Clear Sky Science · ru
Улучшение представления медицинских знаний в больших языковых моделях путем оптимизации клинических токенов
Почему важно умнее «читать» медицину
За каждым медицинским ИИ‑ассистентом стоит простое, но критическое умение: как он разрезает текст на кусочки, которые может понять. Когда эта «нарезка» идет неправильно — особенно для сложных китайских медицинских терминов — ИИ может упустить ключевые идеи в записях врачей или в вопросах пациентов. В этой работе показано, как небольшое, но целенаправленное изменение этого первого шага может сделать большие языковые модели лучше в чтении, рассуждении и ответах на вопросы по китайским медицинским данным, не создавая полностью новую систему с нуля.
Правильный способ разбивать текст на части
Современные языковые модели не читают символы или слова напрямую; сначала они преобразуют текст в короткие единицы, называемые токенами. Для английского языка это работает достаточно хорошо, потому что пробелы уже отмечают границы слов. С китайским сложнее: пробелов нет, а многие медицинские выражения — длинные специализированные фразы. Стандартные токенизаторы, разработанные в основном для английского, склонны резать эти фразы на множество произвольных фрагментов. Когда модель видит название болезни или лабораторного теста, разделенное на несколько разрозненных частей, ей труднее усвоить, что действительно означает этот термин, и её ответы на медицинские вопросы могут становиться расплывчатыми или неточными.
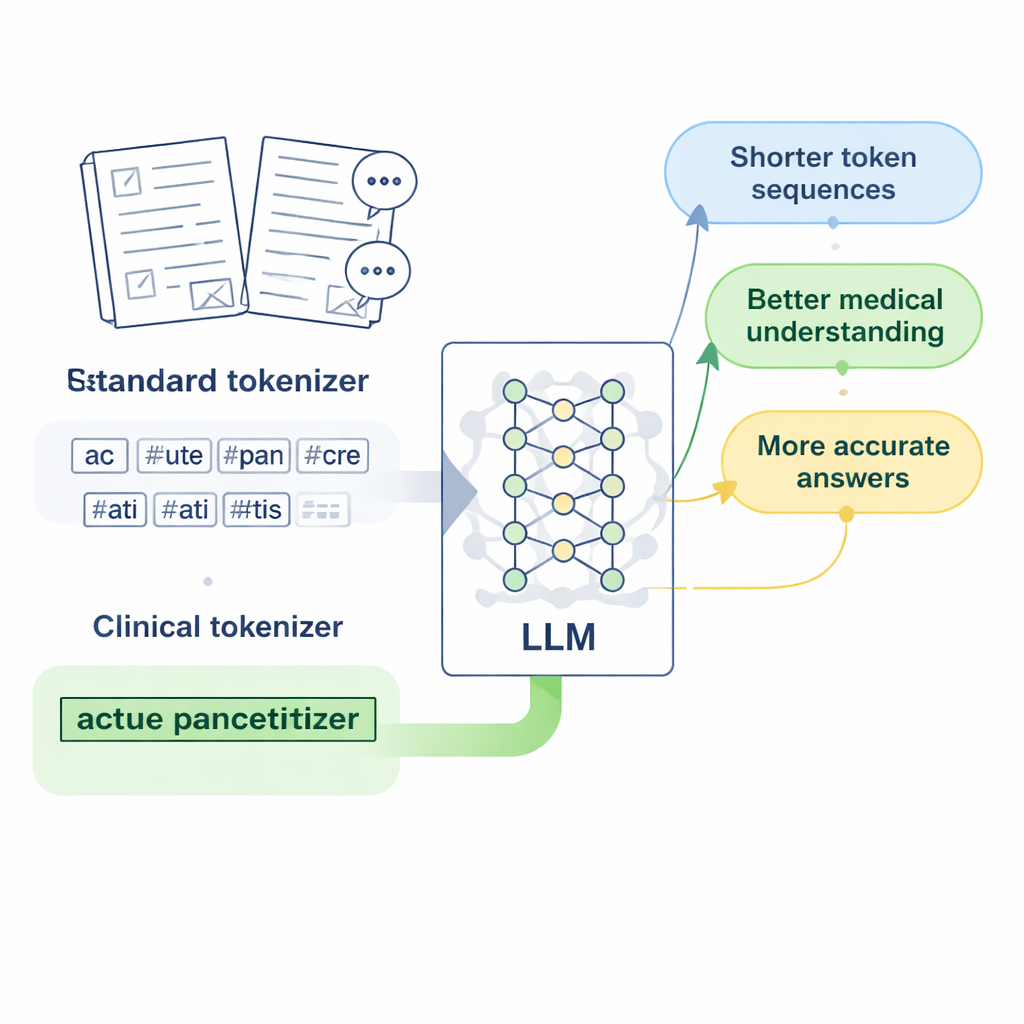
Проектирование «клинических токенов» для китайской медицины
Исследователи сосредотачиваются на LLaMA2, популярной открытой большой языковой модели, и задают вопрос: что если просто научить её токенизатор более богатому медицинскому словарю? Они собирают крупные корпуса китайских медицинских текстов, включая отредактированные базы данных традиционной китайской