Clear Sky Science · ru
Суперразрешение лиц в реальных условиях на основе генеративных состязательных и сетей выравнивания лиц
Более чёткие лица из размытых фотографий
Каждый, кто пытался увеличить лицо на старой охранной записи или маленьком фото из социальных сетей, знает разочарование: чем больше увеличиваешь, тем больше лицо превращается в пиксельную кашу. В этой статье предложен новый подход на основе искусственного интеллекта, который преобразует такие низкокачественные реальные снимки лиц в гораздо более чёткие изображения, лучше сохраняя личность и выражение человека. Это имеет очевидные последствия для систем видеонаблюдения, фото-криминалистики и даже повседневных приложений для улучшения фотографий.
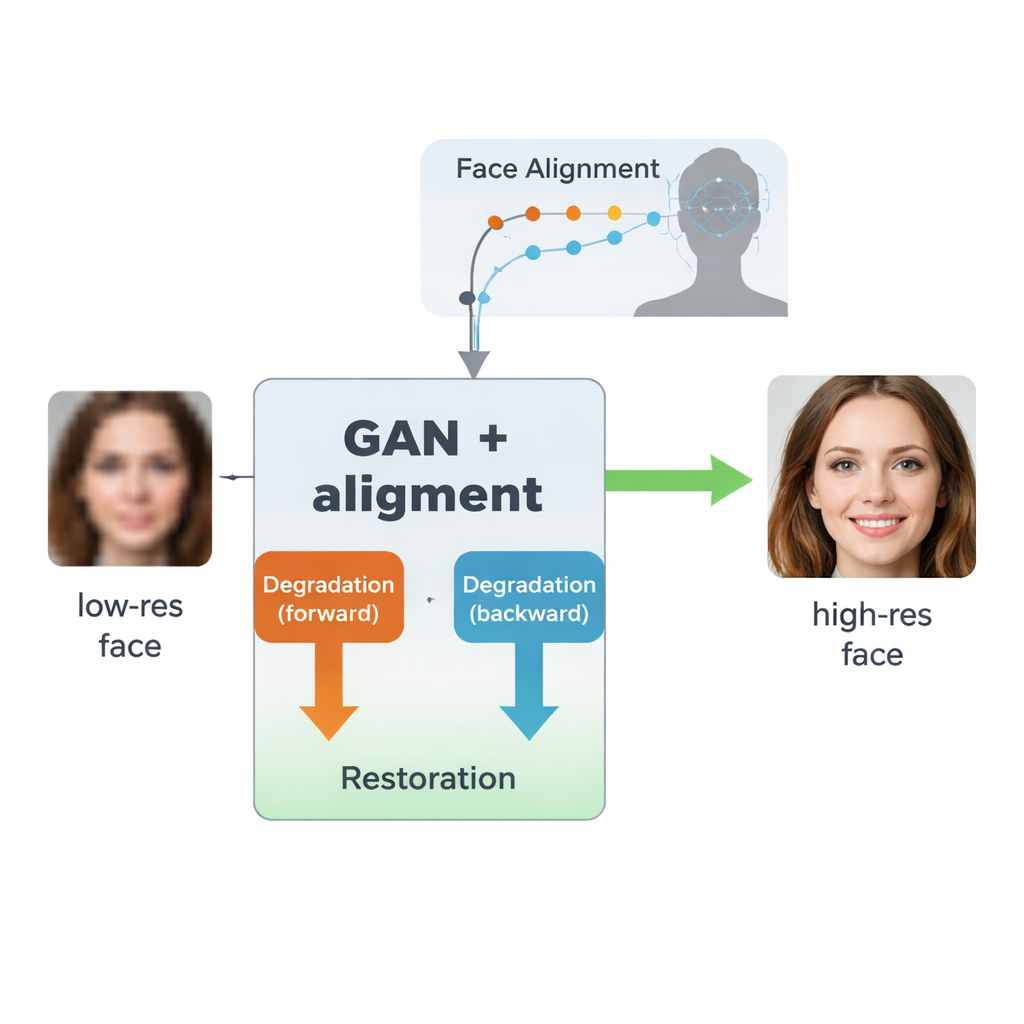
Почему так трудно восстанавливать размытые лица
Сделать маленькое размытое изображение лица резким — это не просто «добавить пиксели». Традиционные методы опирались на вручную составленные правила или простые шаблоны, а более свежие методы глубокого обучения часто обучаются на искусственно ухудшённых изображениях: берут чистое высокоразрешающее лицо, размазывают и сжимают его, а затем учат сеть обращать этот процесс. Проблема в том, что реальные изображения — например с камер наблюдения или сжатого видео — портятся хаотично и непредсказуемо. Размытие, шум и артефакты сжатия редко совпадают с аккуратными синтетическими примерами из обучения, поэтому модели, которые хорошо выглядят в лаборатории, часто проваливаются на реальных кадрах. Хуже того, они могут выдавать правдоподобные лица, которые уже не похожи на исходного человека.
