Clear Sky Science · ru
Отпечаток DNS на основе активности пользователя
Почему ваши посещения сайтов оставляют скрытый след
Каждый раз, когда вы просматриваете веб, ваш компьютер тихо обращается к особой адресной книге — Системе доменных имён (DNS), — чтобы узнать, как добраться до каждого сайта. Эти запросы не исчезают бесследно. В течение дней и недель они формируют паттерн того, какие типы сайтов вы посещаете, когда и как часто. В этой статье показано, что такие паттерны достаточно характерны, чтобы выступать в роли поведенческого отпечатка, позволяя мощным алгоритмам различать пользователей — даже если их видимый IP-адрес меняется, — что открывает возможности для безопасности, но вызывает серьёзные вопросы о приватности.
«Телефонная книга» интернета и ваши привычки
DNS существует для преобразования человекочитаемых веб-адресов, например www.google.com, в числовые IP-адреса, которые используют компьютеры для связи друг с другом. Большинство людей об этом не задумываются, но каждый поиск, видеопоток, проверка почты или обновление приложения вызывает один или несколько DNS-запросов. Эти запросы обычно обрабатываются локальными или публичными DNS-серверами и логируются простыми записями: какой IP-адрес спрашивал про какой домен и когда. Соберите достаточно таких записей — и получите детальную картину того, какими онлайн-сервисами пользуется пользователь, от рабочих инструментов и облачных хранилищ до социальных сетей и стриминговых платформ. В то время как ранние исследования использовали эти следы для обнаружения вредоносного ПО или определения типа устройств, в этом исследовании задаётся более прямой вопрос: можно ли по повторяющемуся поведению в DNS точно определить отдельных пользователей или машины?
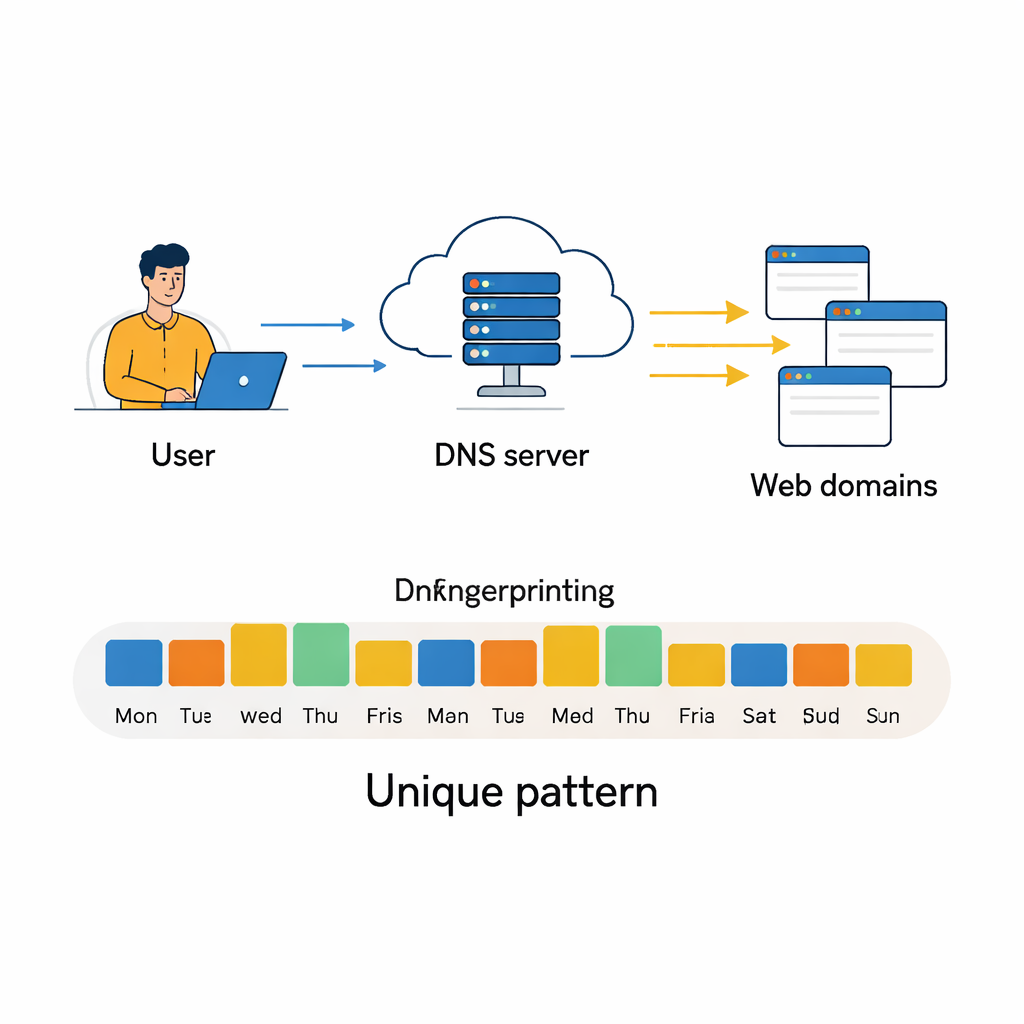
Преобразование ежедневных кликов в поведенческий отпечаток
Авторы опираются на крупный общедоступный набор данных DNS, собранный у локального интернет‑провайдера в течение трёх месяцев. Каждый день они агрегируют DNS-активность для каждого активного IP-адреса в компактное резюме: количество общих запросов, сколько разных доменов было запрошено и, что особенно важно, как эти домены распределяются по 75 категориям контента, таким как «Общий бизнес», «Программное/аппаратное