Clear Sky Science · ru
Оценка эффективности генеративного предобученного трансформера на Национальном экзамене на получение ветеринарной лицензии в Японии
Почему умные ветеринарные экзамены важны для всех
За каждым визитом в ветеринарную клинику стоят годы строгой подготовки и один высокий рискованный национальный экзамен. В Японии будущие ветеринары должны сдать Национальный экзамен на получение ветеринарной лицензии (NVLE), который проверяет всё — от базовой биологии до сложного клинического мышления. В этом исследовании поставлен своевременный вопрос: смогут ли современные продвинутые языковые модели ИИ, те самые, что используются в популярных чат‑ботах, решить этот требовательный экзамен на японском — и что это может означать для ветеринарного образования и ухода за животными?
Тестирование ИИ на реальном ветеринарном лицензионном экзамене
Исследователи сосредоточились на трёх поколениях моделей большого языка компании OpenAI: GPT‑4o, o1 и o3. Эти системы предназначены для чтения и генерации текста, похожего на человеческий, но они никогда не обучались специально ветеринарной медицине. Чтобы проверить их, команда использовала 74‑й NVLE (2023) как эталон. Экзамен разделён на пять разделов, включая текстовые вопросы и вопросы с изображениями — рентгенами, фотографиями или схемами. Все вопросы — множественного выбора с пятью вариантами, как и на реальном экзамене студентов. Моделям подавали каждый вопрос через стандартизированный компьютерный скрипт, и они должны были отвечать только номером выбранного варианта, без возможности «объяснить» или каким‑то образом аргументировать ответ.
Какая модель ИИ оказалась лучшей?
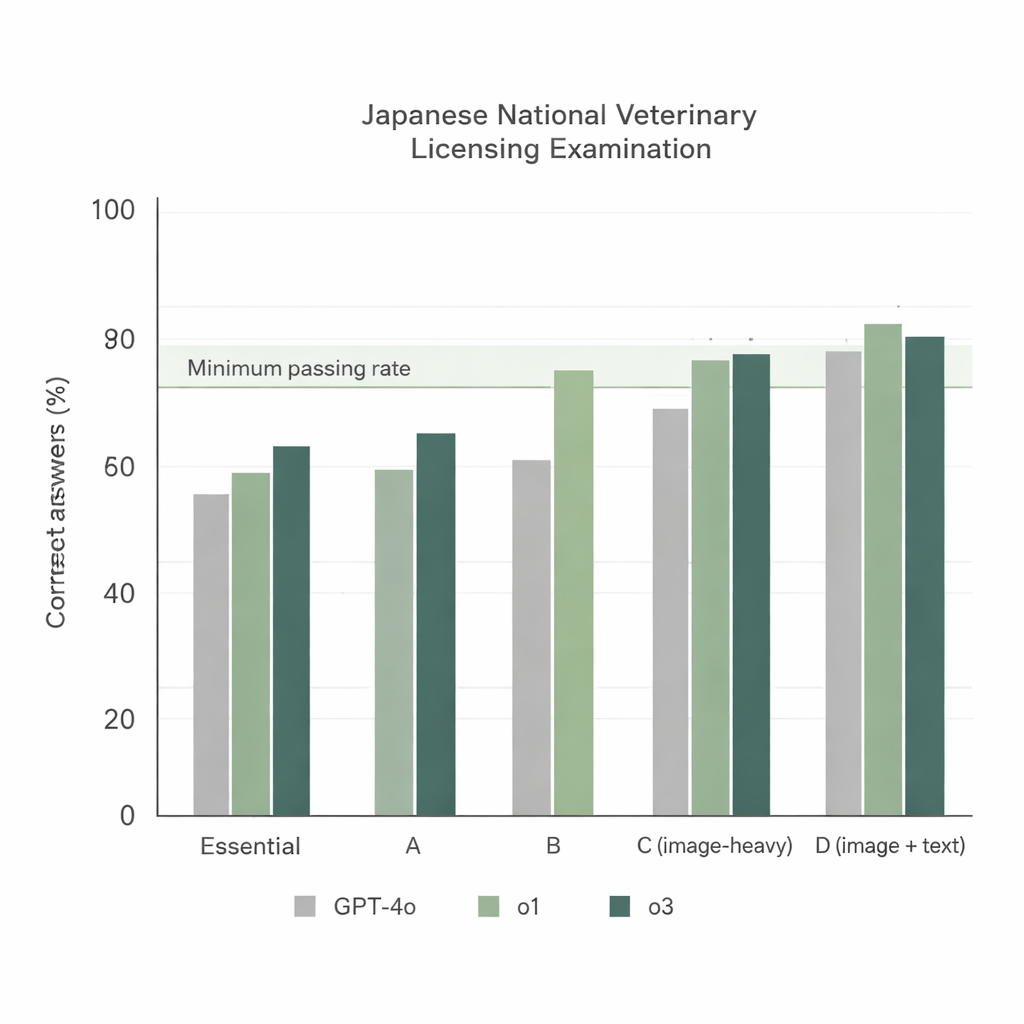
Когда три модели решали 74‑й NVLE в самой простой конфигурации — вопросы на японском и простой инструктивный промпт — выявились два очевидных тренда. Во‑первых, все модели хорошо справлялись с текстовыми разделами, но o1 и o3 последовательно опережали GPT‑4o. Во‑вторых, результаты падали в разделах с большим количеством изображений, однако o1 и o3 всё ещё превышали официальную минимальную проходную норму, тогда как GPT‑4o не дотянул в одном из таких разделов. В целом GPT‑4o правильно ответил примерно на 78 % вопросов, o1 достиг около 92 %, а o3 — около 93 %. Поскольку o3 немного превзошла o1 по суммарному баллу, исследователи выбрали o3 для оставшейся части экспериментов.
Помогают ли промпты или перевод?
