Clear Sky Science · ru
Обнаружение SMS-спама между языками с использованием GAN-увеличения для несбалансированных наборов данных
Почему вашим текстовым сообщениям всё ещё нужна защита
Большинство из нас полагает, что нежелательные сообщения тихо попадают в папку «спам», но за кулисами это очень сложная задача. Реальный спам встречается гораздо реже по сравнению с повседневными сообщениями и всё чаще проявляется сразу на нескольких языках. В этой статье предложен новый способ выявления опасного SMS-спама, сочетающий мощные языковые модели с хитрым генератором «поддельных данных», чтобы фильтры могли учиться на гораздо большем количестве примеров вредоносных сообщений, не подвергая риску вашу приватность.
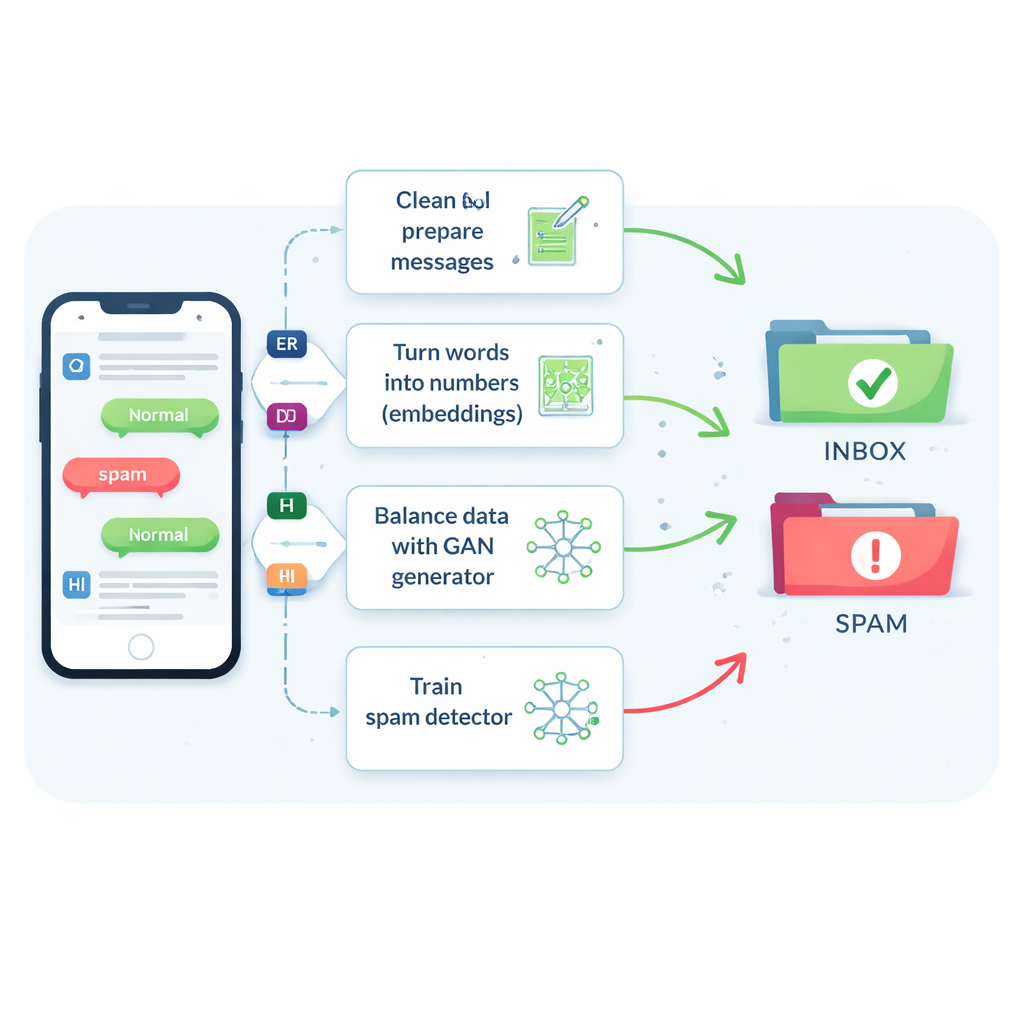
Проблема редкого и изменяющегося спама
Спам-сообщения составляют лишь примерно одно из семи сообщений, но пропуск даже небольшой их доли может подвергнуть людей мошенничеству, вредоносному ПО и краже личности. Традиционные фильтры испытывают трудности, потому что SMS короткие, полны сленга и аббревиатур и приходят в реальном времени без дополнительного контекста. В результате многие системы склонны отмечать сообщения как безопасные — это радует пользователей, но пропускает больше вредоносных текстов. Старые приёмы, которые просто дублируют спам или создают новые варианты путём редактирования слов, помогают немного, но часто путают фильтр или создают нереалистичные примеры, не соответствующие тому, что на самом деле рассылают злоумышленники.
