Clear Sky Science · ru
MSRCTNet: новая многомасштабная капсульная триплетная сеть для эффективного удаления избыточных кадров в видео беспроводной капсульной эндоскопии
Проглотить камеру, утонуть в изображениях
Представьте, что заболевания кишечника диагностируют, проглотив камеру размером с витаминную пилюлю, которая тихо фотографирует весь ваш пищеварительный тракт. Беспроводная капсульная эндоскопия уже делает это возможным, но каждое обследование порождает около 55 000 изображений, большинство из которых почти одинаковы. Врачам приходится просеивать этот визуальный поток, чтобы обнаружить крошечные участки кровотечения, воспаления или опухолей. Работа, лежащая в основе MSRCTNet, задаёт простой, но ключевой вопрос: может ли интеллектуальная система безопасно отбрасывать похожие кадры, чтобы врачи видели только действительно важное?
Почему слишком много снимков — проблема
Обычная эндоскопия требует гибкой трубки, вводимой через рот или прямую кишку, — процедура, которую многие пациенты считают неприятной и которая не всегда достигает всей тонкой кишки. Капсульная эндоскопия решает эту проблему, позволяя «пилюле‑камере» дрейфовать по кишечнику и снимать кадр каждую секунду. Минус — перегрузка: лишь около 1% кадров содержат явно полезную информацию, тогда как остальные в основном повторяют одни и те же складки ткани. Просмотр таких объёмов медленный и утомительный, что повышает риск пропуска тонкой патологии врачом. Ранние компьютерные методы пытались помочь кластеризацией похожих кадров, сжатием данных или простыми признаками цвета и текстуры, но часто терпели неудачу при изменении освещения, сложных движениях кишечника или когда редкие аномалии встречались всего несколько раз.
Более разумный способ находить повторы
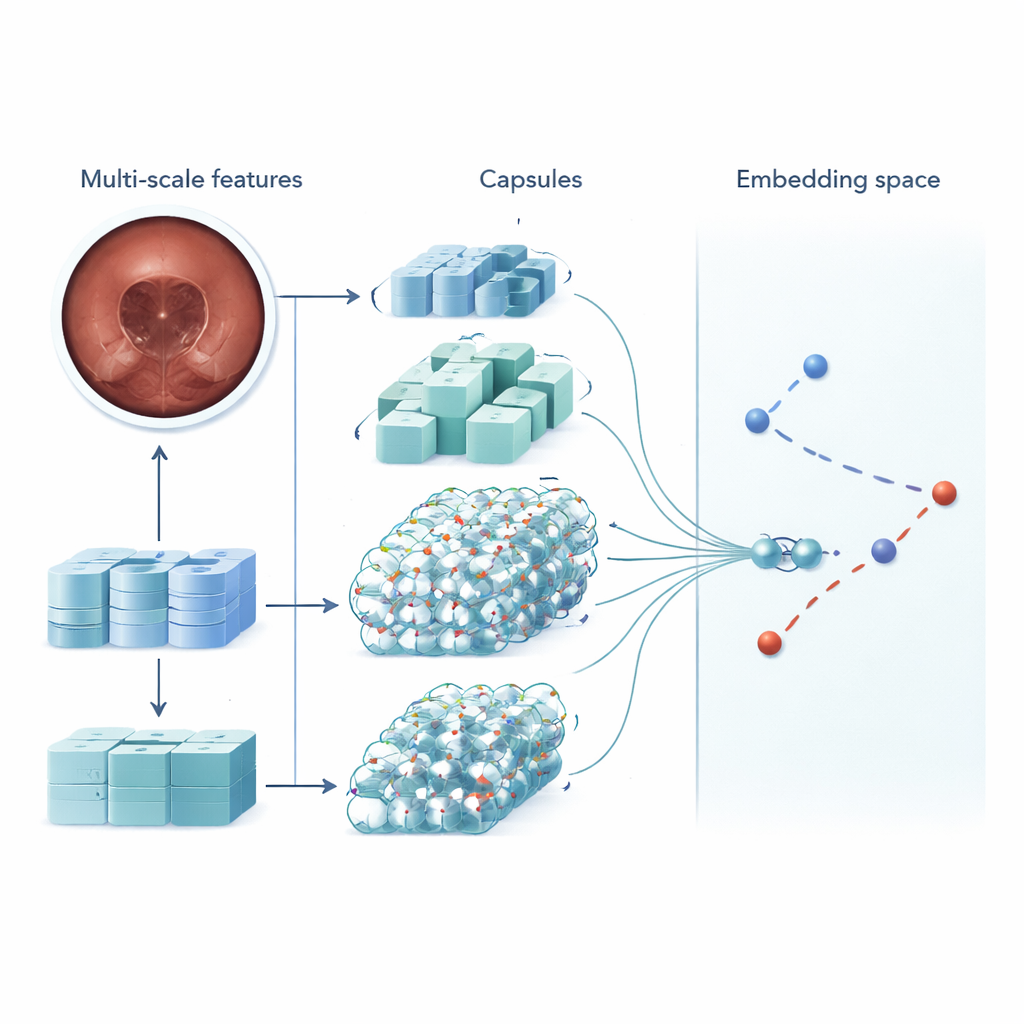
