Clear Sky Science · ru
Конвейер обработки изображений для AI-управляемой характеристики мегабиблиотеки наночастиц
Почему крошечным частицам нужна помощь больших данных
Современная материаловедческая наука все больше опирается на изготовление и тестирование огромного числа крошечных частиц в поисках лучших катализаторов, батарей и других передовых материалов. Новые методы позволяют вырастить миллионы различных наночастиц на одном чипе, но проверка качества каждой из них под микроскопом порождает куда больше изображений, чем может разумно просмотреть человек. В этой статье описано, как исследователи построили автоматизированный конвейер обработки изображений и AI, который быстро сортирует «годные» и «негодные» изображения наночастиц, снижая вычислительные расходы и ускоряя эксперименты при высокой надежности решений.
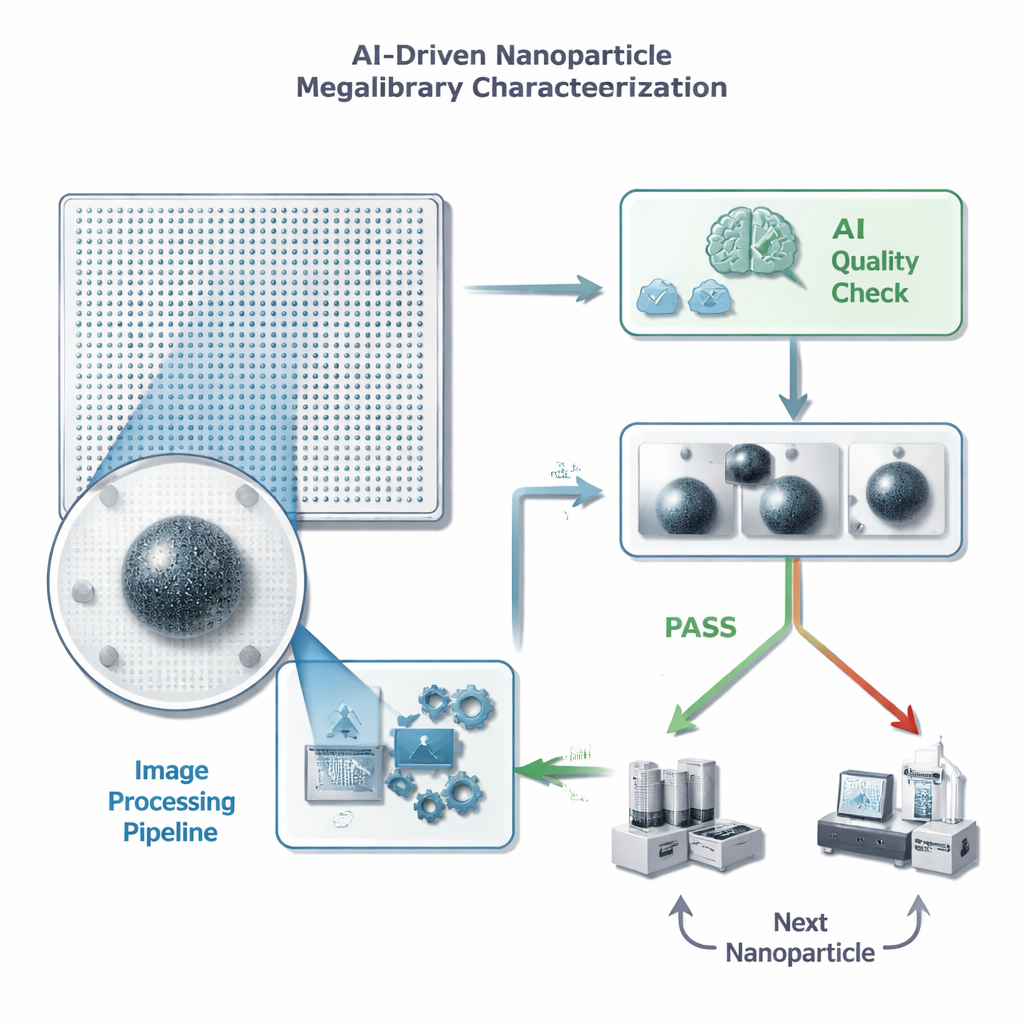
От бесконечных изображений к быстрым решениям
Каждая наночастица на чипе «мегабиблиотеки» занимает известную позицию и может быть снята электронным микроскопом. Прежде чем ученые потратят время и дорогие последующие измерения на отдельную частицу, им нужен быстрый контроль качества: есть ли в кадре ровно одна хорошо сфокусированная частица без отвлекающих мусора или артефактов? Авторы формулируют это как простую задачу «пропустить/отклонить» для модели машинного обучения, но с жестким ограничением на время обработки одного изображения — менее полусекунды, потому что на одном чипе может быть миллионы частиц. Они также подчеркивают, что ложноположительные срабатывания особенно вредны: если ИИ по ошибке пропустит «плохое» изображение, это потратит время и место для хранения на бесполезные детальные измерения, тогда как редкое пропускание хорошей частицы в целом наносит меньший ущерб прогрессу.