медицины, тысячи клинических записей и пары вопросов-ответов врач–пациент. Используя байтовую версию алгоритма Byte Pair Encoding, реализованную в инструменте SentencePiece, они обучают новый токенизатор, который учится сохранять распространённые медицинские выражения в виде единых элементов. Эти новые единицы, которые авторы называют «клиническими токенами», затем встраиваются в исходный словарь LLaMA2, расширяя его для лучшего покрытия китайской медицинской лексики без отбрасывания уже имеющихся знаний модели.
От лучших токенов к лучшей медицинской модели
Добавление новых токенов — лишь первый шаг; модель должна научиться хорошим представлениям для них. Команда адаптирует внутренний слой эмбеддингов LLaMA2, чтобы он мог хранить векторы для расширенного словаря, и тестирует два способа инициализации этих новых векторов. Один метод усредняет векторы старых подпроизведений каждого слова, другой использует осторожно масштабированные случайные значения. Парадоксально, но случайный метод показывает лучшие результаты, вероятно потому, что он предотвращает закрепление модели на плохой начальной гипотезе о значении термина. Авторы затем продолжают обучение модели на медицинских текстах и дообучают её на вопросах‑ответах в стиле инструкций с помощью ресурсоэффективного метода LoRA, получая специализированную версию, которую они называют Medical‑LLaMA.
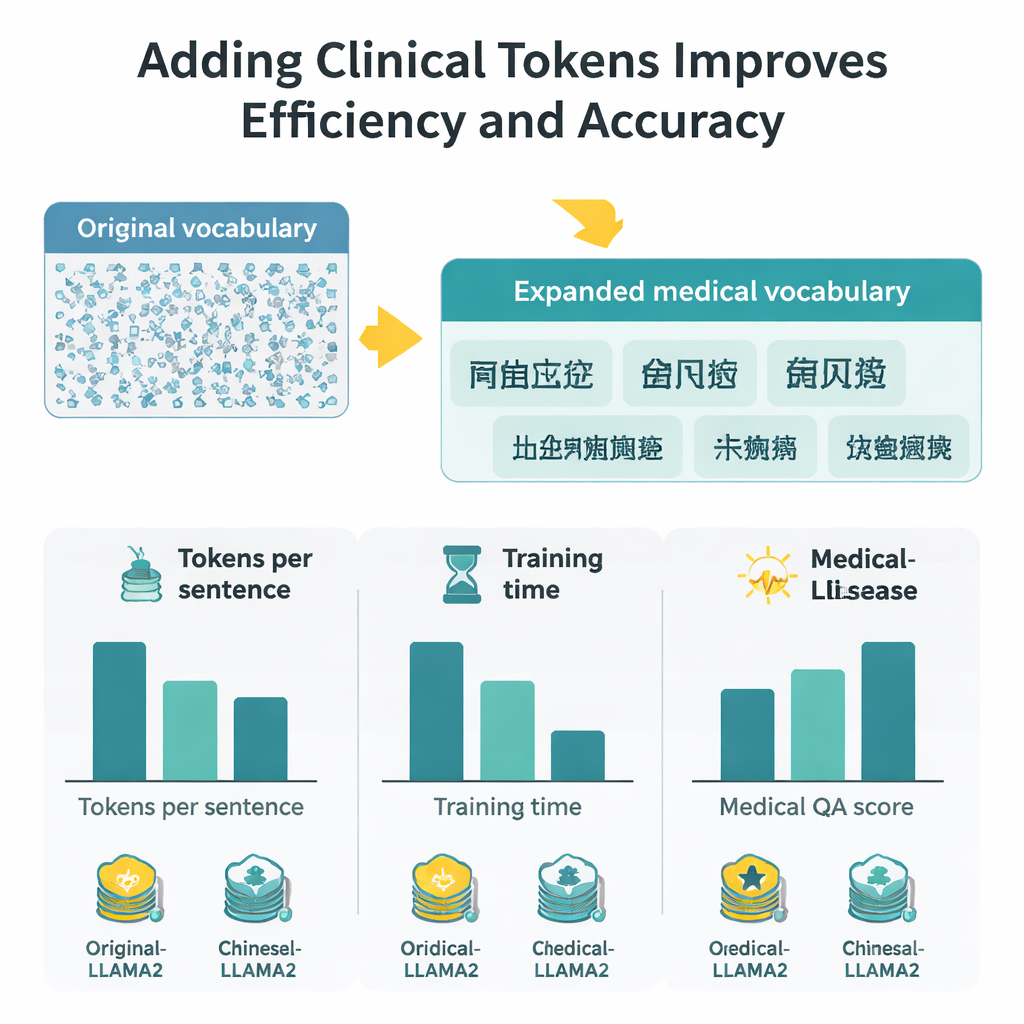
Измерение прироста в скорости, контексте и точности
С расширенным словарем каждому китайскому символу теперь требуется примерно в два раза меньше токенов, чем раньше, что означает, что модель может обрабатывать более длинные фрагменты в том же фиксированном окне токенов. На практике эффективная длина контекста для китайского примерно удваивается, а время дообучения на большом наборе медицинских вопросов‑ответов сокращается почти вдвое. Чтобы оценить качество ответов, авторы