Clear Sky Science · ru
Легковесная архитектура сверточной нейронной сети для обнаружения насилия в видеопоследовательностях
Наблюдение за толпой, чтобы людям этого не приходилось делать
От концертов и спортивных арен до станций метро и торговых центров — камеры теперь следят почти за каждым многолюдным пространством. Тем не менее большинство видеопотоков по‑прежнему просматриваются уставшими глазами операторов, которые легко могут пропустить первые признаки драки или паники. В этой работе исследуется, как тонкая и быстрая форма искусственного интеллекта может в реальном времени сканировать живое видео на предмет насильственного поведения даже на недорогом оборудовании, помогая службе безопасности оперативно реагировать до того, как ситуация выйдет из‑под контроля.
Почему обнаружить насилие на видео так сложно
На первый взгляд попросить компьютер отличить «драку» от «не драки» кажется просто: достаточно обнаружить, что люди наносят друг другу удары. На практике задача гораздо сложнее. Освещение может быть плохим или внезапно меняться, толпа может закрывать обзор, а камеры установлены под разными углами. Оживлённый рок‑концерт выглядит хаотично, даже если ничего опасного не происходит, в то время как боксёрский поединок кажется жестоким, но является нормой в ринге. Традиционные системы зрения анализировали вручную разработанные шаблоны движения и контуры покадрово — и хоть они работали в лаборатории, на загруженных реальных системах видеонаблюдения часто оказывались слишком медленными или неточными.
Более экономичный «мозг» для видеопотоков
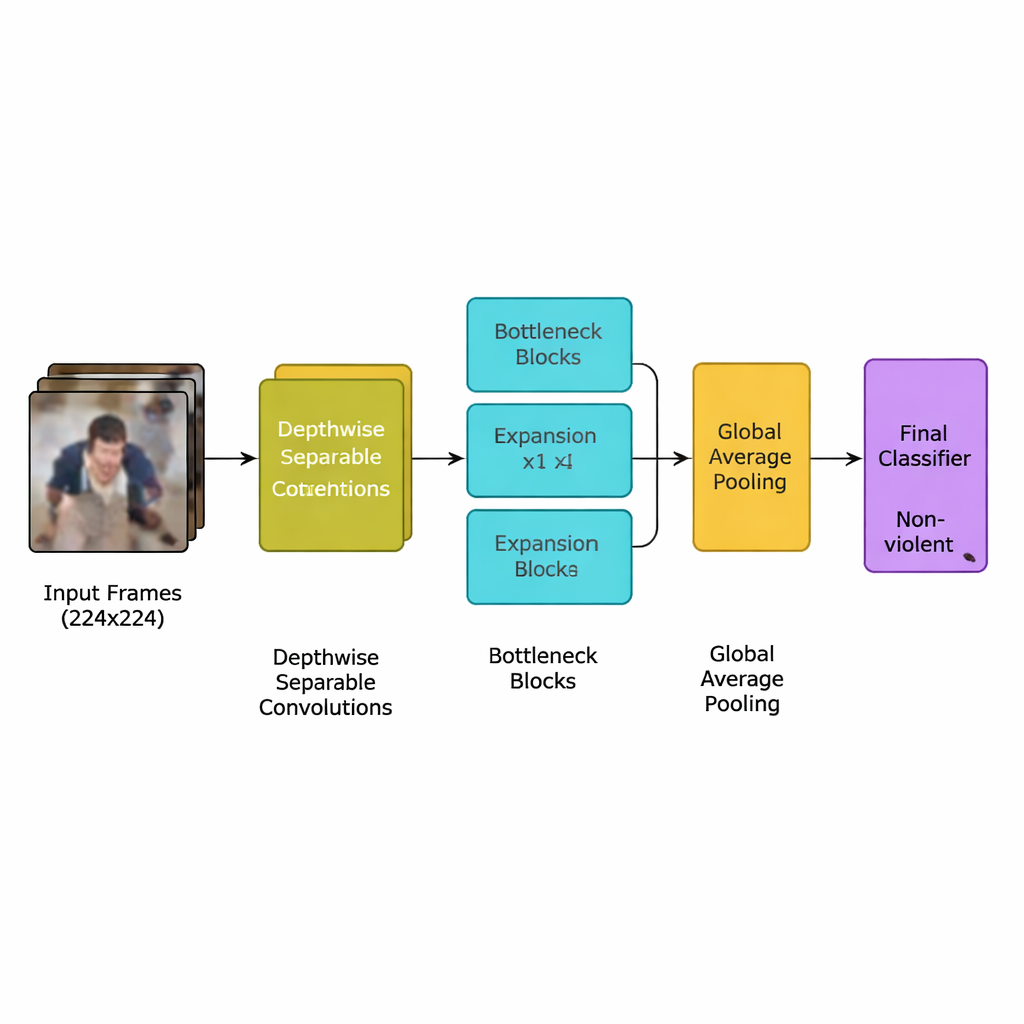
Авторы предлагают новую модель глубокого обучения, разработанную специально для этой задачи: легковесную сверточную нейронную сеть (CNN), выведённую из эффективного семейства моделей MobileNetV2. Вместо множества тяжёлых слоёв, требующих мощных графических процессоров, сеть опирается на пространственно‑пооктавные (depthwise separable) свёртки — небольшие целевые вычисления, которые значительно сокращают количество операций. Она также использует блоки с «инвертированным бутылочным горлышком», которые кратковременно расширяют и затем сжимают представление, сохраняя важные признаки движения и устраняя избыточность. Поверх этого команда добавляет механизм внимания squeeze‑and‑excitation, что помогает сети сфокусироваться на пространственно‑временных паттернах движения, типичных для насильственных инцидентов, и игнорировать отвлекающие фоновые детали.