Очистка изображения до взгляда ИИ
Вместо того чтобы подавать сырые, шумные микроскопические снимки напрямую в большую сложную нейросеть, команда разработала кастомный конвейер обработки изображений, который сначала «очищает» кадры. Конвейер удаляет фоновой шум, усиливает контуры, плотно кадрирует частицу и затем уменьшает размер изображения. Критично, что эта предобработка делает слабые признаки более заметными и имитирует вид при более высоком увеличении без повторной съемки образца. В результате получается компактная, с повышенной контрастностью картинка, которую можно подать в относительно простую нейросеть, сокращая время обучения и объем хранимых данных при сохранении важных для оценки качества деталей.
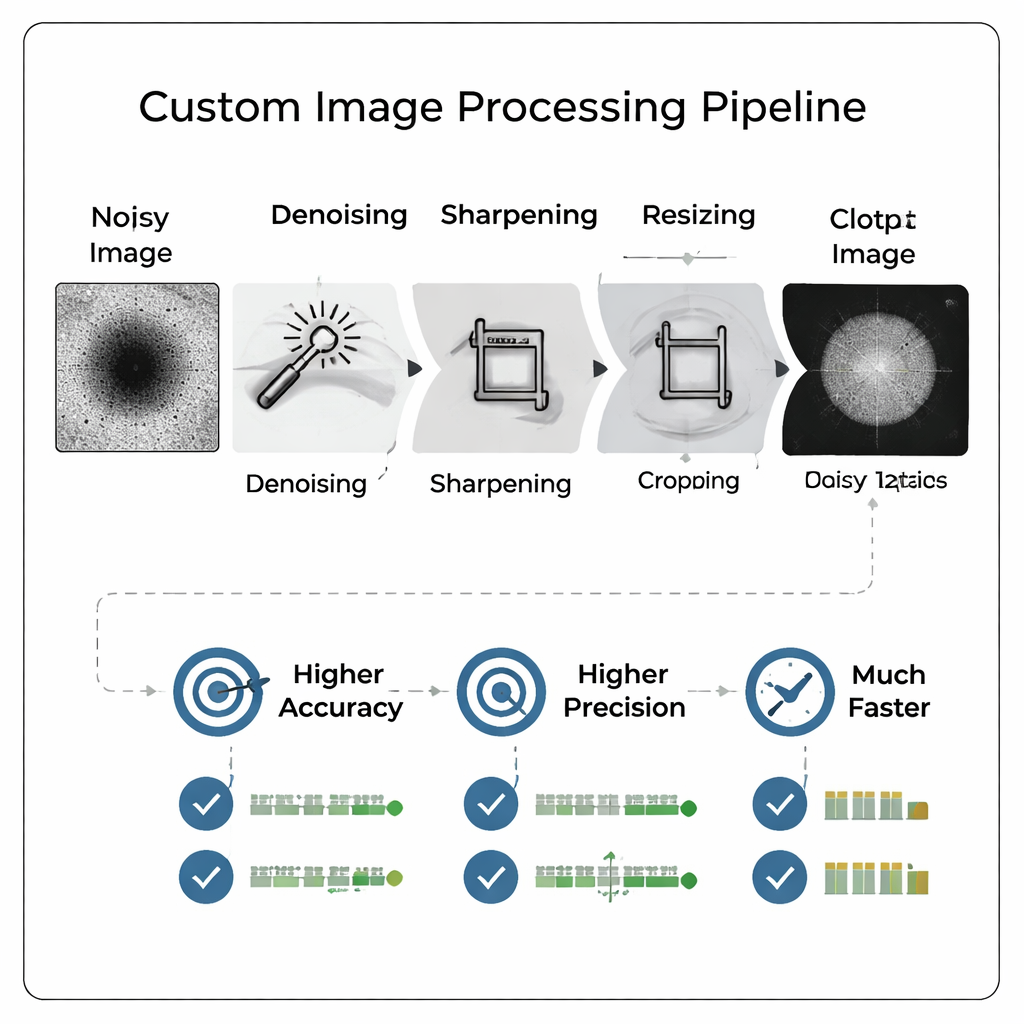
Умнее обработанные изображения лучше больших моделей
Исследователи тщательно сравнили многочисленные варианты конвейера и разрешения, в конечном счете обучив 800 разных моделей, чтобы выяснить, как размер изображения и обработка влияют на качество. Они обнаружили, что аккуратно обработанные изображения при умеренных разрешениях (например, 128×128 пикселей) позволяют небольшой свёрточной нейросети превзойти прежнюю, гораздо большую модель, найденную с помощью автоматического поиска архитектур и обученную на полных 512×512 изображениях. Точность выросла более чем на 13 процентных пунктов, а полнота — способность правильно обнаруживать хорошие частицы — увеличилась более чем на 18 процентных пунктов. Точность положительных предсказаний, ключевая метрика для избегания напрасных затрат на плохие частицы, достигла примерно 96 процентов, и комбинированная метрика, предпочитаемая авторами, тоже улучшилась.
Больше возможностей при гораздо меньшем объеме данных
