Clear Sky Science · ru
Исследование модулей повышения корреляции меток в глубоком многометочном обучении, готовых к интеграции
Обучение машин работе с бесчисленными тегами
Интернет‑магазины, юридические архивы и медицинские базы данных зависят от программ, которые быстро присваивают новым документам правильные метки. Но современные системы нередко сталкиваются с десятками тысяч или даже миллионами возможных тегов — от товарных категорий до медицинских тем — в то время как каждому тексту требуется лишь небольшая их выборка. В этой статье предлагается новое дополнение, названное Сетью Усиления Корреляции Меток (LCENet), которое помогает существующим моделям глубокого обучения лучше использовать естественные совместные появления меток в реальных данных, что приводит к более точной и быстрой маркировке текстов.
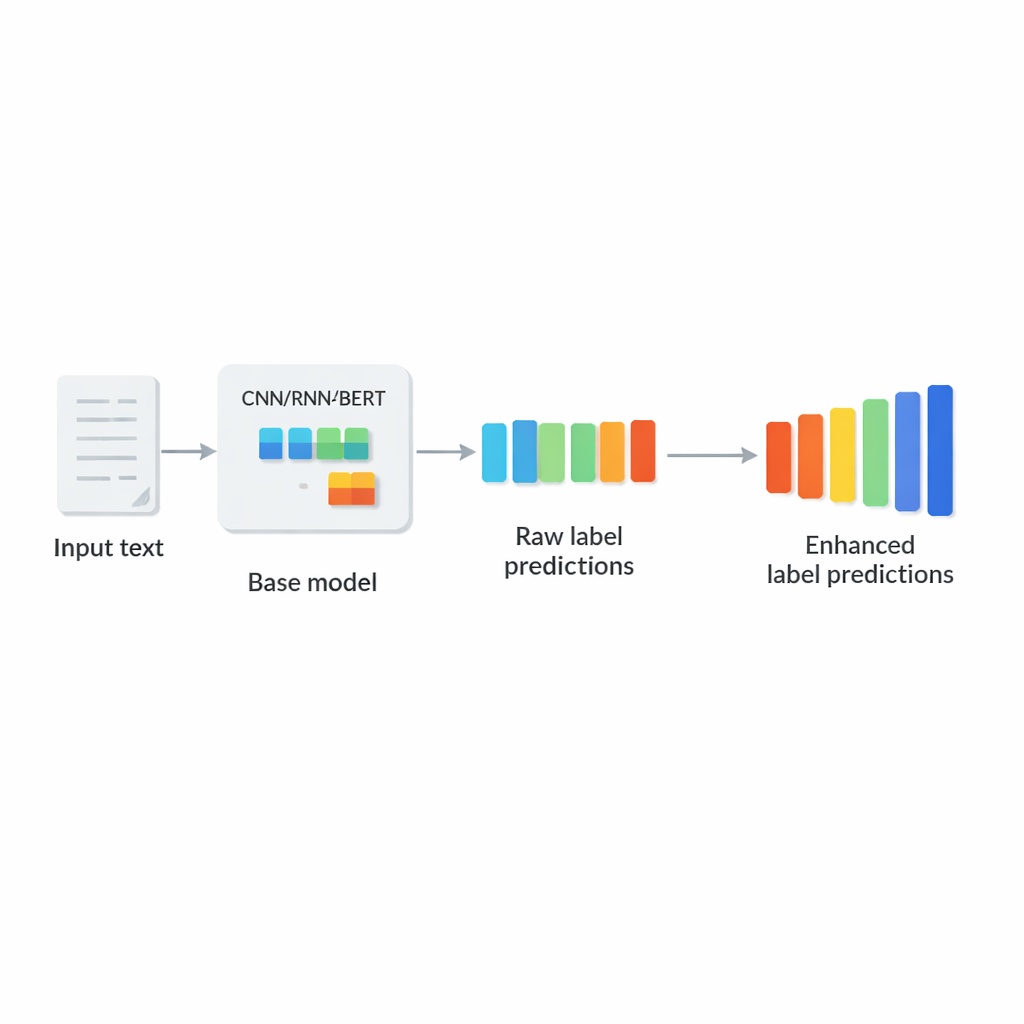
Почему маркировка в веб‑масштабе так сложна
Многие прикладные задачи относятся к тому, что исследователи называют экстремальной многометочной классификацией текста: по короткому описанию или длинному документу система должна выбрать небольшое подмножество релевантных меток из гигантского каталога. Примеры включают присвоение категорий товарам на торговой площадке, индексирование биомедицинских статей терминами MeSH, сопоставление рекламных материалов со страницами веба или отнесение юридических текстов к детализированным кодам права. В этих задачах есть три общие сложности: список меток чрезвычайно велик, большинство меток встречается редко, и каждый текст использует лишь несколько меток. Традиционные методы либо разбивают задачу на множество мелких классификаторов, либо сжимают метки в векторы меньшей размерности, но часто опираются на простые подсчёты слов и не могут полноценно уловить смысл или взаимосвязи между метками.