обеспечение» или «Социальные сети». Оставляют только те IP-адреса, которые появляются минимум в 80 процентах дней, чтобы обеспечить достаточную историю для каждого пользователя, и тщательно удаляют избыточные или почти пустые признаки. Они также применяют статистические методы для обнаружения сильнокоррелированных полей, фильтруют экстремальные выбросы по объёму запросов и затем сжимают данные с помощью анализа главных компонент, чтобы сохранить большую часть полезной вариативности в гораздо меньшем числе измерений. Визуализируя очищенные данные с помощью метода t‑SNE, они обнаруживают, что многие IP-адреса образуют плотные, чётко разделённые кластеры — ранний признак того, что автоматическая классификация может быть осуществима.
Проверка моделей машинного обучения
Имея в распоряжении обработанный набор данных, команда рассматривает идентификацию пользователя как масштабную задачу классификации: по одному дню статистики DNS определить, какому из 1 727 IP-адресов он принадлежит. Они сравнивают ряд моделей, от классических методов, таких как наивный байесовский классификатор и случайный лес, до более продвинутых инструментов, таких как XGBoost и глубокие нейронные сети. Каждая модель обучается и валидируется на разных версиях данных (сырые, перерасшкаленные, стандартизированные или с пониженной размерностью) и оценивается по тому, как часто она правильно присваивает класс, а также по метрикам точности и полноты. Традиционные модели показывают разумные результаты — случайный лес достигает примерно 73 процентов точности, XGBoost превышает 81 процент и правильно различает более 99 процентов всех классов. Но выдающиеся результаты демонстрируют нейронные сети, в частности собственная сверточная нейронная сеть (CNN), которая рассматривает вектор признаков как одномерное «изображение» повседневного поведения.
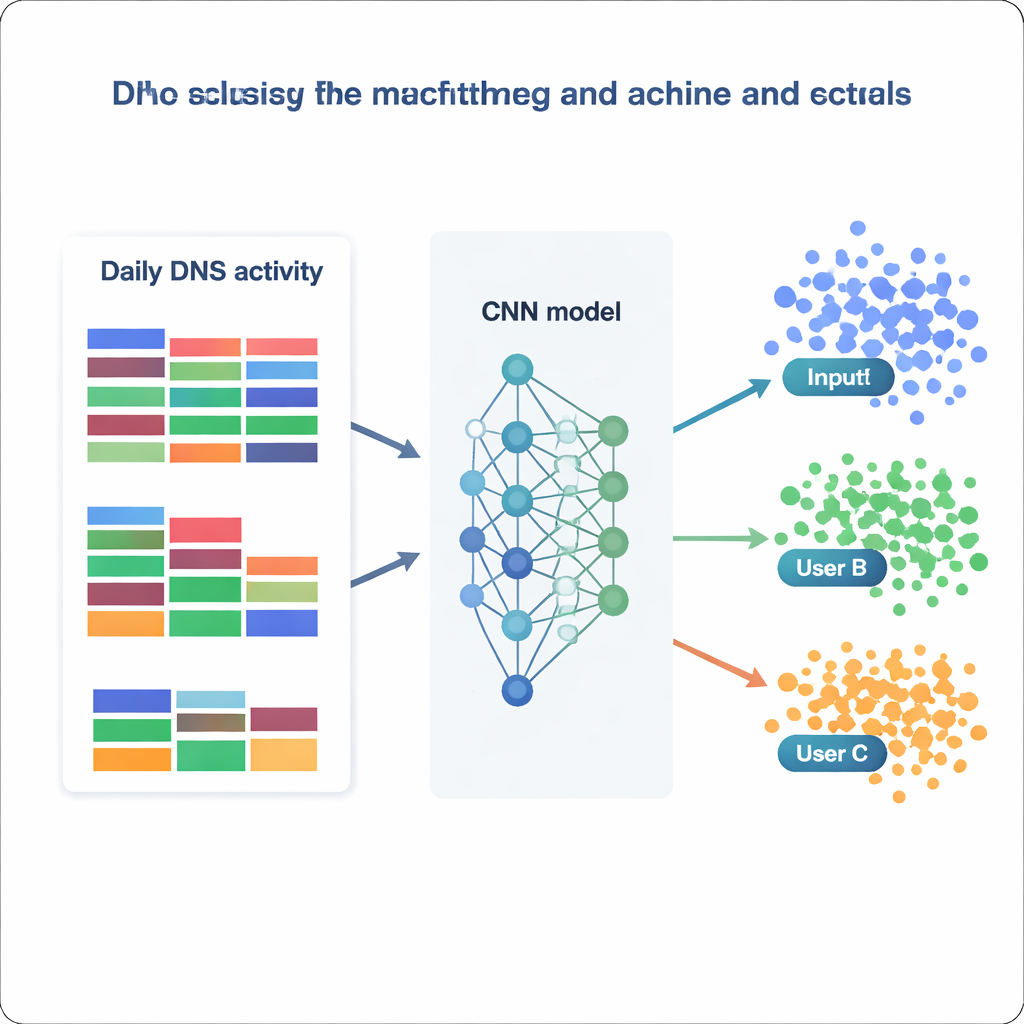
Насколько хорошо модель может знать, «кто» вы?