MSRCTNet (Multi‑Scale Capsule Triplet Network) — система глубокого обучения, разработанная в качестве интеллектуального фильтра для видеозаписей из капсулы. Вместо того чтобы рассматривать каждое изображение как плоскую картинку, система анализирует шаблоны одновременно на нескольких масштабах — тонкие текстуры слизистой и более крупные формы стенки кишечника — и использует механизм внимания, чтобы выделить наиболее информативные детали. Эти обогащённые признаки затем передаются в капсульный слой, сохраняющий пространственные отношения между частями изображения, например ориентацию и расположение складок или поражений. Наконец, специализированный модуль схожести сравнивает триплеты кадров — эталонное изображение, кадр, который должен быть похож, и кадр, который должен отличаться — чтобы научиться представлению, в котором действительно избыточные кадры плотно группируются, а отличительные кадры стоят отдельно.
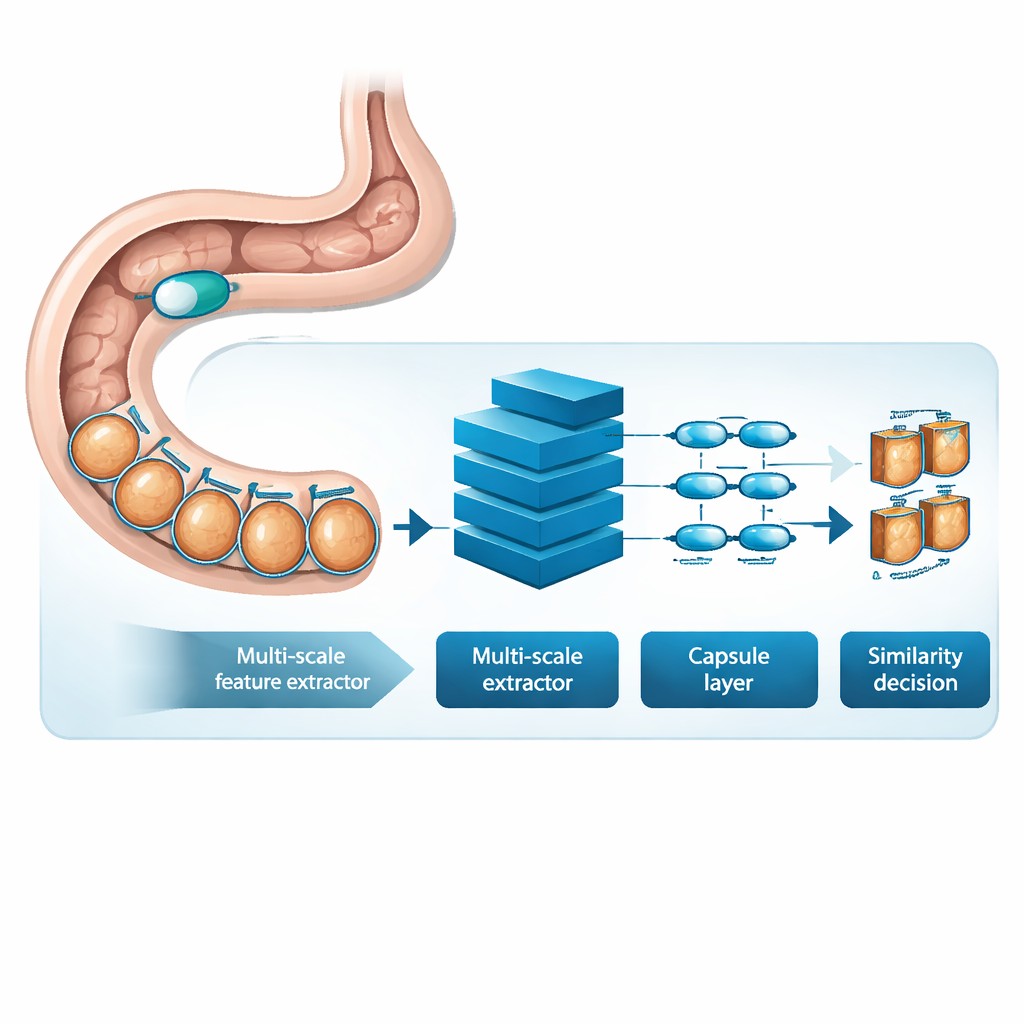
Обучение на реальных обследованиях пациентов
Чтобы протестировать MSRCTNet, исследователи собрали крупный набор данных из 257 362 изображений, полученных в 60 капсульных обследованиях, проведённых в госпитале в Китае. Снимки включали нормальную ткань, участки, закрытые пузырьками, и явные аномалии, такие как кровотечение и воспаление, — все они были размечены опытными клиницистами. Система обучали судить, являются ли пары кадров похожими или нет, используя комбинацию двух целей обучения: одну, которая стягивает кадры из одной категории и раздвигает кадры из разных категорий, и другую, которая прямо учит сеть говорить, похожа ли пара. После обучения модель просматривает видео по три кадра одновременно и решает, какие соседние изображения действительно избыточны. Применяя простые правила к этим решениям о схожести, она удаляет повторяющиеся виды, сохраняя при этом представительские ключевые кадры.
Скорость, точность и меньше пропущенных проблем
