Clear Sky Science · ru
Влияние выбора K в K‑кратной кросс‑валидации на смещение и разброс в моделях контролируемого обучения
Почему проверять модель дважды действительно важно
От медицинской диагностики до оценки кредитоспособности — многие решения сейчас опираются на модели машинного обучения, обученные на прошлых данных. Но как понять, будет ли модель, которая хорошо выглядит на экране, корректно работать на новых, невидимых случаях? Популярный способ «проверить» модели — k‑кратная кросс‑валидация, когда данные многократно разбивают на обучающую и тестовую части. В этом исследовании задают на вид простой, но важный вопрос: сколько частей нужно — насколько большим должен быть k — и как этот выбор незаметно влияет на надежность сообщаемых показателей модели?
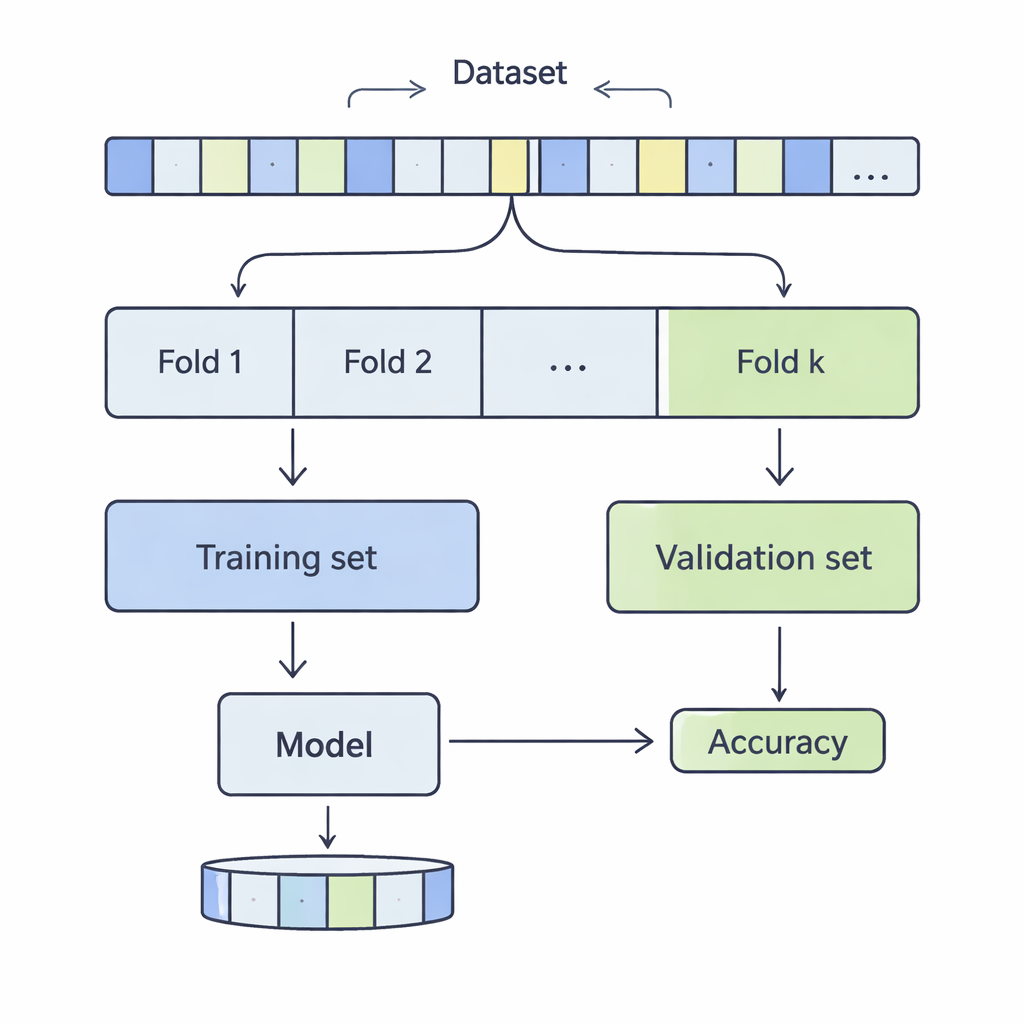
Как режут данные для проверки на практике
В k‑кратной кросс‑валидации набор данных перемешивают и делят на k равных частей, или фолдов. Модель обучают на k‑1 фолдах и оценивают на оставшемся; этот процесс повторяют, пока каждый фолд не побывает в роли тестовой части. Авторы исследовали значения k от 3 до 20 на 12 реальных наборах данных — от нескольких тысяч до более чем полумиллиона записей — охватывающих задачи предсказания дохода, медицинских исходов, кибератак, игр и качества вина. Они применили четыре распространённых метода классификации — опорные векторы (SVM), деревья решений, логистическую регрессию и k‑ближайших соседей — и тщательно измерили, как выбор k влияет на два ключевых аспекта производительности: смещение и разброс.