От необработанного видео до предупреждений о насилии
Полная система следует ясному конвейеру. Сначала видеопотоки разбиваются на кадры, при этом сохраняется только каждый пятый кадр, чтобы убрать почти‑дубликаты и при этом сохранить резкие движения, которые часто сигнализируют о драке. Кадры масштабируются до стандартного размера 224×224 пикселя, слегка размываются для снижения фонового шума и затем случайным образом переворачиваются или поворачиваются при обучении, чтобы модель научилась работать с разными ракурсами камеры. Эти подготовленные изображения подаются в легковесную CNN, которая постепенно преобразует сырые пиксели в более высокоуровневые паттерны поведения толпы. После финального шага пуллинга, суммирующего каждый кадр, небольшой классификатор выдаёт простое решение: насилие или отсутствие насилия. Поскольку модель использует примерно 1,94 миллиона параметров — меньше, чем у её предшественников MobileNet и MobileNetV2 — она может работать в реальном времени на скромных устройствах, размещённых рядом с камерами, а не в удалённом дата‑центре.
Проверка системы
Чтобы понять, сможет ли эта компактная конструкция конкурировать с более объёмными сетями, исследователи обучили и оценили её на двух широко используемых наборах данных. Real‑Life Violence Situations Dataset содержит 2000 коротких клипов, собранных с YouTube, показывающих как повседневные сцены, так и реальные драки в разных локациях. Hockey Fight Dataset предлагает 1000 клипов с профессиональных хоккейных матчей, разделённых на обычную игру и массовые потасовки на льду. На этих наборах предложенная модель правильно классифицировала около 97 процентов клипов для реальных ситуаций и 94 процента для хоккейных эпизодов, сопоставимо или лучше, чем у более крупных CNN, таких как InceptionV3 и VGG‑19, при значительно меньших вычислительных затратах. Кросс‑тестирование между двумя наборами — обучение на одном и тестирование на другом — показало, что система по‑прежнему работает достаточно хорошо, что указывает на то, что она улавливает общие паттерны движения, а не запоминает одну среду.
Что это значит для повседневной безопасности
Для неспециалистов главное — теперь возможно создать камеры, которые автоматически помечают вероятное насилие быстро и дешёво, без гигантских серверов и постоянного человеческого контроля. Исследование показывает, что тщательно оптимизированная нейронная сеть может следить за множеством потоков одновременно, отправлять оповещения при обнаружении опасного поведения и при этом работать на маломощном оборудовании, подходящем для транспортных узлов, школ, больниц и городских улиц. Хотя остаются вызовы — например, обработка очень тёмных сцен, плотных толп или добавление звуковых сигналов — работа указывает на будущее, где «умные» камеры выступают неутомимыми датчиками раннего предупреждения, помогая командам безопасности эффективнее защищать людей и снижать нагрузку на человеческих наблюдателей.
Цитирование: Tyagi, B., Jain, R., Jain, P. et al. A lightweight convolutional neural network architecture for violence detection in video sequences. Sci Rep 16, 7557 (2026). https://doi.org/10.1038/s41598-026-37743-0
Ключевые слова: обнаружение насилия, видеонаблюдение, легковесный CNN, MobileNetV2, общественная безопасность