Лучшая CNN, обученная на нормализованных данных, правильно идентифицирует исходный IP почти в 87 процентах отложенных дней и успешно предсказывает 1 694 из 1 727 различных IP-адресов. В практическом смысле это означает, что большинство пользователей — или небольшие группы, скрывающиеся за общим IP — демонстрируют стабильные, узнаваемые паттерны DNS с течением времени. Анализируя признаки, на которые модели опираются сильнее всего, авторы выявляют две взаимодополняющие стратегии. Некоторые модели сильно зависят от очень распространённых категорий, таких как общий бизнес или сервисы ПО, фиксируя широкие привычки. Другие, как XGBoost, получают дополнительную силу за счёт редких, но информативных категорий, связанных с безопасностью, политикой или нишевыми интересами. В совокупности эти результаты показывают, что даже простая агрегированная статистика — без просмотра полного списка доменных имён — может содержать достаточно структурированной информации, чтобы с поразительной надёжностью повторно идентифицировать пользователей.
Обещания, ограничения и ставки для приватности
Для правоохранительных органов и сетевых защитников DNS‑отпечатки могут стать ценным инструментом для поиска рецидивистов, обнаружения скомпрометированных машин или выявления ботнетов, которые используют смену IP-адресов для обхода блокировок. Вместе с тем исследование подчёркивает явные ограничения: DNS‑отпечатки наиболее стабильны, когда публичный IP привязан к одному пользователю, что реалистичнее в современных IPv6‑сетях, чем в сегодняшнем IPv4, где многие пользователи делят один адрес через NAT. Частая смена DNS‑серверов или использование публичного Wi‑Fi также ослабляет сигнал. И самое важное — работа подчёркивает риск для приватности, который сложно заметить обычному пользователю. Поскольку логирование DNS во многом невидимо и пассивно, поведенческое отслеживание может происходить без установки cookies или навязчивых скриптов. Авторы публикуют свой набор данных и модели открыто, аргументируя, что прозрачные исследования необходимы, чтобы общество могло взвесить выгоды безопасности от фингерпринтинга на основе DNS и его потенциал для скрытого наблюдения, а также решить, какие защиты и политики должны регулировать эту мощную новую форму онлайн‑идентификации.
Цитирование: Morozovič, D., Konopa, M. & Fesl, J. DNS fingerprint based on user activity. Sci Rep 16, 7314 (2026). https://doi.org/10.1038/s41598-026-37631-7
Ключевые слова: DNS-фингерпринтинг, отслеживание пользователей, интернет-конфиденциальность, сетевая безопасность, машинное обучение