Clear Sky Science · ru
Инновационная временная суммаризация для сложной классификации видео
Почему более умные видеосуммы имеют значение
От камер наблюдения до стриминговых платформ — мир записывает больше видео, чем люди или компьютеры могут удобно обрабатывать. Каждая секунда материала содержит десятки кадров, но многие из них почти одинаковы. В этой статье рассматривается способ сжать длинные ролики до наиболее информативных моментов, чтобы компьютеры могли распознавать действия, такие как готовка, игра в спорт или прогулка с собакой, при этом затрачивая гораздо меньше времени, памяти и энергии. Такие достижения могут помочь перенести мощный анализ видео на повседневные устройства — от домашних роботов до носимых камер.

От бесконечных кадров к ключевым моментам
Традиционные системы классификации видео пытаются распознать, что происходит в клипе — например, нарезка овощей или бросок мяча — пропуская длинные последовательности кадров через тяжёлые модели глубокого обучения. Эти модели должны учитывать как внешний вид (как всё выглядит), так и временную структуру (как объекты движутся во времени). Обработка всех кадров приводит к большим объёмам данных, повышенным требованиям к хранению и медленным, энергозатратным вычислениям. Авторы утверждают, что многие кадры избыточны: если между соседними кадрами ничего существенного не меняется, анализ обоих даёт мало новой информации. Центральная идея статьи — выделить гораздо меньший набор «ключевых кадров», который по-прежнему фиксирует важные изменения в сцене.
Измерение изменений между кадрами
Чтобы найти эти ключевые моменты, исследователи разрабатывают и сравнивают несколько способов измерения того, насколько один кадр отличается от другого. Вместо того чтобы полагаться только на классическое евклидово расстояние, которое равномерно сравнивает все пиксели, они пробуют альтернативы, более чувствительные к структурным изменениям. Их основное предложение, названное «норма строк» (Norm of Rows), фокусируется на наибольшем различии в каждой строке пикселей и затем берёт наиболее выраженную строку как меру изменения между двумя кадрами. Они также изучают расстояния, основанные на столбцах, и методы, опирающиеся на собственные значения матриц, суммирующих распределение разниц пикселей. Все эти подходы направлены на более надёжное обнаружение значимого движения или смены сцены, например, когда рука тянется за прибором или игрок подпрыгивает.
Как работает конвейер суммаризации
Процесс суммаризации начинается с самого первого кадра видео, который рассматривается как начальный ключевой кадр. Система затем сравнивает этот ключевой кадр с каждым последующим кадром, используя одну из мер расстояния. Когда расстояние превышает выбранный порог, соответствующий кадр помечается как новый ключевой кадр, что указывает на визуально важное изменение. Процедура повторяется с использованием этого нового ключевого кадра в качестве опорного, проходя по видео и собирая цепочку репрезентативных снимков. Корректируя порог, метод может сохранять от 20 до 80 процентов исходных кадров, балансируя между компактностью и детализацией. Полученные суммарные последовательности затем передаются стандартному классификатору глубокого обучения, который сочетает мощную сетевую модель для изображений (ResNet-50) с чувствительным к времени модулем LSTM.
