Clear Sky Science · ru
DMSCA: динамичное многомасштабное канално-пространственное внимание для улучшенного представления признаков в сверточных нейронных сетях
Обучая компьютеры внимательнее смотреть
Современные системы распознавания изображений умеют находить кошек, дорожные знаки и опухоли на снимках — но они не всегда знают, на что внутри изображения стоит обращать внимание. В этой статье предложен новый способ помочь таким системам фокусироваться на наиболее важных фрагментах изображения, что повышает точность и делает их надёжнее в условиях реального мира. Метод под названием Dynamic Multi-Scale Channel-Spatial Attention (DMSCA) встраивается в существующие сверточные нейронные сети и помогает им более осмысленно учитывать как «что» на изображении, так и «где» это находится.
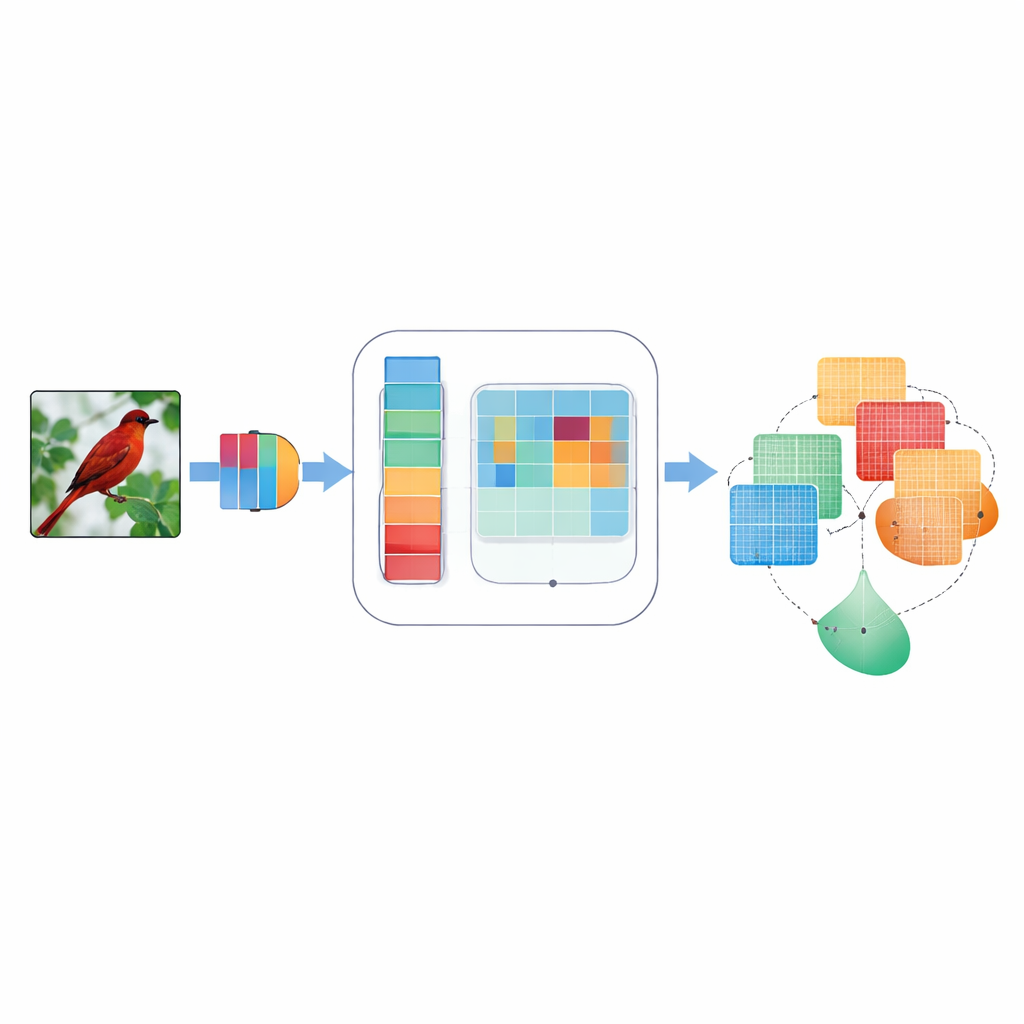
Почему фокус важен для машинного зрения
Сверточные нейронные сети, являющиеся базой многих приложений зрения, обычно рассматривают все внутренние сигналы как равнозначные. Это означает, что слабая кромка крыла птицы и кусок неба могут получить примерно одинаковое внимание, хотя для идентификации вида полезна прежде всего кромка. Ранние подходы «внимания» пытались это исправить — они взвешивали одни внутренние сигналы выше других, либо по каналам, похожим на цветовые, либо по двумерной структуре изображения. Но такие методы часто опирались на фиксированные, вручную заданные правила, смотрели лишь на один масштаб деталей за раз или объединяли информацию жёстким способом, неадаптирующимся к разным изображениям. В результате они иногда упускали тонкие детали, игнорировали направленности вроде «горизонталь vs вертикаль» или испытывали трудности при шумных и размытых снимках.
