Clear Sky Science · ru
Глубокая обучающая платформа на основе DNABERT для предсказания сайтов связывания факторов транскрипции
Почему важно предсказывать «переключатели» ДНК
Каждая клетка вашего тела по сути содержит одну и ту же ДНК, но клетки мозга, печени и иммунной системы ведут себя очень по-разному. Одна из причин — специальные белки, называемые факторами транскрипции, которые действуют как молекулярные переключатели, включая или выключая гены при связывании с короткими участками ДНК, известными как сайты связывания. Экспериментальное выявление всех таких участков по всему геному — медленный и дорогой процесс. В этом исследовании представлена модель искусственного интеллекта TFBS-Finder, которая способна читать сырые буквы ДНК и точнее предсказывать места связывания факторов транскрипции, что потенциально ускорит исследования регуляции генов и болезней.
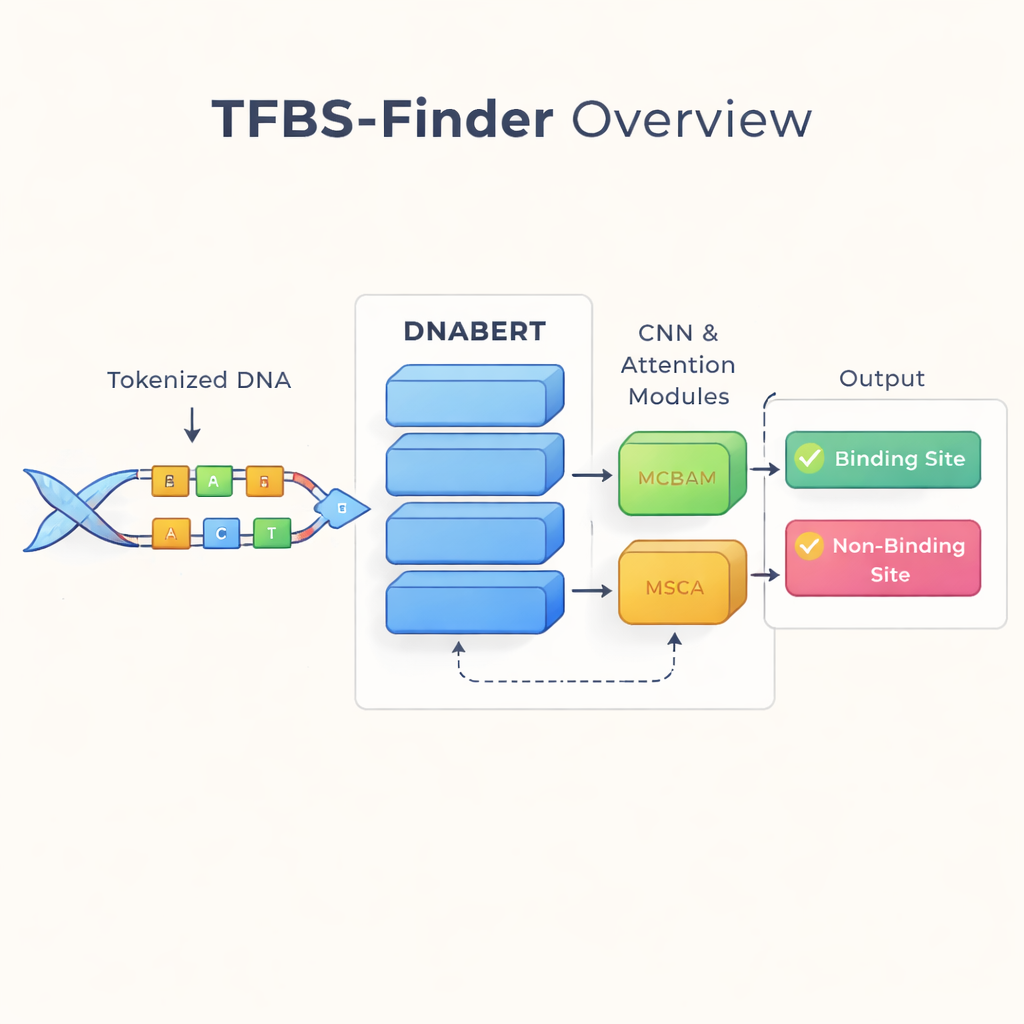
Чтение ДНК как языка
Авторы опираются на идею, которая преобразила технологии обработки языка: рассматривать ДНК как текст. Они используют DNABERT — версию языковой модели BERT, дообученную на человеческой ДНК вместо слов. DNABERT не опирается только на отдельные буквы; он разбивает ДНК на перекрывающиеся короткие «слова» из пяти букв и учится, как эти фрагменты часто сосуществуют. Это позволяет модели улавливать дальние контексты, например как шаблоны на одном конце последовательности соотносятся с шаблонами далеко от них, подобно тому, как понимают смысл предложения, а не отдельных слов.
