Clear Sky Science · ru
Сравнительный анализ контролируемых и ансамблевых моделей с неконтролируемым исследованием для прогнозирования болезни Альцгеймера
Почему раннее предупреждение важно
Болезнь Альцгеймера постепенно лишает людей памяти и самостоятельности, часто задолго до постановки окончательного диагноза. Семьям, врачам и системам здравоохранения выгодно обнаруживать ранние признаки — именно тогда лечение, планирование и поддержка могут оказать наибольшее влияние. В этом исследовании поставлен практический вопрос: могут ли тщательно разработанные компьютерные программы, обученные на рутинных клинических данных и данных МРТ, выявлять деменцию надежнее, чем стандартные сегодня инструменты, и одновременно выявлять скрытые закономерности в развитии болезни?
Преобразование медицинских записей в пригодные для анализа сигналы
Исследователи использовали известный набор данных OASIS-2, в котором наблюдали 150 пожилых людей в возрасте от 60 до 96 лет в течение нескольких лет. Для каждого визита набор содержит базовую информацию, такую как возраст, годы образования и социально-экономический статус, а также результаты когнитивных тестов и показатели, полученные из МРТ, например общий объем мозга. Прежде чем делать прогнозы, команда очистила данные, удалив идентификаторы и неоднозначные случаи, заполнила небольшое количество пропущенных значений и привела все числовые измерения к единой шкале. Они также решили важную практическую задачу: в наборе было гораздо больше здоровых людей, чем пациентов с деменцией. Чтобы модели не ограничивались угадыванием «без деменции» большую часть времени, исследователи применили схемы взвешивания, при которых ошибки на меньшей группе пациентов с деменцией в ходе обучения учитываются сильнее.
Сравнение классических методов с ансамблями моделей
