Clear Sky Science · ru
Улучшение кросс-модального поиска через оптимизацию графа меток и гибридные функции потерь
Более разумный поиск между изображениями и словами
Каждый день мы пролистываем океаны фотографий, видео и текста. Найти именно то, что нужно — например, все изображения, соответствующие короткой подписи — зависит от того, насколько хорошо компьютеры умеют связывать изображения с языком. В этой работе рассматривается новый способ сделать такое соответствие точнее, особенно в шумных реальных сценах, где одновременно присутствуют многие объекты и идеи. В результате получаются более «умные» поисковые инструменты, которые лучше «понимают» наш запрос, а не только то, что мы ввели.
Почему важно, что в одном кадре может быть много смыслов
Одно изображение редко показывает только один объект. Фото кита, выпрыгивающего из воды, может одновременно содержать океан, небо, волны, ветер и дикую природу. При пометке такого снимка мы часто прикрепляем несколько меток, связанных между собой тонкими отношениями. Существующие поисковые системы обычно рассматривают эти метки как несвязанные флажки. Такое упрощение отбрасывает полезные подсказки: если «кит» часто встречается вместе с «морем», то наличие одной метки повышает вероятность другой. Эта работа направлена на то, чтобы уловить скрытые связи между метками, чтобы поиск по одной идее мог находить изображения и тексты, выражающие тесно связанные понятия.

Построение сети взаимосвязанных меток
Авторы предлагают технику, называемую двухслойной сверточной графовой сетью (Two-Layer Graph Convolutional Network, L2-GCN), для моделирования связей между метками. Проще говоря, каждая метка (например, «небо» или «кит») рассматривается как узел в сети, а ребра между узлами отражают частоту совместной встречаемости меток. Метод многократно даёт каждой метке «слушать» своих соседей, смешивая информацию от связанных меток и одновременно сохраняя собственную идентичность. После этого процесса система получает более богатые описания меток, которые лучше передают структуру реальных сцен — от параллельных понятий («море» и «пляж») до более иерархичных («животное» и «кит»).
Обучение изображений и текста общему пространству
Разумеется, метки — лишь часть истории; системе также нужно учиться на самих изображениях и текстах. Фреймворк использует проверенные инструменты для преобразования сырых пикселей и слов в числовые признаки, затем проецирует оба типа данных в общее пространство, где их значения можно непосредственно сравнивать. Адверсариальная часть — отчасти вдохновлённая принципом состязательных генеративных сетей — препятствует тому, чтобы модель цеплялась за особенности только изображений или только текста. Это помогает общему пространству фокусироваться на содержании, а не на формате, так что снимок оживлённой улицы и короткая подпись к нему оказываются близки друг к другу в этой общей «карте» смыслов.
