Clear Sky Science · ru
AE-LFOG-YOLO: надежное обнаружение защитных касок с помощью адаптивных анкоров и обучения, инвариантного к освещению
Почему проверки касок важны
На крупных строительных объектах и в подземных тоннелях простая защитная каска может означать разницу между спасённым случаем и травмой, меняющей жизнь. Однако в хаосе реальных площадок люди забывают или пренебрегают ношением касок, а человеческим инспекторам невозможно наблюдать за каждым уголком постоянно. В этом исследовании рассматривается, как создать автоматизированную систему видеонаблюдения, которая надёжно определяет, кто носит каску, а кто — нет, даже когда в тоннеле тускло, изображение засвечено лампами или на кадре много рабочих на разных расстояниях от камеры.
Задачи видения в суровом тоннельном освещении
Строительные площадки в тоннелях — визуально экстремальные места. Яркие прожекторы создают блики, а глубокие тёмные зоны скрывают детали. Люди движутся к камере и от неё, поэтому каски выглядят на разных масштабах. Стандартные детекторы искусственного интеллекта часто терпят неудачу в таких условиях: они пропускают каски в тёмных участках, принимают за каски другие округлые объекты или испытывают затруднения с очень маленькими и удалёнными рабочими. Многие существующие системы пытаются исправить это путем осветления или очистки изображений перед детекцией либо тонкой настройки некоторых компонентов популярных моделей YOLO. Но поскольку эти шаги обычно добавляются как внешние исправления, а не являются частью единого обучающего процесса, они оставляют потенциал производительности невостребованным и оказываются неустойчивыми при изменении освещения или компоновки сцены.
Новый способ научить камеры не обращать внимания на плохое освещение
Авторы предлагают улучшенную систему под названием AE‑LFOG‑YOLO, основанную на широко используемом детекторе YOLOv8. Первая ключевая идея — Модуль, инвариантный к освещению, небольшой блок внутри сети, который учится отделять «то, что делает свет» от «того, как объекты действительно выглядят». Он разделяет входные карты признаков на часть, в которой в основном отражаются закономерности освещения, и часть, фиксирующую более устойчивую форму и текстуру, например изогнутый край каски. С помощью специальных управляющих (гейтинг) операций и ветви, фокусированной на краях и углах, модуль снижает влияние перепадов яркости и подчёркивает стабильную геометрию. Поскольку это происходит внутри детектора, а не в отдельном шаге предобработки, вся система может обучаться сквозным образом, оставаясь сосредоточенной на самих касках, вместо того чтобы сбиваться из‑за пятен блика или тёмных областей.
Позволить модели развивать собственные правила просмотра
Второй основной приём нацелен на то, как детектор предполагает, где могут появиться объекты. Многие детекторы стартуют с фиксированного набора «анкоров» — предложений по вероятным размерам и формам объектов; обычно их выбирают один раз по обучающим данным и больше не меняют. Однако в тоннелях видимый размер каски может резко меняться в зависимости от расстояния до камеры и угла обзора. AE‑LFOG‑YOLO заменяет статические анкоры динамическим процессом, названным Adaptive Evolutionary – Light Field Optimized Generation. В конце каждой эпохи обучения система осторожно изменяет анкоры, оценивает, насколько хорошо они соответствуют реальным каскам всех размеров, и проверяет, соответствуют ли их размеры базовой оптике камеры — насколько большой должна выглядеть настоящая каска на сенсоре при типичных рабочих расстояниях. Наборы анкоров с лучшими оценками «выживают» для следующего раунда. Со временем детектор «эволюционирует» анкоры, которые и подгоняются под данные, и учитывают физику изображения камеры.