Обучение машин понимать смысл сообщений
Авторы начинают с сравнения восьми различных алгоритмов обучения — от привычных инструментов, таких как методы опорных векторов и деревья решений, до более продвинутых нейросетей, читающих текст как последовательность, например сетей долгой краткосрочной памяти (LSTM). Они также тестируют пять способов превращения слов в числа, которые может использовать компьютер. Простые подсчёты частоты слов (известные как «мешок слов» или TF–IDF) быстры, но слепы к значению. Новые «встраивания» (embeddings) вроде Word2Vec и GloVe размещают слова с похожим смыслом рядом в числовом пространстве. Наиболее продвинуты трансформерные модели, такие как BERT, которые корректируют представление слова в зависимости от окружающего предложения, помогая системе отличать, например, дружеское напоминание от убедительного мошеннического сообщения.
Использование умного «фэйкового» спама для исправления перекошенного набора данных
Главное новшество — подход к нехватке примеров спама. Вместо генерации полностью фальшивых предложений команда обучает тип нейросети, называемый генеративно-состязательной сетью (GAN), напрямую на числовых встраиваниях спам-сообщений. Одна часть GAN — генератор — учится создавать синтетические «спамоподобные» точки в этом высокоразмерном пространстве, тогда как другая — дискриминатор — учится отличать их от реальных. Через это соперничество генератор производит реалистичные новые встраивания спама, расширяя обучающую выборку. Проверка качества на основе сходства обеспечивает сохранение только тех синтетических примеров, которые тесно похожи на подлинный спам, снижая риск бессмысленных данных, способных ввести классификатор в заблуждение.
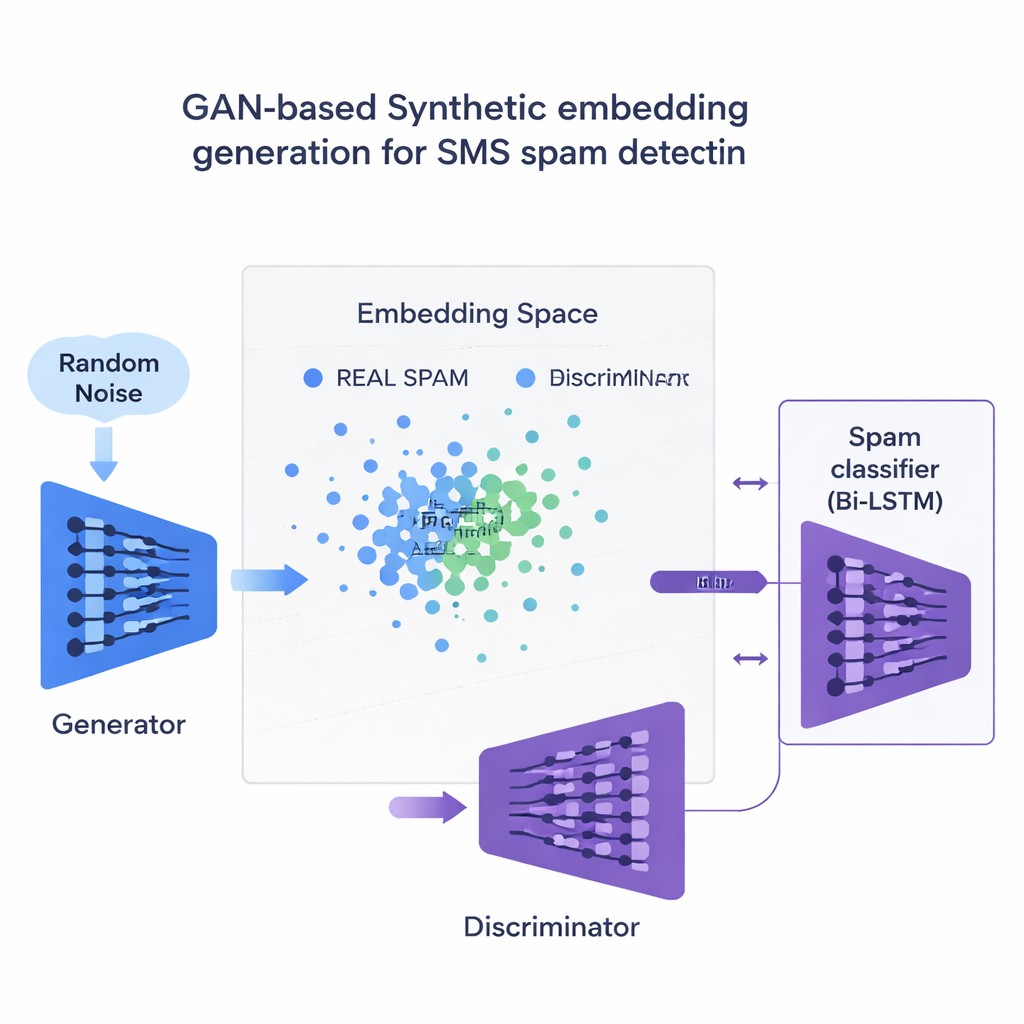
Результаты для разных языков и устройств