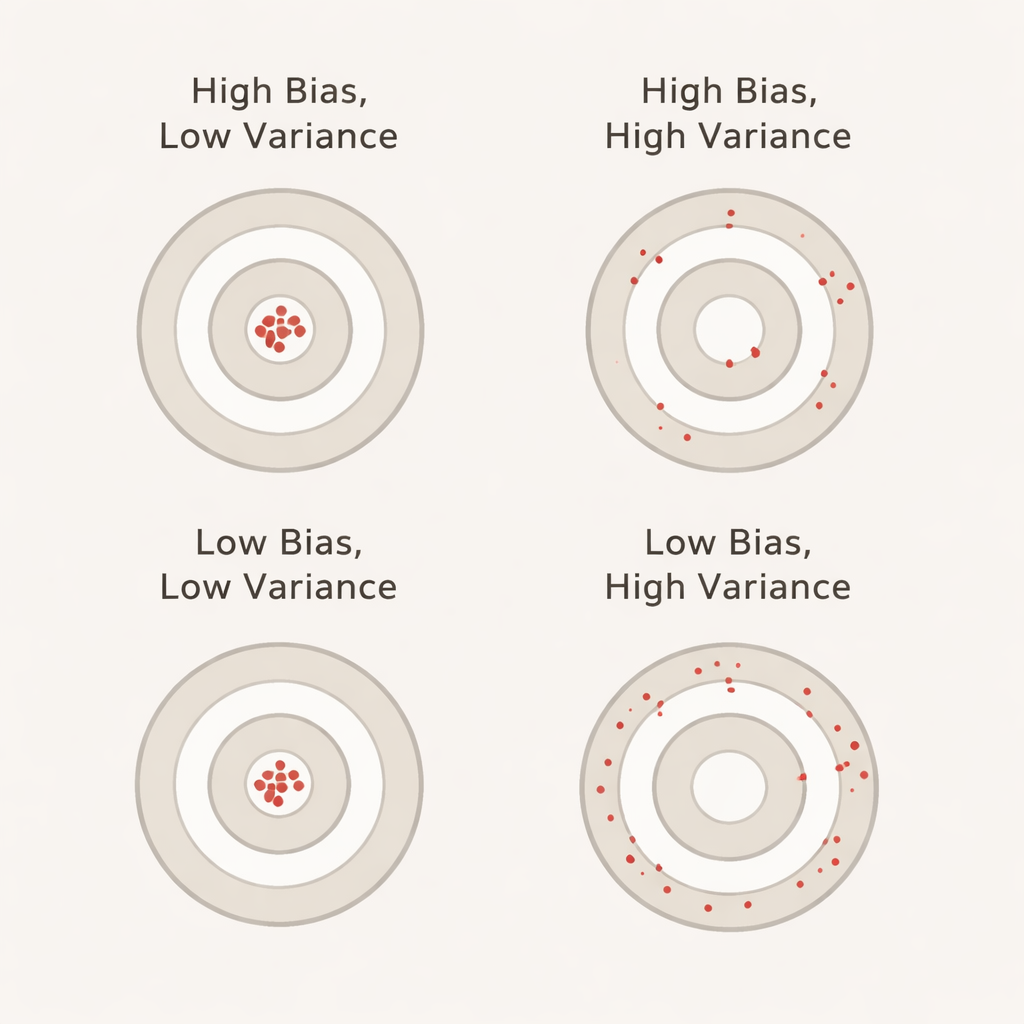
Что означают смещение и разброс простыми словами
В данном контексте смещение отражает, насколько лучше модель кажется при кросс‑валидации по сравнению с её реальной работой на отдельном, невостребованном тестовом наборе. Большое положительное смещение означает, что при валидации модель выглядит чрезмерно оптимистично — как ученик, который блистательно сдаёт тренировочные тесты, но срывается на настоящем экзамене. Разброс показывает, насколько сильно меняется производительность модели от фолда к фолду: низкий разброс означает стабильные показатели на разных разрезах данных, тогда как высокий — большие колебания. Идеально, если и смещение, и разброс малы, тогда заявленная точность будет и реалистичной, и устойчивой.