На подготовленном наборе данных авторы сопоставили знакомые методы машинного обучения и более продвинутые «ансамбли», которые объединяют несколько моделей в один более мощный предсказатель. Классическая группа включала логистическую регрессию, деревья решений, метод опорных векторов и случайные леса. В ансамблевой группе были AdaBoost, XGBoost и модель простого большинства, объединяющая три настроенных классификатора. Все модели обучали на одной части данных и тестировали на отложенных примерах; качество оценивали по точности (accuracy), способности правильно отмечать больных деменцией (recall) и площади под ROC-кривой — сводной метрике разделения здоровых и больных. 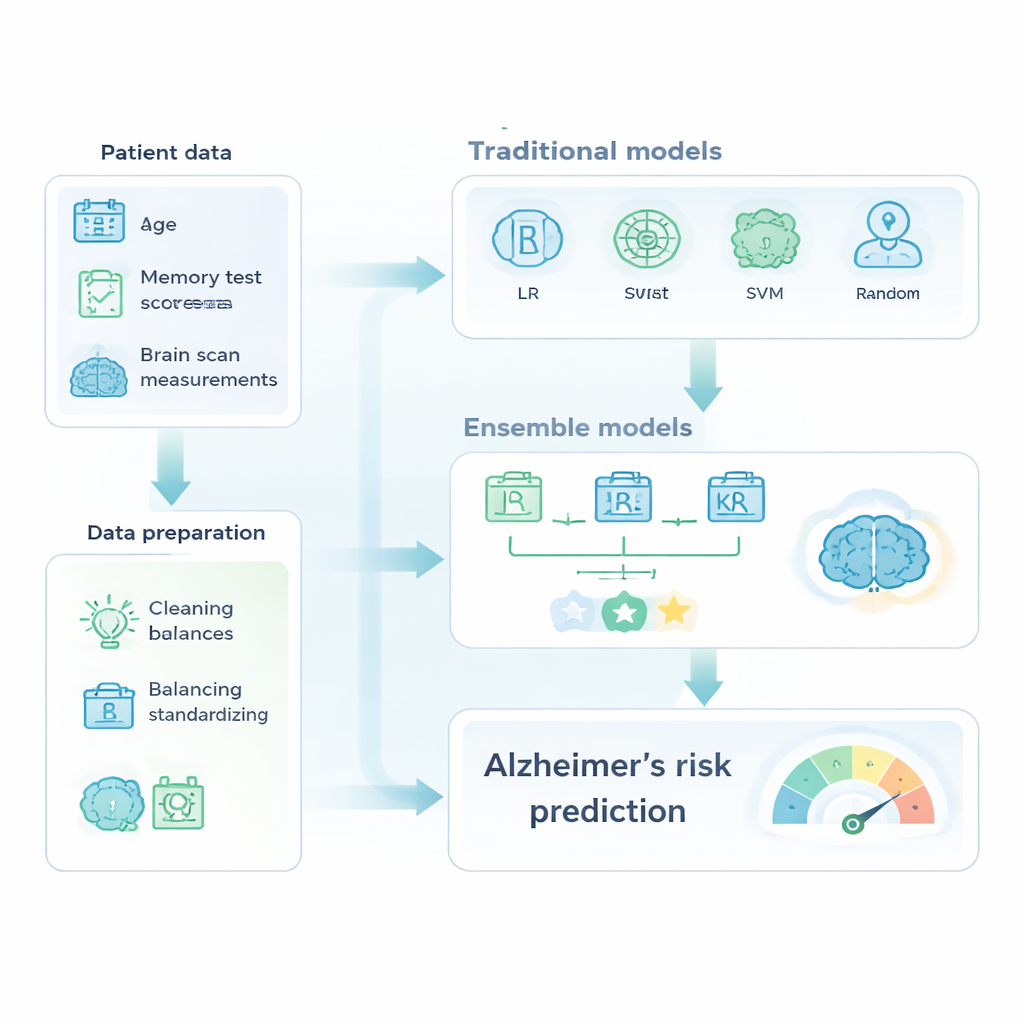
Когда несколько умов лучше одного
Результаты очного сравнения были однозначны. Хотя лучшие традиционные методы работали достаточно хорошо, их эффективность стабилизировалась на уровне, отмеченном в предыдущих исследованиях, — с точностью в низком‑среднем диапазоне 80 процентов. В то же время ансамбль большинства достиг около 95 процентов точности и аналогично высокого ROC-показателя, превзойдя часто цитируемый ориентир в 92 процента. AdaBoost и другие ансамблевые модели также показали результаты лучше, чем любая отдельная традиционная модель. Это преимущество объясняется тем, что разные алгоритмы улавливают разные аспекты данных; давая им «голосовать», ансамбль сглаживает индивидуальные особенности и переобучение, что приводит к более стабильным предсказаниям. Цена такого выигрыша — уменьшенная прозрачность: сложнее быстро понять, почему ансамбль принял то или иное решение по сравнению с простой регрессией или одиночным деревом. 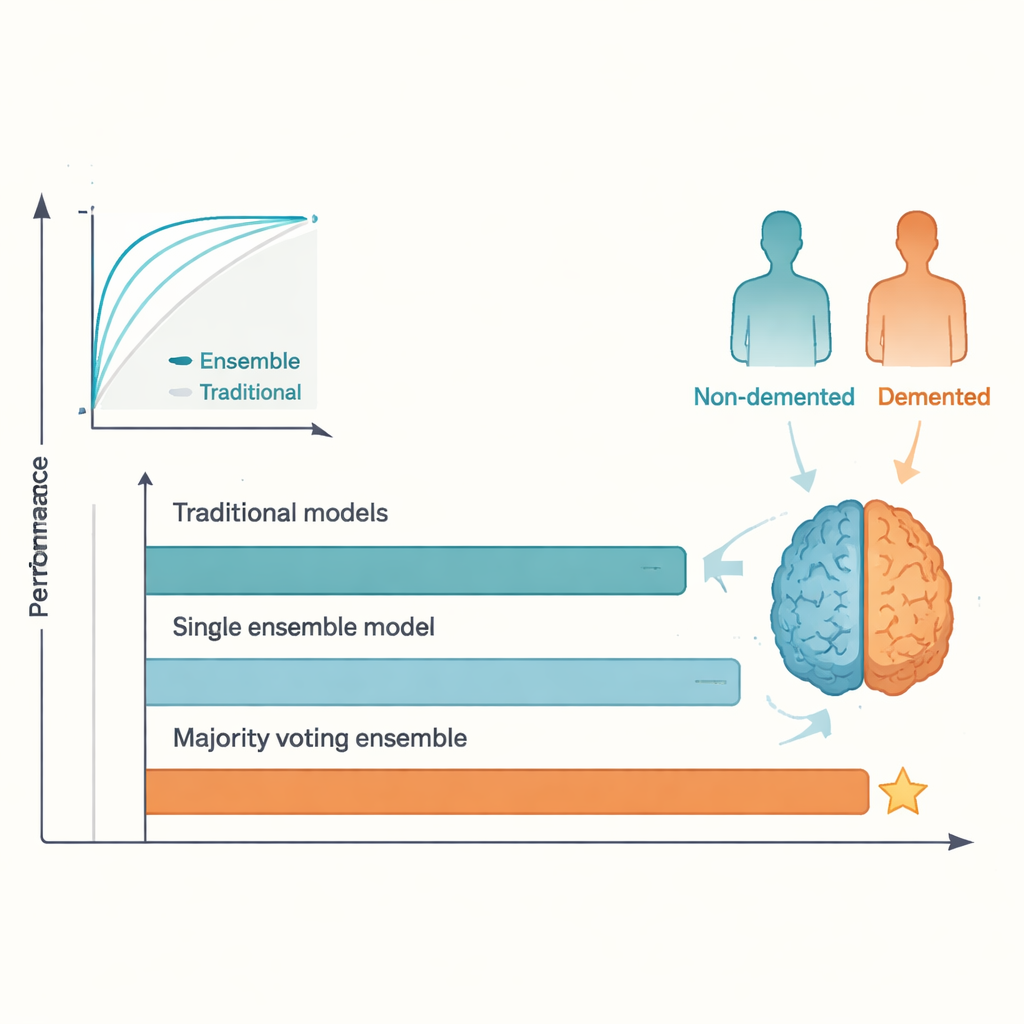
Поиск естественных группировок в данных