Много говорится о «промпт‑инжиниринге» — составлении сложных инструкций, чтобы выжать от ИИ лучшие ответы, — а также о переводе локальных экзаменационных вопросов на английский, чтобы согласовать их с данными обучения моделей. В исследовании эти идеи прямо протестировали на модели o3, сравнив базовый решающий промпт с более детализированным оптимизированным промптом, а также японские вопросы и их версии, сначала переведённые той же моделью на английский. Удивительно, но ни одна из этих модификаций не дала существенной разницы: o3 уверенно прошла при всех шести комбинациях, и самый простой подход (оригинальный японский текст с базовым промптом) работал так же хорошо, как и более сложные настройки. Это говорит о том, что по крайней мере для этих ветеринарных вопросов современные модели уже надёжно понимают японский и не требуют хитрой настройки промптов для высокой эффективности.
Насколько стабильно поведение на более новых экзаменах?
Чтобы проверить, не были ли сильные результаты случайностью, команда далее дала o3 75‑й (2024) и 76‑й (2025) NVLE, снова используя только оригинальные японские вопросы и обычный промпт. Модель набрала общие баллы выше 92 % в обоих экзаменах и превысила проходной порог во всех разделах, включая разделы с большим числом изображений. Большинство вопросов получали одинаковый ответ в трёх независимых запусках, что показывает общую стабильность ответов o3 даже при наличии некоторой рандомности. При тщательном разборе ошибок исследователи обнаружили, что они концентрировались в двух областях: практические ветеринарные знания (например, японское ветеринарное законодательство) и клиническая медицина, которые требуют знание‑специфичных правил и многоэтапного рассуждения, а не простого воспроизведения фактов.
Что это значит — и что не значит
Авторы исследования делают вывод, что передовые модели в стиле GPT теперь способны пройти японский экзамен на ветеринарную лицензию на японском языке, без переводческих уловок или сложных промптов. Для ветеринарных школ и студентов это открывает возможности использовать ИИ как партнёра по обучению, генератор вопросов или объяснитель экзаменационных тем. Для общества это сигнал, что ИИ становится мощным инструментом для организации и распространения ветеринарных знаний. Однако авторы подчёркивают, что эти системы не готовы заменить ветеринаров или самостоятельно принимать медицинские решения. Модели по‑прежнему могут неправильно интерпретировать изображения, испытывать трудности с тонким клиническим суждением и иногда выдумывать факты. При осторожном использовании они могут стать ценными помощниками в ветеринарном образовании и информационной поддержке — но ответственность за здоровье животных остаётся за людьми.
Цитирование: Kako, T., Kato, D., Iguchi, T. et al. Performance evaluation of generative pre-trained transformer on the National Veterinary Licensing Examination in Japan. Sci Rep 16, 4306 (2026). https://doi.org/10.1038/s41598-026-37300-9
Ключевые слова: экзамены на ветеринарную лицензию, модели большого языка, искусственный интеллект в медицине, результаты GPT, японское ветеринарное образование