Clear Sky Science · ru
Оптимизация гиперпараметров для повышения эффективности моделей глубокого обучения при раннем обнаружении инвазивных черепах в Корее
Почему важно умнее распознавать черепах
Пресноводные черепахи могут выглядеть безобидно, загорая на камне, но когда чужеродные виды захватывают реки и пруды, они незаметно подталкивают местную фауну к исчезновению. В Корее сейчас наблюдается такая проблема: несколько инвазивных видов черепах распространяются через торговлю дикой природой и выпуск из домашнего содержания. В этом обзоре показано, как тонкая настройка искусственного интеллекта — в частности моделей глубокого обучения — может сделать автоматическое обнаружение черепах быстрее и точнее, предоставив защитникам природы мощный инструмент раннего предупреждения до того, как экосистемы будут необратимо повреждены.
Нежданные гости в местных водоемах
Инвазивные черепахи, такие как красноухая черепаха, были интродуцированы по всей Азии в результате глобальной торговли дикой природой. Освободившись, они конкурируют с местными животными за пищу и места для солнечных ванн, могут переносить болезни и часто лучше переносят потепление, чем аборигенные виды. В Корее шесть видов пресноводных черепах рассматриваются как инвазивные или представляющие высокий риск. Раннее их обнаружение имеет решающее значение, но традиционный мониторинг опирается на специалистов, посещающих множество водно-болотных угодий и затем тщательно проверяющих фотографии — работа точная, но медленная и ограниченная по охвату. По мере того как дроны, камеры‑ловушки и площадки гражданской науки, такие как iNaturalist, генерируют всё больше изображений, автоматический анализ изображений становится необходимым, чтобы успевать за потоком данных.
Обучение компьютеров распознавать черепах
Исследователи поставили задачу создать модель глубокого обучения, которая могла бы как обнаруживать инвазивных черепах на фотографиях, так и различать шесть видов. Они собрали тысячи изображений от участников iNaturalist и тщательно перепроверили каждое, удалив неверно идентифицированные и некачественные снимки. Для каждого пригодного изображения они обвели рамкой каждую черепаху, чтобы модель научилась, где появляются черепахи и как они выглядят. Итоговый набор данных был разделён на обучающую, валидационную и тестовую части и включал разнообразие освещения, фонов и ракурсов, чтобы обеспечить устойчивость модели к условиям реального мира.
Поиск лучшего способа обучения модели
Команда использовала популярную архитектуру для обнаружения объектов под названием YOLO11, выбрав компактную версию, балансирующую скорость и точность. Но вместо того чтобы принимать настройки обучения по умолчанию — изначально настроенные на повседневные объекты вроде машин и чашек — они задали простой вопрос: можно ли улучшить результаты для черепах? Сначала они сравнили шесть разных «оптимизаторов» — алгоритмов, которые корректируют внутренние веса модели в процессе обучения. Два из них показали низкую производительность или нестабильность, тогда как классический метод стохастического градиентного спуска (SGD) дал самые надёжные улучшения и наивысшие показатели на отложенном тестовом наборе.
После выбора лучшего оптимизатора исследователи приступили к настройке 16 параметров обучения, или гиперпараметров. Они управляют тем, как быстро модель учится, как сильно предотвращается переобучение, и как случайно изменяются изображения в процессе аугментации, чтобы улучшить обобщение. Используя стратегию случайного поиска — протестировав 300 различных комбинаций, отобранных из разумных диапазонов — они искали конфигурацию, которая максимизировала общую точность обнаружения и классификации. Ключевые настройки заметно сместились: увеличилась важность правильной классификации вида, усилилась регуляризация для снижения переобучения, уменьшили влияние изменения яркости при аугментации, а сложную технику смешивания изображений стали использовать реже, чтобы искусственно сгенерированные изображения были ближе к реальным фотографиям.
