear Sky Science · ru
Сравнительный анализ результатов больших языковых моделей на экзамене по стоматологической специальности
Почему умные чат-боты важны для будущих стоматологов
Искусственный интеллект быстро меняет способы обучения и работы врачей и стоматологов. Одним из самых заметных инструментов являются разговорные чат-боты на базе больших языковых моделей — та же технология, что лежит в основе многих популярных AI-ассистентов. В этом исследовании был поставлен простой, но важный вопрос: если бы студенты стоматологии использовали эти инструменты для подготовки к очень конкурентному специализированному экзамену по рентгенологии челюстно-лицевой области, насколько хорошо машины справились бы на самом деле?
Тестирование ИИ на реальном экзамене
Чтобы выяснить это, исследователи обратились к экзамену по поступлению в специализацию по стоматологии (DUS) в Турции, который помогает определить, кто может поступить в программы углублённой подготовки. Из прошлых лет этого общенационального теста они отобрали 208 вопросов с вариантом ответа, охватывающих темы, которые должны знать специалисты по рентгенологии: от физики излучения и методов визуализации до опухолей челюсти и заболеваний пазух. Большинство вопросов было только текстовыми, но меньшая часть требовала интерпретации рентгенологических изображений, что отражает реальную диагностическую практику.
Семь чат-ботов проходят одинаковое испытание
Команда задала каждый вопрос на турецком языке семи широко используемым AI-чат-ботам, основанным на разных больших языковых моделях: двум версиям ChatGPT, а также Gemini, Copilot, DeepSeek, Claude и Grok. Каждый вопрос вводили внимательно и отдельно, чтобы избежать переноса контекста между беседами. Второй исследователь сравнивал каждый ответ ИИ с официальным ключом и отмечал его как правильный или неправильный. Наконец, авторы применили стандартные статистические тесты для сравнения моделей в целом и по отдельным предметным областям.
Кто набрал больше всего — и где они давали сбои
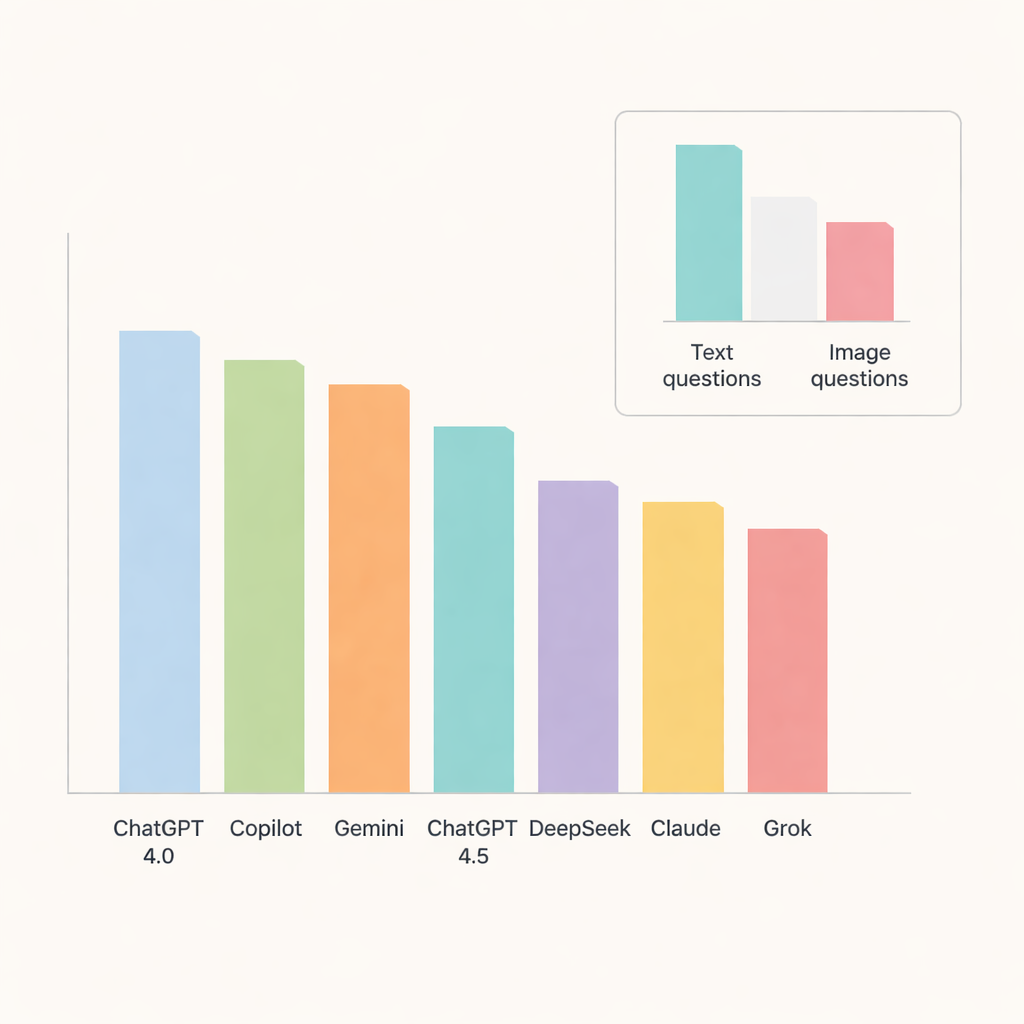