Что упускают стандартные глубокие модели
Современные подходы глубокого обучения — свёрточные сети, рекуррентные сети и модели на базе Transformer, такие как BERT — значительно улучшили понимание текста, обучаясь насыщенным семантическим представлениям. Однако почти все они делают критическое упрощение на заключительном этапе: после того как текст закодирован в вектор, они предсказывают каждую метку независимо друг от друга. На практике же метки сильно взаимодействуют. Медицинская статья с меткой «диабет» с большей вероятностью также связана с «инсулинорезистентностью», а устройство с меткой «смартфон» обычно связано с «электроникой» и «средствами связи». Игнорирование этих закономерностей не позволяет моделям использовать уверенные метки для поддержки менее уверенных и может приводить к комбинациям, которые не имеют смысла вместе.
Плагин, изучающий отношения между метками
Авторы предлагают LCENet как лёгкий плагин, который вставляется после любой существующей глубокой текстовой классификаторной модели. Вместо того чтобы менять то, как базовая модель воспринимает текст, LCENet принимает исходные оценки по меткам и пропускает их через компактную «бутылочную» структуру, вынуждающую систему обнаруживать низкоразмерное представление, в котором связанные метки сгруппированы вместе. Нелинейные функции активации позволяют модулю захватывать сложные, высшего порядка ассоциации, а не только простые попарные связи. Резидентное (skip) соединение передаёт оригинальные оценки напрямую в выход вместе с откорректированными, что стабилизирует обучение и гарантирует, что дополнение не ухудшит работу модели. Ключевое преимущество — LCENet сокращает число дополнительных параметров с квадратично растущего от числа меток до гораздо более управляемого линейного роста, поэтому он остаётся применимым даже при сотнях тысяч меток.
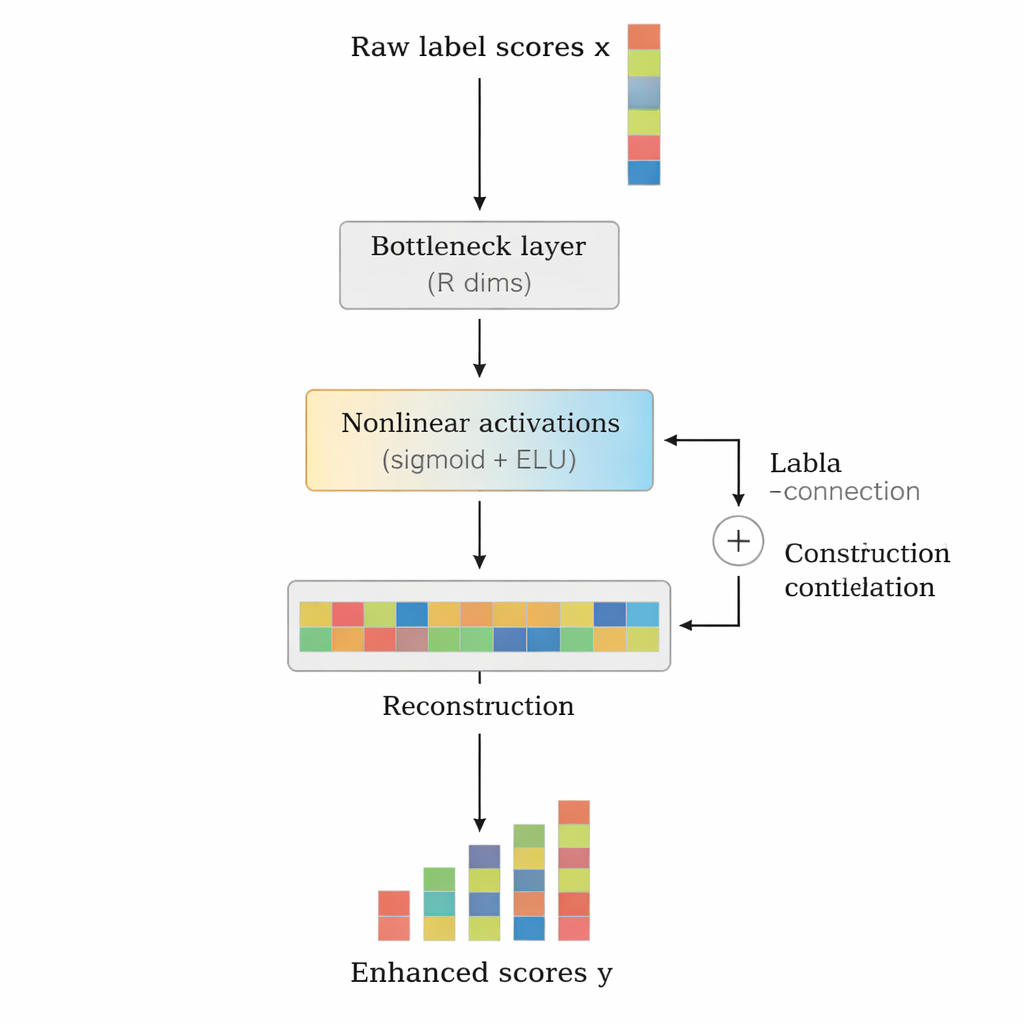
Доказательство пользы для разных моделей и наборов данных