Более умный модуль внимания
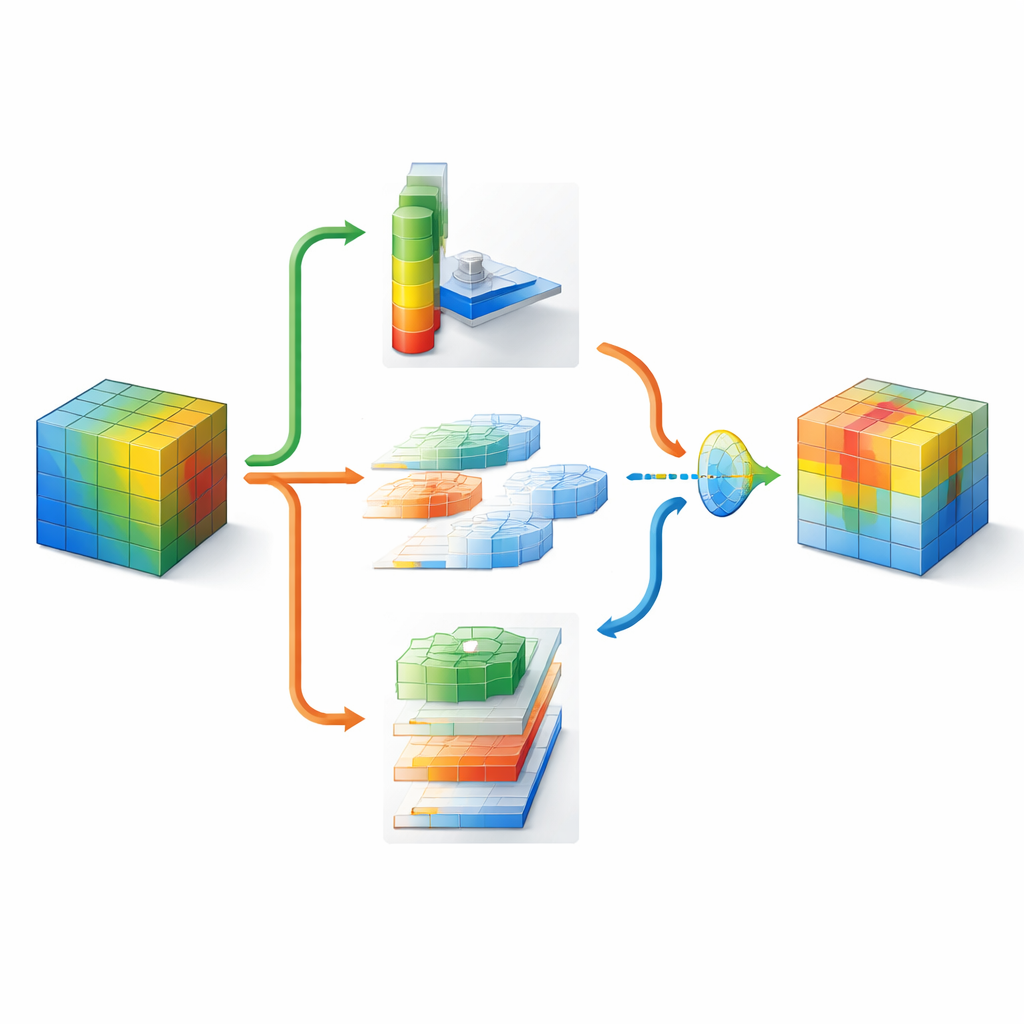
DMSCA разработана как небольшой подключаемый модуль, который можно вставить в известные нейросети, такие как ResNet, не меняя их общей архитектуры. Внутри он координирует шесть тесно связанных частей, работающих совместно, а не по отдельности. Одна часть суммирует информацию по всему изображению, чтобы захватить глобальный контекст, другая определяет, насколько важен каждый внутренний канал, используя регулируемую «температуру», которая делает решения более резкими или более мягкими по мере необходимости. С пространственной стороны DMSCA применяет одновременно несколько размеров окон, чтобы улавливать как мелкие текстуры, так и крупные формы, и явно учитывает горизонтальные и вертикальные направления, чтобы длинные кромки или полосы не терялись. Наконец, вместо простого суммирования этих сигналов модуль обучается для каждого пикселя решать, сколько доверять информации «что» из каналов и «где» из пространственной части.