Поиск локальных паттернов с помощью сфокусированного внимания
Хотя DNABERT хорошо улавливает глобальный контекст, связывание факторов транскрипции часто зависит от очень коротких, точных мотивов — локальных шаблонов в ДНК. Поэтому TFBS-Finder добавляет несколько дополнительных компонентов поверх DNABERT. Свёрточная нейронная сеть (CNN) просеивает встраивания последовательностей, чтобы выделить повторяющиеся локальные формы, аналогично тому, как программы для обработки изображений обнаруживают края и углы. Два модуля внимания, называемые MCBAM и MSCA, действуют как настраиваемые прожекторы, усиливая наиболее информативные признаки и подавляя шум. Вместе эти блоки уравновешивают общий контекст и детализированную информацию, чтобы решить, содержит ли сегмент ДНК истинный сайт связывания.
Доказательства того, что каждая часть важна
Чтобы проверить необходимость всех этих компонентов, команда провела обширные «абляционные» эксперименты, систематически удаляя или переставляя модули и переобучая систему на 165 эталонных наборах данных, охватывающих 29 факторов транскрипции в 32 типах клеток. По стандартным мерам качества предсказаний полная модель TFBS-Finder постоянно оказывалась лучшей. Более простые версии, опиравшиеся только на DNABERT или исключавшие один из модулей внимания, явно теряли в точности. Статистические тесты подтвердили, что эти падения производительности не случа́йны, что показывает: сочетание глобального понимания последовательности и тщательно спроектированного внимания к локальным паттернам критично.
Работа в разных типах клеток и превосходство над старыми инструментами
Важный вопрос: может ли модель, обученная в одном биологическом контексте, обобщаться в другом. Авторы сосредоточились на хорошо изученном факторе транскрипции CTCF и обучили TFBS-Finder на данных из одной линий клеток, затем тестировали на других. Во всех комбинациях модель показала высокие результаты, что говорит о том, что она захватывает ключевые особенности связывания CTCF, общие для разных тканей. В сравнении с девятью ведущими методами, включая более ранние глубокие и BERT-основанные модели, TFBS-Finder продемонстрировал более высокую среднюю точность и дал более надежные ранжирования сайтов связывания. Модель также работала немного быстрее и использовала меньше памяти, чем наиболее похожая предшествующая модель, что указывает на то, что лучшая производительность не требовала более тяжёлых вычислений.
Визуализация того, чему модель научилась
Сложные ИИ-системы часто критикуют как «чёрные ящики». Здесь исследователи попытались приоткрыть этот ящик, визуализируя, какие позиции в ДНК сильнее всего влияли на решения TFBS-Finder. Для двух факторов транскрипции с хорошо известными мотивами, CEBPB и GATA3, они сгенерировали оценочные важности вдоль последовательности и сгруппировали самые сильные сигналы в консенсусные паттерны. Полученные мотивы тесно совпали с опорными мотивами из признанных баз данных, а предсказанные регионы связывания пересекались с независимо обнаруженными экземплярами мотивов. Это говорит о том, что TFBS-Finder не просто запоминает примеры, а выучил биологически значимые правила распознавания ДНК факторами транскрипции.
Что это значит для генетики и медицины
TFBS-Finder предлагает более точный и интерпретируемый способ картирования «переключателей управления», встроенных в нашу ДНК. Определяя места, где факторы транскрипции вероятно связываются, модель может помочь исследователям выстраивать сети регуляции генов, приоритизировать варианты в геноме, которые могут нарушать критические контрольные участки, и проектировать более целевые эксперименты. Хотя в текущей работе в качестве отрицательных примеров использовались перемешанные последовательности и внимание сосредоточено только на буквах ДНК, авторы планируют добавить структурную информацию о форме ДНК и исследовать более реалистичные фоновые последовательности. По мере улучшения таких моделей они могут стать мощными помощниками в понимании того, как изменения в некодирующей ДНК влияют на развитие, эволюцию и риск заболеваний.
Цитирование: Dutta, P., Ghosh, N. & Santoni, D. A DNABERT based deep learning framework for predicting transcription factor binding sites. Sci Rep 16, 7018 (2026). https://doi.org/10.1038/s41598-026-37483-1
Ключевые слова: сайты связывания факторов транскрипции, глубокое обучение, DNABERT, регуляция генов, геномика