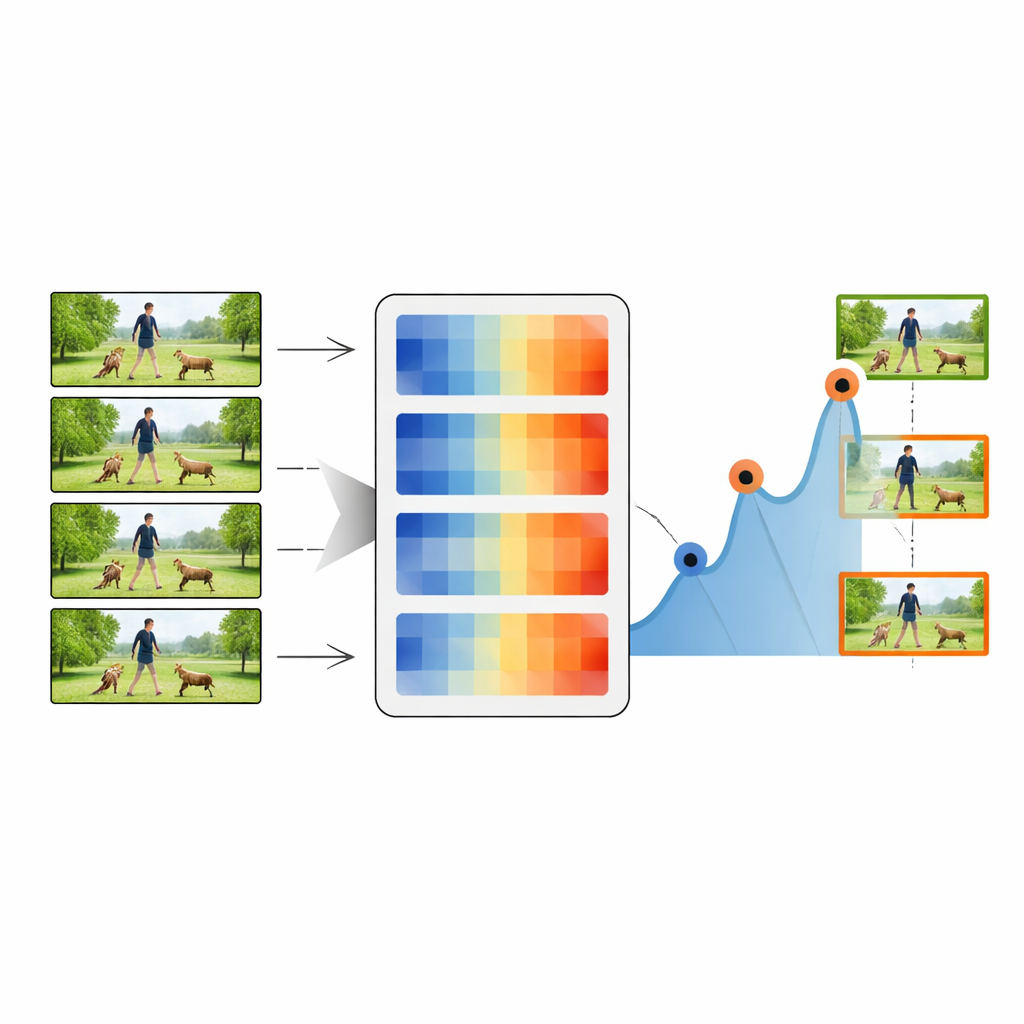
Проверка метода на практике
Авторы тщательно оценивают свой подход на четырёх известных наборах видео: повседневные кухонные действия (MMAC), спортивные и общие действия (UCF101 и UCF11) и более разнообразные, сложные клипы (HMDB51). Во всех этих бенчмарках расстояние Norm of Rows последовательно даёт наилучший баланс скорости и точности. При сохранении примерно половины кадров их система достигает точности классификации свыше 90 процентов на нескольких датасетах — часто сопоставимой или превосходящей более сложные методы, работающие с полными, несуммаризированными видео. Они также измеряют, насколько хорошо суммарии покрывают исходный контент, насколько отобранные кадры избыточны и насколько разнообразны захваченные моменты. Предложённая метрика обеспечивает высокое покрытие при низкой избыточности, то есть сохраняет сюжет видео без повторения похожих кадров.
Более быстрые решения для реального видео
Сократив количество кадров примерно вдвое, метод почти вдвое уменьшает время обработки на стандартном компьютерном оборудовании и даёт заметный прирост скорости даже на современных графических ускорителях. Для реальных систем, которые должны реагировать в реальном времени — например, для видеонаблюдения, автономных роботов или мобильных приложений — такое снижение вычислительной нагрузки критично. Исследование показывает, что тщательно спроектированная мера расстояния может выступать в роли умного фильтра, выбирая, какие кадры заслуживают внимания, а какие можно безопасно пропустить.
Вывод для повседневного использования
Проще говоря, эта работа демонстрирует, что компьютерам не нужно просматривать каждый кадр, чтобы понять, что происходит в видео. Сосредоточившись на моментах настоящих изменений изображения и игнорируя почти идентичные кадры, предложенная техника сохраняет суть действия, значительно сокращая объём данных. Это делает качественное понимание видео более практичным на ограниченном аппаратном обеспечении и открывает путь к более быстрым и эффективным инструментам для анализа растущего потока визуальной информации в нашей повседневной жизни.
Цитирование: Khan, A., Rahnama, A., Islam, A. et al. Innovative temporal summarization for complex video classification. Sci Rep 16, 7970 (2026). https://doi.org/10.1038/s41598-026-37111-y
Ключевые слова: классификация видео, суммаризация видео, выбор ключевых кадров, распознавание действий, эффективность компьютерного зрения