Чтобы проверить обобщаемость LCENet, авторы прикрепили его к четырём очень разным глубоким моделям, включая архитектуры на базе CNN и BERT, а также системам, разработанным специально для биомедицины и экстремальных задач маркировки. Они оценили эти комбинации на трёх публичных бенчмарках: европейском юридическом корпусе (EUR-Lex), наборе данных товаров Amazon (AmazonCat-13K) и огромной коллекции Википедии с более чем полумиллионом меток (Wiki-500K). Во всех моделях, на всех наборах данных и по шести метрикам, ориентированным на ранжирование, LCENet последовательно улучшал качество, иногда повышая точность top‑1 более чем на пять процентных пунктов на крупнейшем наборе. Кривые обучения дополнительно показали, что LCENet часто сокращает число шагов обучения, необходимых для достижения заданной точности, почти вдвое, поскольку добавленная структура корреляции меток с самого начала даёт более чёткие сигналы для обучения.
Почему это важно для повседневных систем
Для практиков, которые уже используют глубокие модели для маркировки текстов, LCENet предлагает практичный способ повысить точность и скорость обучения без переработки систем или сбора новых видов аннотаций. Он рассматривает пространство меток как источник знаний, изучая, какие теги обычно идут вместе или исключают друг друга, и соответственно корректирует предсказания. Несмотря на то что метод разработан для текста, та же идея усиления предсказаний за счёт выученных отношений между выходами может быть применена к изображениям, мультимодальным данным и другим задачам структурированного предсказания. Проще говоря, LCENet помогает машинам «помнить», как связаны метки, чтобы они предсказывали не как изолированные флажки, а как осмысленный эксперт, понимающий, как понятия сочетаются.
Цитирование: Zhang, J., Yuan, C. & Li, X. Research on plug-and-play correlation enhancement modules in deep multi-label learning. Sci Rep 16, 6788 (2026). https://doi.org/10.1038/s41598-026-37565-0
Ключевые слова: экстремальная многометочная классификация текста, корреляция меток, глубокое обучение, классификация текста, нейронные сети