Исследователи тестируют 120 различных комбинаций моделей, встраиваний и методов балансировки данных как на наборе английских SMS, так и на многоязычной версии, переведённой на французский, немецкий и хинди. Во всех случаях контекстные встраивания вроде BERT превосходят старые подходы на основе подсчёта слов. Лучшая конфигурация — двунаправленный LSTM с BERT-встраиваниями, обученный на примерах спама, сгенерированных GAN — достигает F1-показателя примерно 97,6% на английских сообщениях и 94,4% на многоязычном наборе, слегка обгоняя существующие передовые системы. Существенно, что при этом количество ложных срабатываний остаётся чрезвычайно низким, что важно, чтобы одноразовые пароли и банковские оповещения не скрывались по ошибке. Исследование также сравнивает эту стратегию GAN с более распространёнными инструментами балансировки, такими как SMOTE и ADASYN, и обнаруживает, что GAN даёт более чистые, более реалистичные тренировочные данные и немного лучшее итоговое качество.
Что это значит для обычных пользователей
Для неспециалистов вывод таков: спам-фильтры начинают понимать смысл и контекст ваших сообщений, а не только отдельные слова, и их можно «обучать» с помощью тщательно сгенерированных синтетических данных, не требуя большего количества ваших реальных сообщений. Работая непосредственно в пространстве, где закодирован смысл сообщения, предложенный метод даёт системам безопасности более полное представление о том, как выглядит спам на многих языках, не наполняя их неуклюжими подделками. Это повышает вероятность того, что опасные сообщения будут пойманы, а подлинные — доставлены, обеспечивая более надёжную и адаптивную защиту для мобильных пользователей по мере того, как мошенники продолжают менять тактику.
Цитирование: Filali, A., Shorfuzzaman, M., Abdellaoui Alaoui, E. et al. Cross-lingual SMS spam detection using GAN-based augmentation for imbalanced datasets. Sci Rep 16, 7128 (2026). https://doi.org/10.1038/s41598-026-37769-4
Ключевые слова: обнаружение SMS-спама, увеличение данных GAN, векторные представления текста BERT, многоязычная кибербезопасность, мобильный фишинг