Помимо вопроса «кто болен», исследователи также интересовались, как пациенты естественным образом группируются независимо от клинических меток. Для этого они преобразовали все непрерывные переменные в упорядоченные категории — например, диапазоны возраста или объема мозга — и применили метод множественного соответствия для сжатия богатой информации в несколько основных измерений. Затем использовали k‑means для разбиения этих точек на небольшое количество однородных групп. Некоторые кластеры состояли преимущественно из людей с сохранным объемом мозга и нормальными когнитивными показателями, другие включали индивидов с низким объемом мозга, плохими результатами тестов и более тяжелыми рейтингами деменции. То, что неконтролируемые кластеры хорошо совпали с клиническим статусом, указывает на то, что данные несут сильный и согласованный сигнал о риске и прогрессировании болезни.
Что это значит для пациентов и врачей
Вывод для широкого круга читателей прост: при продуманной разработке ансамбли моделей машинного обучения способны выявлять деменцию, связанную с Альцгеймером, в структурированных клинических данных точнее, чем более старые методы, и при этом использовать информацию, которую многие клиники уже собирают. Одновременно разведывательные методы показывают, что люди распределяются по отчетливым профилям здоровья мозга и когнитивных функций, что намекает на разные траектории развития болезни. Хотя исследование ограничено небольшим размером выборки и сложностью интерпретации ансамблевых моделей, оно демонстрирует, что сочетание мощного предсказания и тщательного исследовательского анализа может как улучшить раннюю диагностику, так и углубить понимание того, как развивается болезнь Альцгеймера.
Цитирование: Amr, Y., Gad, W., Leiva, V. et al. Comparative analysis of supervised and ensemble models with unsupervised exploration for alzheimer’s disease prediction. Sci Rep 16, 7322 (2026). https://doi.org/10.1038/s41598-026-37122-9
Ключевые слова: Болезнь Альцгеймера, прогноз деменции, машинное обучение, ансамблевые модели, нейровизуализация