Clear Sky Science · ru
Адаптивный нечеткий кластер‑ориентированный простой, быстрый и эффективный отбор признаков для высокоразмерных и сильно несбалансированных бинарных биоинформатических микрочиповых данных
Почему это важно для исследований генов
Современные тесты экспрессии генов могут измерять десятки тысяч генов в одном образце пациента. Этот поток данных обещает более раннюю диагностику рака и лучшие варианты лечения, но одновременно создаёт проблему: большинство генов дают шумные, избыточные сигналы или связаны преимущественно с распространёнными случаями, а не с редкими и опасными. В статье представлен новый способ просеивания огромных наборов данных экспрессии генов, чтобы компьютеры могли надёжно обнаруживать пациентов из небольшой трудноуловимой группы, используя лишь небольшой, тщательно отобранный набор генов.
Проблема: слишком много схожих генов
В экспериментах с микрочипами часто отслеживают тысячи уровней активности генов при всего нескольких сотнях пациентов. Как правило, один класс (например, распространённый подтип рака) существенно преобладает над другим, что создаёт сильный дисбаланс в данных. В таких условиях многие гены ведут себя похоже, а паттерны для большинства и меньшинства пациентов могут пересекаться. Стандартные методы обучения склонны ориентироваться на класс большинства и путаются из‑за избыточных признаков, что приводит к переобучению и плохому обнаружению редких подтипов. Традиционные методы уменьшения размерности либо теряют интерпретируемость, создавая новые смешанные признаки, либо отбирают гены, не проверяя, насколько они помогают классификатору распознавать случаи меньшинства.
Новая дорожная карта для более умного отбора генов
Авторы предлагают AFCG‑SFE — адаптивную модель отбора признаков, разработанную специально для высокоразмерных несбалансированных данных экспрессии генов. Метод начинается с простого «одиночного» поиска, который включает или исключает гены и проверяет, насколько они поддерживают классификацию, но затем