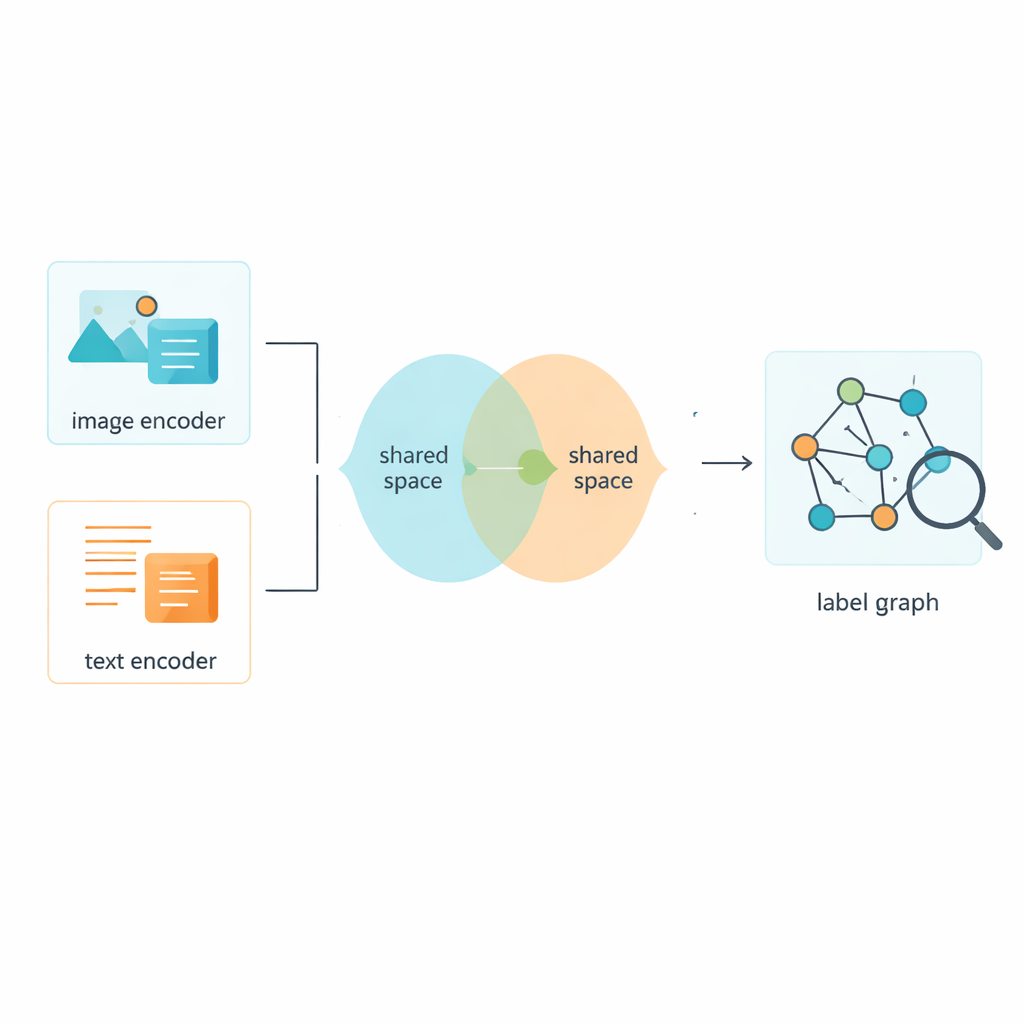
Гибридная стратегия обучения для более чётких разграничений
Обучение такой системы требует более чем одного правила оптимизации. Авторы разработали комбинированную функцию потерь, названную Circle-Soft, которая объединяет две дополняющие друг друга идеи. Одна часть поощряет примеры одной категории сжиматься в плотные кластеры, одновременно отталкивая разные категории гибким адаптивным образом. Другая часть сосредоточена на том, насколько хорошо изображения и тексты, описывающие одну и ту же сцену, выравниваются между форматами. Регулируемый вес балансирует эти две цели, чтобы модель не переобучалась ни на чёткие границы категорий, ни только на кросс-модальное выравнивание. Дополнительные классификационные и адверсариальные потери дальше подтверждают согласованность между уточнёнными метками и общими признаками изображений и текста.
Насколько это улучшает поиск?
Чтобы оценить практическую пользу идей, авторы протестировали метод на трёх популярных коллекциях реальных пар изображение–текст: MIRFlickr, NUS-WIDE и MS-COCO. Эти датасеты содержат от тысяч до сотен тысяч фотографий с сопутствующими тегами или подписями, охватывающими повседневные сцены от городских улиц до дикой природы. Во всех трёх бенчмарках новый подход последовательно превосходил широкий круг конкурентов, включая другие продвинутые системы, уже использующие графовое моделирование меток. Прирост — порядка от полупроцентного до полного процентного пункта в строгой метрике поиска — может звучать скромно, но в зрелых бенчмарках даже небольшие улучшения сигнализируют о более точном понимании содержания. На практике это означает, что при вводе короткого текстового запроса или загрузке изображения система с большей вероятностью покажет наиболее релевантные кросс-модальные совпадения в верхней части результатов.
Что это значит для обычных пользователей
Для неспециалистов ключевая мысль такова: более умная работа с метками и правилами обучения заметно улучшает то, как машины связывают изображения и слова. Подходя к меткам как к взаимосвязанной сети, а не к изолированным тегам, и аккуратно формируя то, как визуальная и текстовая информация сходится в общем пространстве, этот фреймворк делает кросс‑модальный поиск более надёжным в сложных сценах с множеством тем. Со временем подобные методы могут питать более интуитивные коллекции фотографий, медиаплатформы и интеллектуальных ассистентов, которые находят то, что мы имеем в виду, даже если наши слова не идеально соответствуют образам в голове.
Цитирование: Wang, L., Wang, C. & Peng, S. Enhancing cross-modal retrieval via label graph optimization and hybrid loss functions. Sci Rep 16, 6400 (2026). https://doi.org/10.1038/s41598-026-37525-8
Ключевые слова: поиск изображение‑текст, мультимодальный поиск, графовые нейронные сети, семантические метки, машинное обучение