Что происходит при увеличении числа фолдов
Во всех двенадцати наборах данных и для всех четырёх алгоритмов выделялся один стойкий паттерн: по мере увеличения k разброс почти всегда рос. Проще говоря, использование большего числа фолдов делало сообщаемую точность менее стабильной от фолда к фолду. Это противоречит распространённому мнению, что больше фолдов автоматически даёт лучшие, более надёжные оценки. Объяснение в том, что при большом k каждая валидационная часть становится очень маленькой и менее представительнoй, поэтому результаты сильнее зависят от случайных особенностей данных. При этом поведение смещения было менее однозначным. Для k‑ближайших соседей и опорных векторов смещение, как правило, росло с увеличением k, то есть эти модели часто казались в кросс‑валидации более точными, чем на отложенном тесте. Деревья решений показали примерно сбалансированную картину, а логистическая регрессия оказалась посередине — с переменными, но более умеренными изменениями смещения.
Почему «стандартные настройки» могут вводить в заблуждение
Большинство практических руководств просто советуют использовать пять или десять фолдов, независимо от набора данных или алгоритма обучения. Анализ авторов показывает, что такой универсальный совет может вводить в заблуждение. На некоторых наборах данных и для некоторых моделей большие значения k усиливали чрезмерно оптимистичное впечатление о производительности; при этом на всех наборах увеличение числа фолдов влекло за собой большую вариативность оценок. Это особенно тревожно в областях с высокими ставками, таких как здравоохранение, финансы или инфраструктура, где ложная уверенность в точности модели может иметь реальные последствия. Исследование утверждает, что эффект от выбора k зависит как от свойств данных (малые vs большие, шумные vs более чистые), так и от того, как конкретный алгоритм обучается на повторяющихся, почти идентичных обучающих выборках.
Главный вывод для всех, кто использует машинное обучение
Ключевой урок в том, что число фолдов в кросс‑валидации — это не безобидная техническая мелочь: оно напрямую формирует степень доверия к вашим числам по точности. В этих экспериментах большее количество фолдов последовательно делало результаты менее стабильными и часто заставляло некоторые модели выглядеть лучше, чем они есть на самом деле. Вместо слепого выбора k=5 или k=10 авторы рекомендуют рассматривать k как настраиваемый параметр: проверяйте, как меняются результаты в небольшом диапазоне значений k и, по возможности, смотрите более чем на одну метрику качества. Для практиков и заинтересованных читателей посыл ясен: при оценке моделей машинного обучения способ, которым вы режете данные, может иметь значение почти столь же большое, как и сама модель.
Цитирование: Abedin, T., Xu, H. & Uddin, S. The impact of K selection in K‑fold cross-validation on bias and variance in supervised learning models. Sci Rep 16, 6084 (2026). https://doi.org/10.1038/s41598-026-37247-x
Ключевые слова: k‑fold cross‑validation, компромисс смещение‑разброс, оценка модели, валидация машинного обучения, контролируемая классификация