На тестовых данных MSRCTNet корректно обрабатывала избыточность кадров примерно в 96% случаев, с уровнем ложных тревог ниже 3% и долей пропущенных кадров менее 0,2%. На практике для обследования из 50 000 кадров это соответствует пропуску менее чем 100 потенциально релевантных кадров — настолько мало, что окружающие изображения всё ещё дают контекст при шести кадрах в секунду. По сравнению с несколькими ранними методами на основе кластеризации, анализа движения или более простых нейронных сетей, MSRCTNet показала большую точность и устойчивость при несбалансированных данных, то есть когда нормальных изображений значительно больше, чем редких поражений. Система также работала быстро: примерно 0,02 секунды на кадр, или около 15 минут, чтобы сократить полноценное обследование до примерно 2 500 ключевых кадров — объёма, намного более удобного для человеческого просмотра.
Что это значит для пациентов и врачей
Для пациентов описанное в статье достижение не меняет капсулу, которую они проглатывают, но может сделать обследование более эффективным. Автоматически отсеивая почти дубликатные изображения без ручной настройки порогов или хрупких эвристик, MSRCTNet позволяет клиницистам сосредоточиться на кратком, насыщенном информацией резюме путешествия по кишечнику. Подход сохраняет клинически важные находки, снижая усталость и время работы за консолью, что потенциально делает неинвазивные капсульные обследования более привлекательными и широко используемыми. По сути, метод превращает поток снимков в тщательно отобранный ролик с основными моментами, приближая обещание искусственного интеллекта к повседневной помощи при заболеваниях пищеварительной системы.
Цитирование: Li, Q., Wang, S., Cheng, Z. et al. MSRCTNet: a novel multi-scale capsule triplet network for efficient redundant frame removal in wireless capsule endoscopy videos. Sci Rep 16, 6902 (2026). https://doi.org/10.1038/s41598-026-37669-7
Ключевые слова: беспроводная капсульная эндоскопия, резюмирование медицинских видео, глубокое обучение, удаление избыточных кадров, визуализация желудочно-кишечного тракта