Одним из самых поразительных результатов является то, что предобработка важнее, чем исходный размер изображения. Когда команда сравнила модели, обученные на простых «только уменьшенных» изображениях, с теми, которые использовали полный кастомный конвейер, обработанные изображения последовательно побеждали — даже при сильном уменьшении до очень маленьких размеров, например 16×16 пикселей. Фактически лучшая модель на обработанных 16×16 изображениях обошла лучшую модель на необработанных 128×128 по почти всем метрикам. Конвейер также давал наибольшую пользу при более низких увеличениях микроскопа, где изображения обычно сложнее для интерпретации. Поскольку снимки при низком увеличении получают быстрее, это означает, что лаборатории могут сканировать чипы быстрее, не жертвуя качеством принятия решений.
Более быстрые решения для самообучающихся лабораторий
Комбинируя умную обработку изображений с компактной AI-моделью, авторы сократили время обучения с многих часов на суперкомпьютере до менее чем минуты на одном графическом процессоре. После обучения система может обработать и классифицировать новое изображение примерно за 75 миллисекунд, что значительно ниже целевого порога в 500 миллисекунд и намного быстрее, чем человек. Практически это преобразуется в быстрое и надежное скрининговое исследование мегабиблиотек наночастиц, помогая исследователям направлять дорогостоящие приборы на наиболее перспективные образцы. По мере того как лаборатории движутся в сторону более автоматизированных «самоуправляемых» систем открытий, подходы типа «сначала очисти данные, затем примени упрощенный AI» предлагают мощный способ превратить ошеломляющие потоки изображений в пригодные для действий научные выводы.
Цитирование: Day, A.L., Wahl, C.B., dos Reis, R. et al. Image processing pipeline for AI-driven nanoparticle megalibrary characterization. Sci Rep 16, 7675 (2026). https://doi.org/10.1038/s41598-026-37566-z
Ключевые слова: наночастицы, обработка изображений, машинное обучение, открытие материалов, электронная микроскопия