Двунаправленная обучающая петля для изображений из реального мира
Авторы опираются на класс ИИ под названием генеративные состязательные сети (GAN), которые учатся создавать реалистичные изображения, противопоставляя друг другу две нейросети: генератор, создающий изображения, и дискриминатор, оценивающий их «реальность». Их архитектура, вдохновлённая более ранней моделью SCGAN, использует «полуциклическую» структуру с двумя дополняющими петлями. В прямой петле реальные высокоразрешающие лица намеренно ухудшают в одном звене, чтобы получить синтетические низкоразрешающие версии, которые затем восстанавливаются общим звеном восстановления. В обратной петле по-настоящему низкокачественные реальные лица усиливаются тем же звеном восстановления, а затем снова ухудшаются другим звеном, чтобы походить на реальные низкоразрешающие изображения. Заставляя согласовываться оба направления — ухудшить затем восстановить или восстановить затем ухудшить — система изучает реалистичную модель того, как лица портятся на практике, и как обратить этот процесс, не требуя идеально соответствующих пар низко- и высококачественных реальных изображений.
Обучение сети тому, как действительно выглядит лицо
Ключевое новшество этой работы — обучать систему не только делать изображение более резким, но и уважать внутреннюю структуру человеческого лица. Для этого авторы интегрируют отдельную сеть выравнивания лиц, изначально разработанную для определения ключевых точек, таких как уголки глаз, кончик носа и контур рта. Эта сеть выравнивания предсказывает «тепловые карты», показывающие, где должна располагаться каждая ключевая точка. Во время обучения модель сравнивает тепловые карты восстановленного изображения с тепловыми картами реального высокоразрешающего изображения того же человека и штрафует несоответствия. Важно, что используется заранее обученная модель выравнивания и не требуется ручная разметка ключевых точек для каждого изображения в обучающем наборе. Результат — своего рода геометрическое руководство: сеть усиления побуждается размещать глаза, нос и рот в правильных позициях и формах, а не просто закрашивать размытие общими текстурами, похожими на лицо.