комбинируют две стратегии оценки: BERTScore, который измеряет семантическую близость сгенерированного ответа к эталону, и сложную рейтинговую модель (DeepSeek‑R1), оценивающую релевантность, точность, полноту и плавность. По этим метрикам Medical‑LLaMA последовательно превосходит как исходную LLaMA2, так и вариант, оптимизированный для китайского, но не включавший медицинские токены. Она также демонстрирует небольшие, но стабильные улучшения в смежных задачах — распознавании медицинских сущностей и классификации клинических текстов — при сохранении производительности по общим, немедицинским вопросам.
Что это значит для будущих медицинских ИИ
Для неспециалистов ключевая мысль в том, что «очки для чтения» ИИ — в данном случае лучший способ разбиения медицинского языка — могут заметно улучшить, насколько хорошо он понимает и отвечает на вопросы о здоровье. Вставляя хорошо подобранные клинические токены в словарь существующей модели, авторы повышают как эффективность, так и точность без необходимости больших новых тренировок или полностью новых архитектур. Хотя работа ограничивается моделью с 7 миллиардами параметров и китайскими медицинскими текстами, она указывает на практический рецепт: адаптировать самый ранний уровень обработки языка под конкретную область, затем выполнить лёгкое дообучение. Эта стратегия может помочь будущим медицинским ИИ‑инструментам стать более надежными партнёрами для клиницистов и пациентов, особенно в языках и специализациях, которые стандартным моделям даются труднее.
Цитирование: Li, Q., Tong, J., Liu, S. et al. Medical knowledge representation enhancement in large language models through clinical tokens optimization. Sci Rep 16, 6563 (2026). https://doi.org/10.1038/s41598-026-37438-6
Ключевые слова: медицинские языковые модели, китайские клинические тексты, токенизация, клинический словарь, медицинские ответы на вопросы