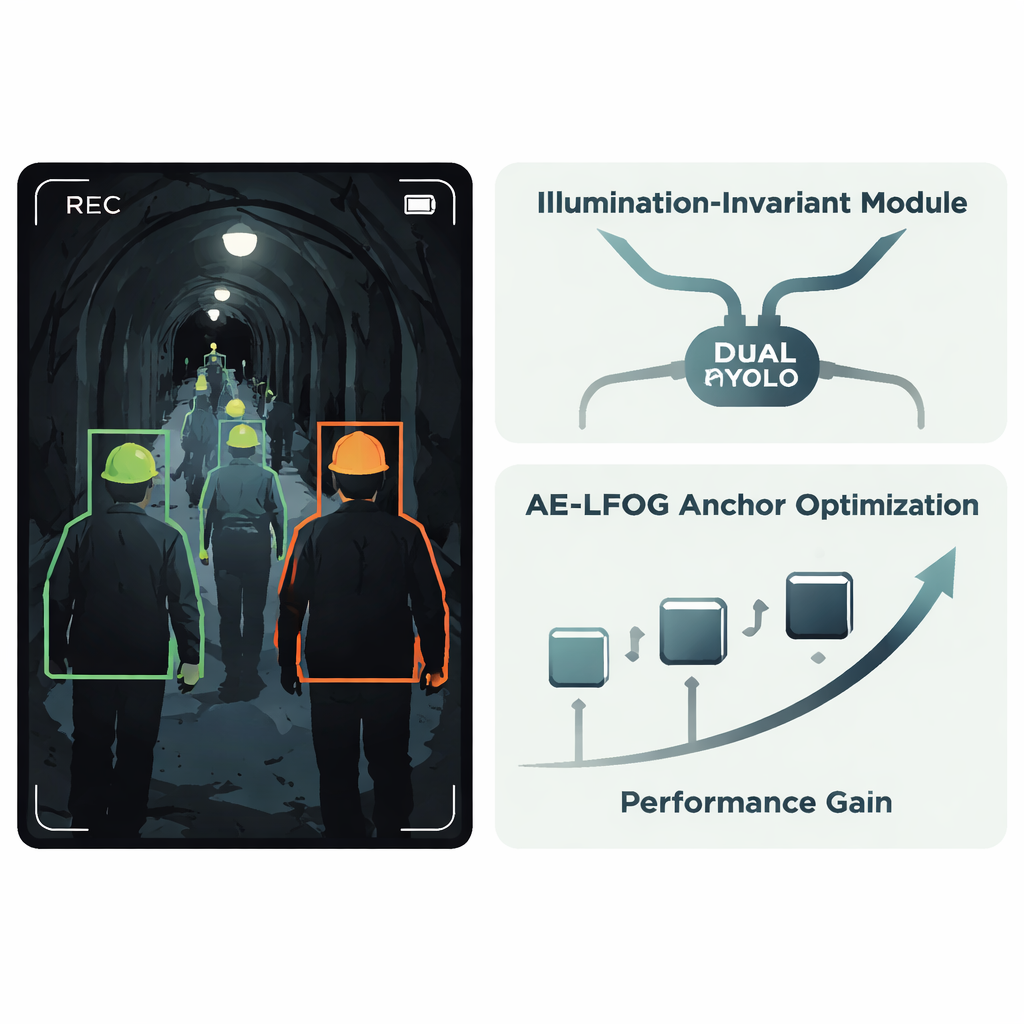
Адаптация обучения к качеству реальных изображений
Помимо изменения того, что модель ищет, авторы также меняют способ её обучения. Они вводят стратегию обучения, которая уделяет больше внимания точному расположению рамки каски, когда качество изображения плохое, и больше — правильной классификации «каска / без каски», когда условия хороши. Физически обоснованный скор, снова выведенный из принципов формирования изображения камерой, говорит системе, насколько надёжны кадры на каждом этапе. Если освещение или фокус плохи, процесс обучения автоматически увеличивает значение правильного определения граничных рамок; если условия улучшаются, вес смещается в сторону классификации. Это создаёт петлю обратной связи, в которой модель постоянно подстраивает собственные приоритеты под физическую среду, с которой ей придётся работать в реальных тоннелях.
Что показывают тесты на практике
Исследователи проверяют свой подход на реальном датасете по обнаружению защитных касок в тоннелях и сравнивают его с несколькими современными методами на основе YOLO. AE‑LFOG‑YOLO обнаруживает каски с очень высокой точностью, правильно идентифицируя около 95 процентов касок при стандартном пороге перекрытия и опережая базовую версию YOLOv8 как по точности, так и по полноте. Модель работает достаточно быстро для использования в реальном времени и особенно хорошо показывает себя при сильных манипуляциях с освещением, имитирующих экстремальную темноту или переэкспозицию. В этих тяжёлых условиях новая модель сохраняет более высокую уверенность, находит больше маленьких и удалённых рабочих и оперирует в диапазоне яркости, который более чем на треть шире, чем у базовой модели, то есть остаётся надёжной в гораздо более широком наборе реальных сцен.
Как это помогает повышать безопасность рабочих
Для неспециалистов вывод прост: обучая систему ИИ понимать не только пиксели, но и физику того, как камеры видят при тяжёлых условиях, эта работа даёт более умного и надёжного наблюдателя на стене тоннеля. AE‑LFOG‑YOLO лучше игнорирует обманчивое освещение и адаптируется к меняющимся видам, снижая число пропущенных обнаружений и ложных тревог. Развернутая в течение нескольких месяцев на действующей линии электрифицированного рельсового транспорта, система уже показала, что может помогать службам безопасности следить за соблюдением ношения касок рабочими, представляя практический шаг к более безопасным и более контролируемым строительным площадкам.
Цитирование: Liu, S., Wang, J. AE-LFOG-YOLO: robust safety helmet detection via adaptive anchors and illumination invariant learning. Sci Rep 16, 6402 (2026). https://doi.org/10.1038/s41598-026-37326-z
Ключевые слова: обнаружение защитных касок, строительство тоннелей, компьютерное зрение, съёмка при низкой освещённости, YOLOv8