обогащается несколькими шагами, основанными на данных. Сначала гены группируются по схожести поведения, затем разрешается принадлежность генов к нескольким группам, чтобы отразить биологическую реальность, где ген может участвовать в нескольких путях. Внутри каждой группы гены ранжируются по информативности относительно метки заболевания, и сохраняются лишь несколько ключевых представителей, резко сокращая избыточность до начала основного поиска. 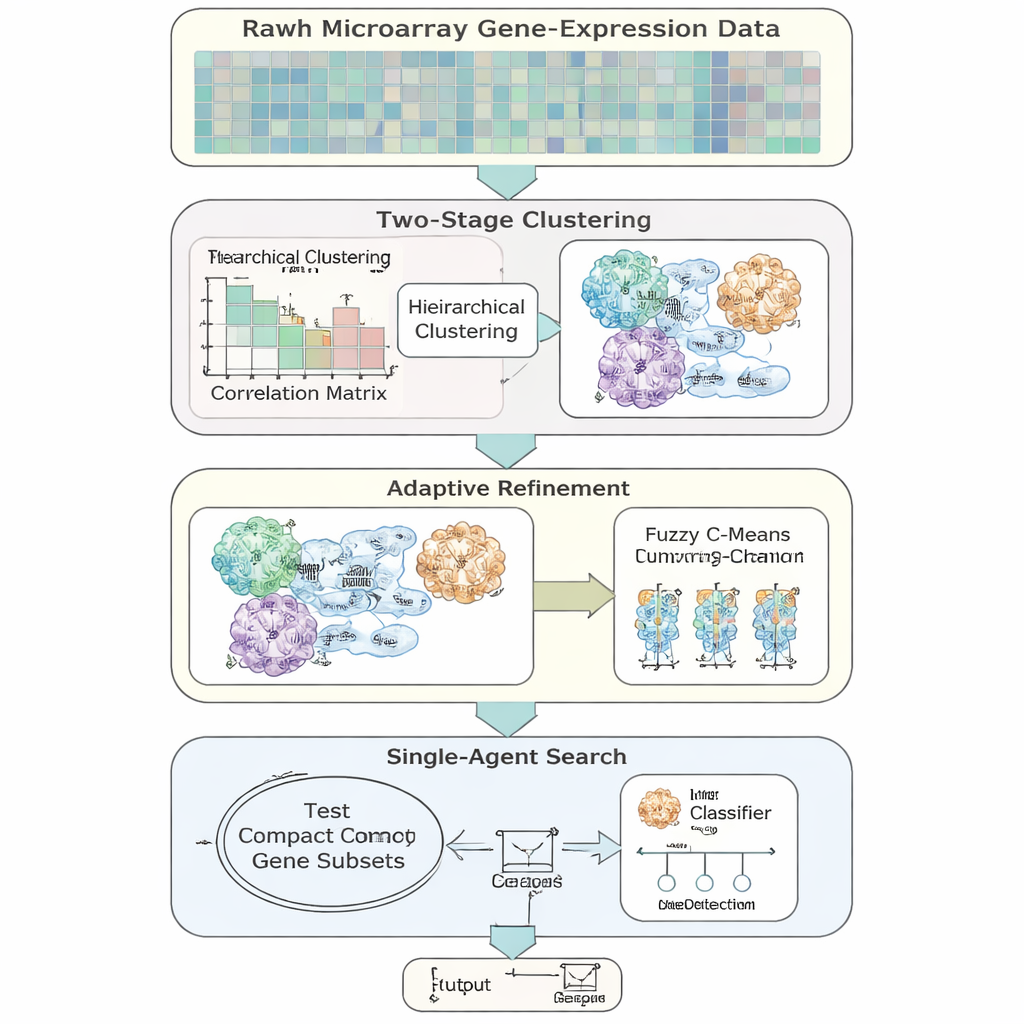
Заставить компьютер учитывать редких пациентов
Вместо простой точности AFCG‑SFE использует функцию приспособленности, которая подчёркивает метрики, подходящие для перекошенных данных, включая баланс между верным распознаванием случаев меньшинства и большинства и показатели по всем порогам принятия решения. Функция приспособленности также включает штрафы за выбор слишком большого числа генов или за множество генов из одного кластера, и вознаграждение за гены, сильно зависимые от метки заболевания. Важно, что сила этих штрафов и вознаграждений автоматически определяется свойствами набора данных — например, сколько генов приходится на пациента и насколько классы перекрываются — а не вручную. Это делает метод более робастным и проще переносимым между исследованиями.
Адаптация к сложности задачи
Ключевая идея заключается в том, что алгоритм не всегда должен стремиться к максимально малому набору генов. Когда два класса трудно отделимы или сильно перекрываются, метод автоматически повышает нижнюю границу числа генов, которые нужно сохранить, гарантируя, что редкие, но важные сигналы не будут отброшены. По мере продвижения поиска AFCG‑SFE постепенно ужесточает ограничение на число генов, которое может сохраниться из каждой группы, при этом соблюдая минимальное требование. В результате получается компактная, разнообразная панель генов, которая отражает структуру данных, не доминируя за счёт одного избыточного паттерна. 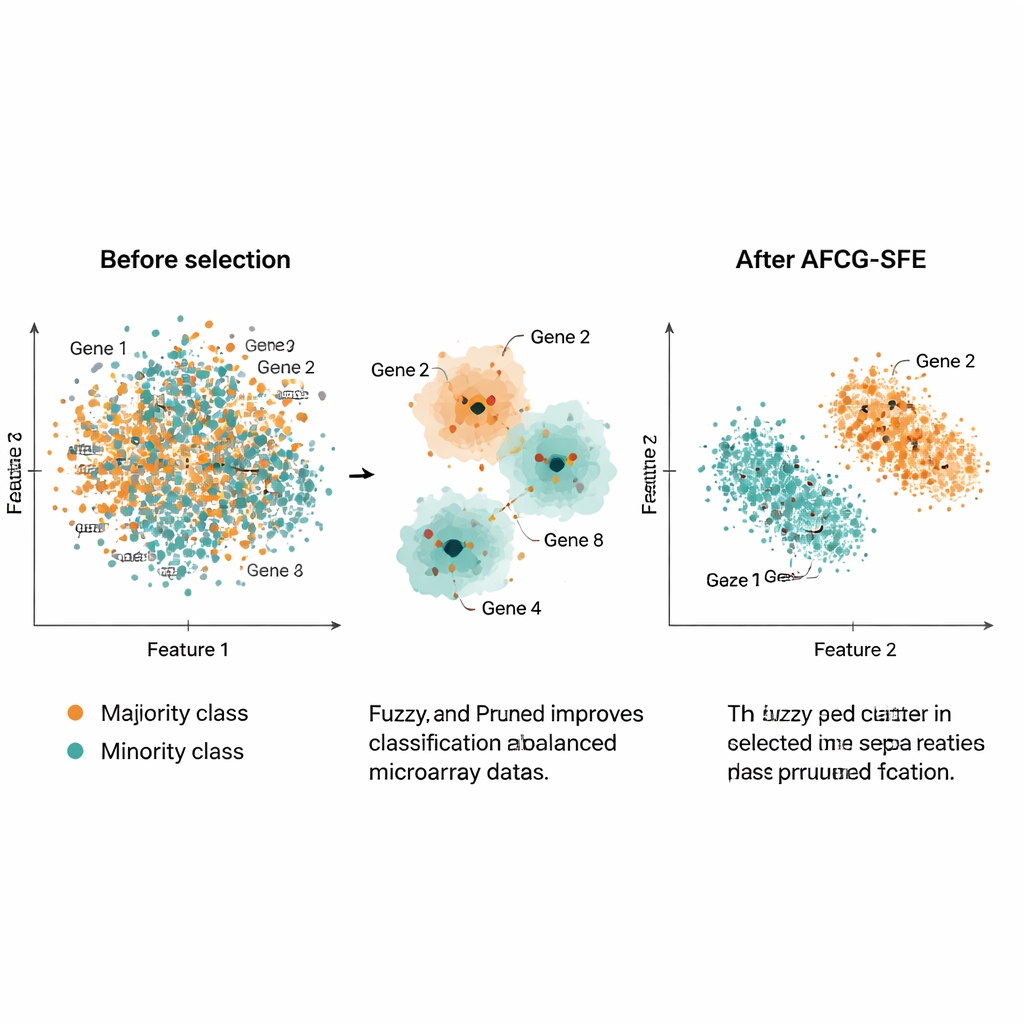
Что показывают эксперименты