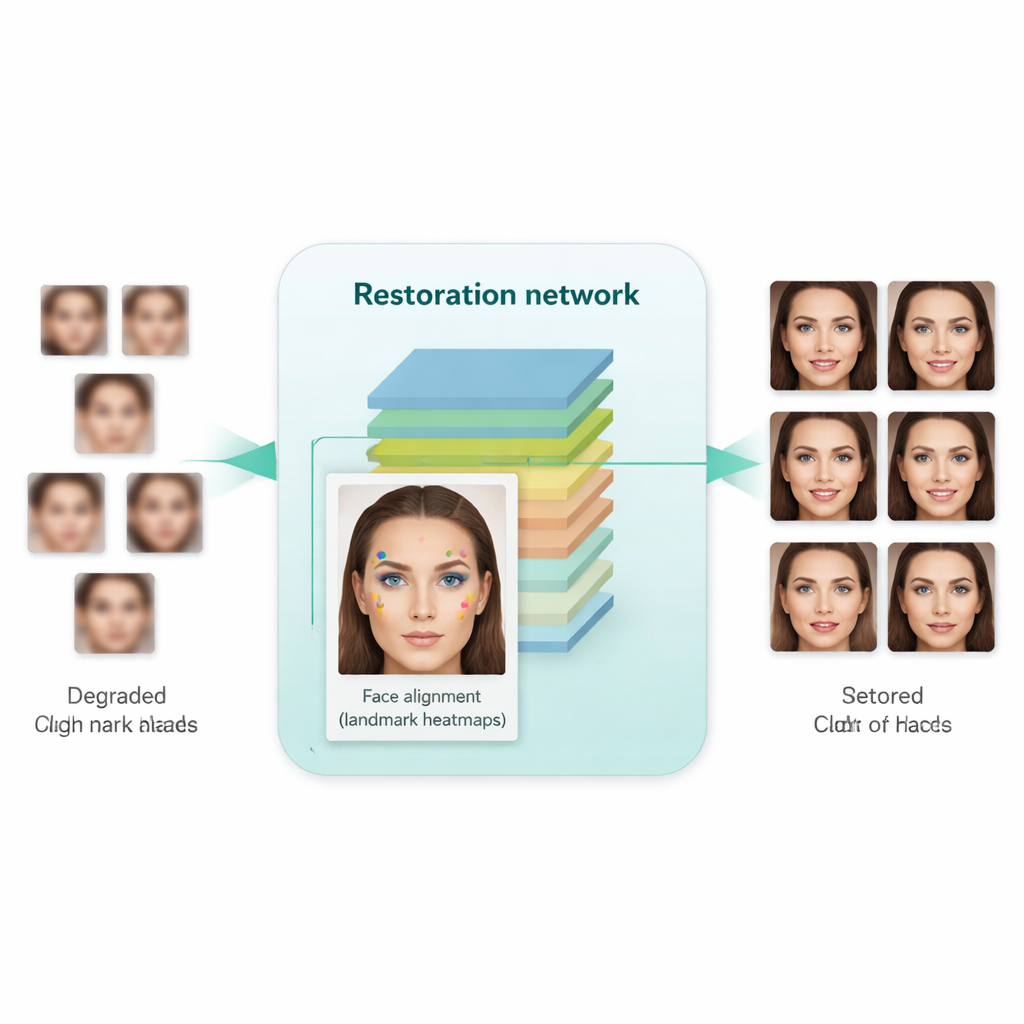
Насколько это эффективно на практике?
Исследователи обучили свою систему на большой коллекции качественных лиц и на отдельном наборе действительно низкокачественных лиц из реальных датасетов. Затем они протестировали её как на синтетических бенчмарках (где доступны чистые эталоны), так и на реальных изображениях (где можно оценивать только визуальную реалистичность и статистические показатели). По сравнению с более ранними методами — включая такие известные инструменты, как Real-ESRGAN, GFPGAN и исходный SCGAN — новый подход дал изображения, которые не только выглядели более естественно и менее искажёнными, но и обеспечивали лучшее качество в практических задачах. Когда улучшенные изображения подавались в стандартные детекторы лиц и популярную модель распознавания лиц (FaceNet), точность обнаружения и верификации заметно повышалась, что указывает на лучшее сохранение признаков личности. При этом автоматические метрики качества также показали, что сгенерированные лица ближе по распределению к реальным высокоразрешающим фотографиям.
Что это значит для повседневного использования
Проще говоря, эта работа демонстрирует, что можно получить более чёткие и надёжные лица из плохих изображений, сочетая две идеи: построить реалистичную модель того, как изображения портятся в реальном мире, и использовать информацию о ключевых точках лица, чтобы сохранить его структуру. Вместо простого «угадывания» красивого лица система направляется в реконструкцию правильного человека с более чёткими глазами, ртом и общей формой. Это делает метод особенно перспективным для приложений в безопасности, криминалистике и реставрации архивов, где важны и визуальная ясность, и корректная идентичность, а оригинальные высококачественные версии изображений редко доступны.
Цитирование: Fathy, H., Faheem, M.T. & Elbasiony, R. Real-world face super-resolution based on generative adversarial and face alignment networks. Sci Rep 16, 7492 (2026). https://doi.org/10.1038/s41598-026-37573-0
Ключевые слова: суперразрешение лиц, генеративные состязательные сети, выравнивание лиц, распознавание лиц, восстановление изображений