Среди всех чат-ботов выделился ChatGPT 4.0, правильно ответив примерно на 91 процент вопросов. Copilot и Gemini следовали за ним с точностью около середины — верхних 80-х процентов, тогда как ChatGPT 4.5, DeepSeek, Claude и Grok отставали в некоторой степени. При углублённом анализе по темам модели особенно хорошо справлялись с оральной патологией и заболеваниями слюнных желёз, где точность достигала или превышала 90 процентов. Напротив, рентгеноанатомия и кальцификации мягких тканей оказались заметно сложнее, что снижало показатели в этих разделах и указывало на области, где ИИ всё ещё испытывает трудности с тонкими деталями.
Изображения по-прежнему сложнее слов
Ключевой проверкой было то, насколько чат-боты справляются с изображениями по сравнению с текстом. Здесь проявились их ограничения. Точность резко падала на вопросах с изображениями, даже у лучших моделей. ChatGPT 4.0, Gemini и Copilot лидировали в этой категории, но всё равно давали правильные ответы лишь примерно на две трети визуальных вопросов. DeepSeek показывал худший результат на изображениях — чуть более трети правильных ответов. Для большинства моделей разница между текстовыми и визуальными задачами была достаточно велика, чтобы быть статистически значимой, что подчёркивает: интерпретация медицинских изображений остаётся сложной задачей для современных универсальных ИИ.
Что это означает для студентов и пациентов
Вывод исследования таков: современные чат-боты могут быть мощными помощниками в стоматологическом образовании, особенно при повторении фактов и практической подготовке к экзаменам по рентгенологии. Однако даже самые сильные системы совершают достаточно ошибок — особенно в визуально требовательных или очень специфических темах — чтобы их нельзя было безопасно заменить экспертную оценку. Для студентов и клиницистов эти инструменты лучше рассматривать как умных партнёров по обучению или вспомогательные средства при принятии решений, но не как самостоятельные авторитеты. При использовании с надлежащей осторожностью и надзором они могут ускорить обучение и расширить доступ к качественным объяснениям, тогда как окончательная ответственность за диагноз и лечение остаётся за подготовленными специалистами.
Цитирование: Geduk, G., Hasırcı, U.C., Kusay, D.D. et al. A comparative analysis of the performance of large Language models in the dentistry specialty examination. Sci Rep 16, 6739 (2026). https://doi.org/10.1038/s41598-026-37800-8
Ключевые слова: стоматологическое образование, искусственный интеллект, большие языковые модели, рентгенология челюстно-лицевой области, медицинские экзамены