Рассмотрение изображений на многих масштабах и в разных направлениях
Чтобы понять, куда смотреть на изображении, DMSCA сначала сжимает множество внутренних каналов в компактную двухслойную карту, выделяющую и фоновые тенденции, и выраженные признаки. Затем эту карту пропускают через несколько параллельных фильтров разных размеров. Малые фильтры улавливают тонкие детали, такие как мех или перья, а большие — формы целых голов или тел. Параллельно направленный блок сканирует по строкам и столбцам отдельно, сохраняя точную позицию важных структур. Эти горизонтальные и вертикальные представления затем взаимодействуют, так что сильный вертикальный сигнал, например, может усилить соответствующие горизонтальные позиции. В результате получается насыщенная карта внимания, которая сообщает сети не только о значимости элементов, но и о том, где они находятся и в каком они масштабе.
Позволяя сети самой решать, что важнее
Поскольку разные участки изображения требуют разных стратегий, DMSCA не навязывает фиксированную схему комбинирования каналовой и пространственной информации. Вместо этого она строит крошечный «шлюз», который исследует оба типа сигналов и принимает решение — независимо для каждого пикселя — какую долю веса дать каждому виду информации. В захламлённом фоне система может больше опираться на выделяющиеся каналы, тогда как у чётких границ объектов она может акцентировать пространственные подсказки. Финальная стадия адаптивной активации действует как обучаемый регулятор яркости — усиливая действительно информативные области и приглушая остаточный шум. Этот многоступенчатый процесс помогает направить внимание сети на согласованные, относящиеся к объектам регионы, что подтверждается визуальными тепловыми картами и количественными метриками совпадения выделенных областей с истинными объектами.
Более чёткое восприятие при умеренных затратах
Авторы протестировали DMSCA на ряде стандартных бенчмарков, от небольших наборов мелких изображений до крупномасштабного набора ImageNet. При добавлении к популярным моделям ResNet DMSCA стабильно повышала точность классификации — примерно на 2 процентных пункта на небольших наборах и на 1.5 процентных пункта на ImageNet — превосходя ряд существующих методов внимания. Она также делала модели более устойчивыми к типичным ухудшениям изображений, таким как шум, размытость и сильная компрессия, и улучшала результаты в смежных задачах, таких как детектирование объектов и семантическая разметка сцен. Эти улучшения достигались при лишь умеренном увеличении вычислительных и памятьных затрат. Проще говоря, DMSCA даёт сверточным сетям более гибкий и контекстно осознанный способ решать, на что смотреть и что игнорировать, приближая машинное зрение к избирательной фокусировке человеческого взгляда.
Цитирование: Zong, L., Nan, S.J., Die, Z.F. et al. DMSCA: dynamic multi-scale channel-spatial attention for enhanced feature representation in convolutional neural networks. Sci Rep 16, 8044 (2026). https://doi.org/10.1038/s41598-026-37546-3
Ключевые слова: механизмы внимания, распознавание изображений, сверточные нейронные сети, представление признаков, робастное компьютерное зрение