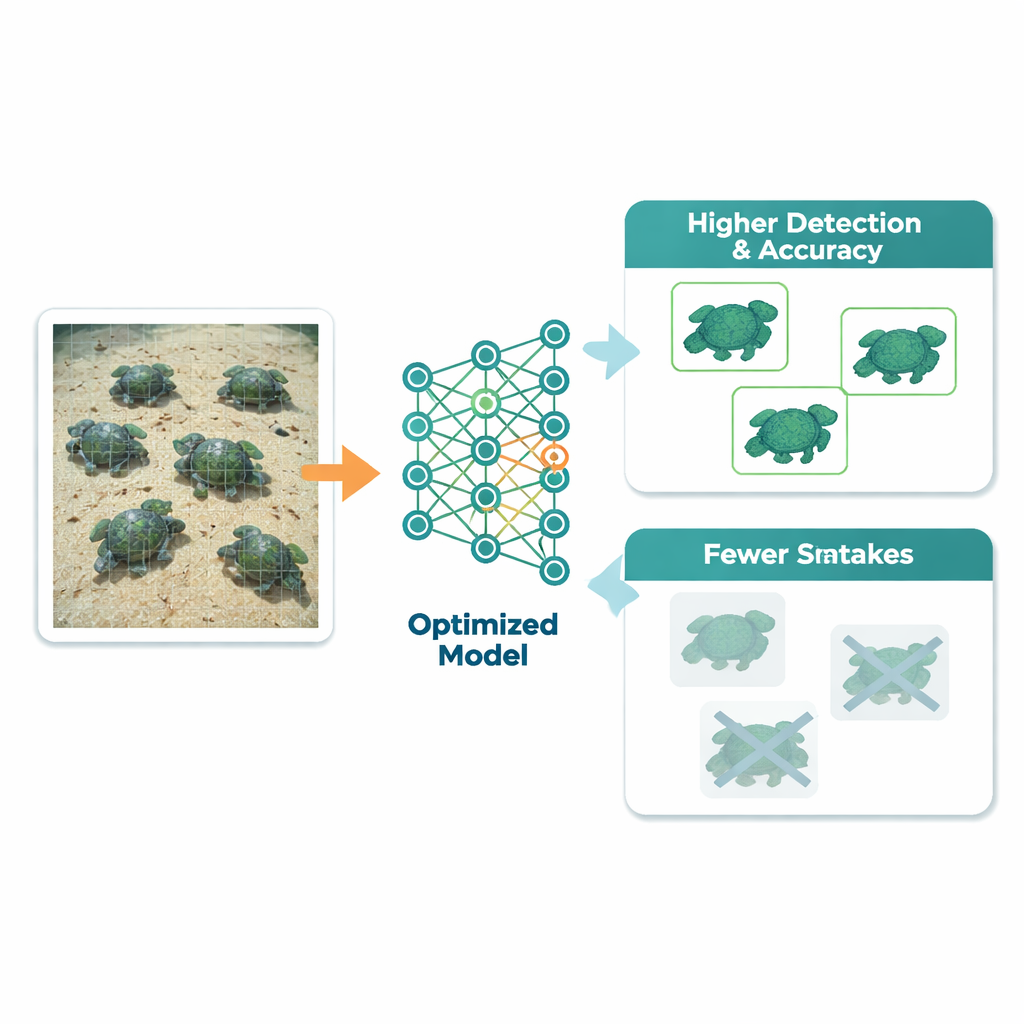
Более острый взгляд, меньше путаницы
Когда работа была завершена, оптимизированная модель явно превзошла версию, обученную со стандартными настройками. Для оценки способности системы находить и правильно маркировать черепахи исследование использовало метрику mean average precision. При обычно используемом пороге совпадения этот показатель вырос с 0.959 до 0.973, а в более строгом диапазоне порогов он поднялся с 0.815 до 0.841. Общая точность классификации по видам увеличилась с 89.9% до 92.7%. Особенно заметно сократилась путаница между похожими видами: например, одна черепаха, которую часто ошибочно принимали за другую в модели по умолчанию, после настройки стала значительно чаще определяться правильно. Эти улучшения достигнуты практически без дополнительного времени обучения и с лишь незначительным замедлением при обработке новых изображений.
Что это значит для защиты дикой природы
Для неспециалиста эти цифры означают, что компьютеры становятся заметно лучше в обнаружении нужных черепах на загромождённых, реальных снимках и в различении трудноразличимых видов. Тщательно выбирая способ обучения модели — вместо того чтобы полагаться на универсальные настройки — авторы показывают, что системы раннего обнаружения инвазивных видов можно сделать точнее без сбора новых данных или создания полностью новых алгоритмов. Развернутые на камерах‑ловушках, дронах или в потоках фотографий гражданской науки такие оптимизированные модели могут раньше оповещать менеджеров о появлении или распространении инвазивных черепах, помогая защищать местную фауну и здоровье пресноводных экосистем.
Цитирование: Baek, JW., Kim, JI., Mun, MH. et al. Hyperparameter optimization to enhance the performance of deep learning models for the early detection of invasive turtles in Korea. Sci Rep 16, 7561 (2026). https://doi.org/10.1038/s41598-026-37636-2
Ключевые слова: инвазивные черепахи, глубокое обучение, мониторинг дикой природы, оптимизация гиперпараметров, сохранение биоразнообразия