Авторы испытали AFCG‑SFE на 20 публичных наборах данных микрочипов по раку, в каждом из которых были тысячи генов, но лишь около 100–200 образцов и сильный дисбаланс классов. Они сравнили свой метод с несколькими базовыми эволюционными поисками, простыми фильтрами и встроенными подходами, которые включают отбор признаков в сам классификатор. По целому ряду показателей — включая F‑меру, сбалансированную точность, площадь под ROC‑кривой и меру переобучения — AFCG‑SFE занял первое место или разделил его на всех наборах данных. Как правило, он выбирал менее 25 генов (часто всего 6–8), устраняя более 99% исходных признаков и при этом улучшая или сохраняя качество классификации. Метод также снизил индекс сложности, отражающий степень перекрытия классов в пространстве признаков, что свидетельствует о более чётком разделении после отбора.
Вывод для неспециалистов
Практически это исследование предлагает способ сжать огромные шумные профили экспрессии генов до очень небольших наборов информативных генов, которые позволяют компьютерам точно распознавать редкие подгруппы пациентов. Благодаря интеллектуальной группировке схожих генов, поощрению тех, что реально связаны с заболеванием, и явной защите от смещения в пользу класса большинства, AFCG‑SFE обеспечивает как лучшую прогнозную способность, так и гораздо более простые панели генов. Такое сочетание помогает исследователям сконцентрироваться на потенциальных биомаркерах, проектировать более интерпретируемые диагностические тесты и в конечном итоге улучшать работу инструментов персонализированной медицины с реальными, несовершенными биологическими данными.
Цитирование: Tye, Y.W., Chew, X., Yusof, U.K. et al. Adaptive fuzzy cluster-guided simple, fast, and efficient feature selection for high-dimensional and highly imbalanced binary-class bioinformatics microarray data. Sci Rep 16, 6650 (2026). https://doi.org/10.1038/s41598-026-37086-w
Ключевые слова: экспрессия генов, отбор признаков, несбалансированные данные, микрочип, подтипы рака